在应用层,关于锁的使用大家应该都很熟悉了,作用就是为了保护共享变量不被同时操作而导致无法预测的情况。然而深入到具体实现,锁仅仅只是锁定临界区吗?
锁的实现其实还必须实现一个语义,也就是内存屏障。内存屏障主要用于防止指令重排而导致的无法预测的情况。代码经过编译器生成的指令并不一定都是按着我们原先的想法来生成的,可能经过优化等情况进行了指令的重排,然而这些重排在执行后的结果应当是一致的。其实及时编译器不重排指令,在现代的cpu中,也常常会将指令乱序执行,所以内存屏障可以保证屏障指令前后的指令顺序。
Memory barrier
Memory barrier 也称为 membar,存储器围栏或栅栏指令,是一种类型的屏障指令,其使得一个中央处理单元(CPU)或 编译器执行的排序上约束存储器之前和屏障指令后发出的操作。 这通常意味着可以保证在屏障之前发布的操作可以在屏障之后发布的操作之前执行。
内存屏障是必需的,因为大多数现代CPU都采用了性能优化,这些性能优化可能导致乱序执行。通常在单个执行线程中不会注意到这种内存操作(装入和存储)的重新排序,但是除非仔细控制,否则可能在并发程序和设备驱动程序中导致不可预测的行为。排序约束的确切性质取决于硬件,并由体系结构的内存排序模型定义。一些体系结构为实施不同的排序约束提供了多个障碍。
当实现在多个设备共享的内存上运行的低级机器代码时,通常使用内存屏障。这样的代码包括多处理器系统上的同步原语和无锁数据结构,以及与计算机硬件进行通信的设备驱动程序。
例子
当程序在单CPU机器上运行时,硬件会执行必要的簿记操作,以确保程序执行时就像所有内存操作都是按照程序员指定的顺序(程序顺序)执行的,因此不需要内存屏障。但是,当内存与多个设备共享时,例如多处理器系统中的其他CPU或内存映射的外围设备,乱序访问可能会影响程序行为。例如,第二个CPU可能会看到第一个CPU以与程序顺序不同的顺序进行内存更改。
下面的两个处理器程序提供了一个示例,说明这种无序执行如何影响程序行为:
最初,内存位置 x 和 f 都保存值0。在#1处理器上运行的程序循环运行,同时的值f为零,然后输出的值x。在处理器#2上运行的程序将值存储42到中x,然后将值存储1到中f。这两个程序片段的伪代码如下所示。该程序的步骤对应于各个处理器指令。
Processor #1:
while (f == 0);
// Memory fence required here
print x;
Processor #2:
x = 42;
// Memory fence required here
f = 1;
可能希望print语句始终打印数字“ 42”。但是,如果处理器#2的存储操作无序执行,则可以在之前f 进行更新,因此print语句可能会打印“ 0”。类似地,处理器#1的加载操作可能会无序执行,并且有可能在进行检查之前先被读取,因此print语句可能再次打印出意外的值。对于大多数程序,这些情况都不可接受。可以在分配处理器#2之前插入一个内存屏障,以确保新的值在值更改时或更改之前对其他处理器可见。可以在处理器#1’之前插入另一个 x x f f x f x 以确保在x看到的值变化之前不读取的值f。
另一个示例是驱动程序执行以下顺序时:
prepare data for a hardware module
// Memory fence required here
trigger the hardware module to process the data
如果不按顺序执行处理器的存储操作,则可能在内存中的数据准备就绪之前触发硬件模块。
对于另一个说明性示例(在实际实践中很少出现的示例),请参阅双重检查锁。
多线程程序通常使用由高级编程环境(例如Java和.NET Framework)或应用程序编程接口(API)(例如POSIX Threads或Windows API)提供的同步原语。提供了诸如互斥量和信号量之类的同步原语,以同步从并行执行线程对资源的访问。通常使用提供预期的内存可见性语义所需的内存屏障来实现这些原语。在这样的环境中,通常不需要显式使用内存屏障。
原则上,每个API或编程环境都有其自己的高级内存模型,该模型定义其内存可见性语义。尽管程序员通常不需要在这样的高级环境中使用内存屏障,但重要的是要尽可能地了解其内存可见性语义。这种理解不一定容易实现,因为内存可见性语义并不总是一致地指定或记录。
内存屏障指令仅在硬件级别解决重排序问题。编译器还可以在程序优化过程中对指令进行重新排序。尽管在两种情况下对并行程序行为的影响可能相似,但通常必须采取单独的措施来禁止编译器对可能由多个执行线程共享的数据进行重新排序优化。请注意,通常仅对于不受同步原语保护的数据(例如上一节中讨论的数据)才需要采取此类措施。
内存屏障也分为读屏障(rmb)与写屏障(wmb)。这些读写屏障主要用于在多核cpu的情形下可以强制同步cpu中缓存不一致的情况。
Cache coherence
在计算机体系结构中,缓存一致性是共享资源数据的统一性,该资源最终存储在多个本地缓存中。当系统中的客户端维护公用内存资源的缓存时,数据不一致可能会引起问题。
假设只有一个cpu,那么cpu只会从自己的缓存中读数据,假如发生了缓存miss,则会从主存中读取数据到缓存中,所以cpu无论在何时看到的最终内存数据都是一致的。
但是在多核情况下,就不是这么简单的了。每个cpu都有自己的缓存,每个cpu最终看到的数据,就是不在缓存中的主存+已在缓存中的数据。所以假设多cpu的情况下,某个cpu更新了某个cache line中的值又没有回写到内存中,那么其它cpu中的数据其实已经是旧的已作废的数据,这是不可接受的。
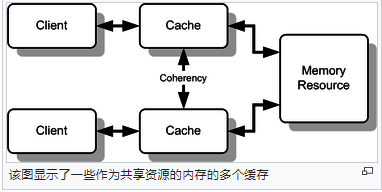
在图中,考虑两个客户端都具有先前读取的特定内存块的缓存副本。假设底部的客户端更新/更改了该内存块,则顶部的客户端可能会留下无效的内存缓存,而没有任何更改通知。缓存一致性旨在通过维护多个缓存中数据值的一致性视图来管理此类冲突。
在一个共享内存多处理器系统中,每个处理器都有一个单独的缓存,可以有很多共享数据副本:一个在主内存中,一个在每个请求它的处理器的本地缓存中。当一个数据副本被更改时,其他副本必须反映该更改。高速缓存一致性是确保共享操作数(数据)值的更改及时在整个系统中传播的准则。
以下是缓存一致性的要求:
- 写传播 Write Propagation
任何高速缓存中的数据更改都必须传播到对等高速缓存中的其他副本(该高速缓存行的副本)。 - 交易序列化 Transaction Serialization
所有处理器必须以相同的顺序看到对单个存储器位置的读/写。
从理论上讲,一致性可以按 load/store粒度执行。但是,实际上,它通常以高速缓存块的粒度执行。
一致性定义了对单个地址位置的读取和写入行为。
在不同的高速缓存中同时出现的一种数据类型称为高速缓存一致性 ,在某些系统中称为全局内存。
为了解决这种情况,引入了缓存一致性协议,其中用的比较多的称为 MESI,分别是cache line可能存在的四种状态:
- Modified。数据已读入cache line,并且已经被修改过了。该cpu拥有最新的数据,可以直接修改数据。当其它核心需要读取相应数据的时候,此数据必须刷入主存。
- Exclusive。数据已读入cache line,并且只有该cpu拥有它。该cpu可以直接修改数据,但是该数据与主存中数据是一致的。
- Shared。多个cpu共享某内存的数据,可能由Exclusive状态改变而来,当某个cpu需要修改数据的时候,必须提交RFO请求来获取数据的独占权,然后才能进行修改。
- Invalid。无效的cache line,和没有载入一样。当某个cpu的cache line处于Shared状态,别的cpu申请写的时候,接收了RFO请求后会变为此种状态。
这四种状态可以不断的改变,有了这套协议,不同的cpu之间的缓存就可以保证数据的一致性了。但是依赖这套协议,会大大的降低性能,比如一个核心上某个Shared的cache line打算写,则必须先RFO来获取独占权,当其它核心确认了之后才能转为Exclusive状态来进行修改,假设其余的核心正在处理别的事情而导致一段时间后才回应,则会当申请RFO的核心处于无事可做的状态,这是不可接受的。
于是在每个cpu中,又加入了两个类似于缓存的东西,分别称为Store buffer 与 Invalidate queue。
Store buffer用于缓存写指令,当cpu需要写cache line的时候,并不会执行上述的流程,而是将写指令丢入Store buffer,当收到其它核心的RFO回应后,该指令才会真正执行。
Invalidate queue用于缓存Shared->Invalid状态的指令,当cpu收到其它核心的RFO指令后,会将自身对应的cache line无效化,但是当核心比较忙的时候,无法立刻处理,所以引入Invalidate queue,当收到RFO指令后,立刻回应,将无效化的指令投入Invalidate queue。
这套机制大大提升了性能,但是很多操作其实也就异步化了,某个cpu写入了东西,则该写入可能只对当前CPU可见(读缓存机制会先读Store buffer,再读缓存),而其余的cpu可能无法感知到内存发生了改变,即使Invalidate queue中已有该无效化指令。
为了解决这个问题,引入了读写屏障。写屏障主要保证在写屏障之前的在Store buffer中的指令都真正的写入了缓存,读屏障主要保证了在读屏障之前所有Invalidate queue中所有的无效化指令都执行。有了读写屏障的配合,那么在不同的核心上,缓存可以得到强同步。
所以在锁的实现上,一般lock都会加入读屏障,保证后续代码可以读到别的cpu核心上的未回写的缓存数据,而unlock都会加入写屏障,将所有的未回写的缓存进行回写。
