exploits globally synchronized counters in single-chip to develop a streamlined GPU coherence protocol.
Synchronized counters enable all coherence transitions,
such as invalidation of cache blocks
to happen synchronously,
eliminating all coherence traffic and protocol races.
present an implementation of TC, called TC-Weak,
eliminates LCC’s trade-off between stalling stores and increasing L1 miss rates
to improve performance and reduce interconnect traffic.
providing coherent L1 caches, TC-Weak improves the performance of GPU applications with inter-workgroup communication by 85% over disabling the non-coherent L1 caches in the baseline GPU.
We also find that write-through protocols outperform a writeback protocol on a GPU
the latter suffers from increased traffic
due to unnecessary refills of write-once data.
1 Introduction
abstracting away the SIMD hardware and
providing the illusion of independent scalar threads executing in parallel.
Traditionally limited to regular parallelism,
recent studies[21, 41] show highly irregular algorithms can attain significant speedups on a GPU.
multi-level cache hierarchy in recent GPUs [6, 44] frees the burden of software managed caches
increases the GPU’s attractiveness as a platform for accelerating applications with irregular memory access patterns [22, 40].
GPUs lack cache一致性 and require disabling private caches if an application requires memory operations to be visible across all cores [6, 44, 45].
These consistency models form the basis of memory models for high-level languages [10, 35] and provide the synchronization primitives employed by multithreaded CPU app
Coherence greatly simplifies supporting well-defined consistency and memory models for high-level languages on GPUs.
It helps enable a unified address space in heterogeneous architectures with single-chip CPU-GPU [11, 26].
This paper focuses on coherence in the GPU cores;
CPU-GPU cache coherence as future work.
Disabling L1 caches provides coherence at the cost of app performance.
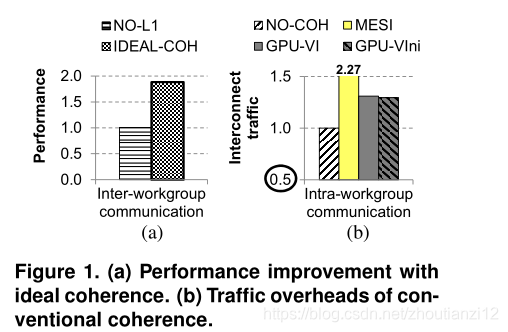
Figure 1(a) shows the potential improvement
contain interworkgroup communication and require coherent L1 caches
Compared to disabling L1 caches,
an ideally coherent GPU ,
where coherence traffic does not incur any latency or traffic costs, improves performance of these applications by 88%
GPUs present three main challenges for coherence.
Figure 1(b) depicts the first of these challenges
comparing the interconnect traffic of
the baseline non-coherent GPU system (NO-COH) to
writeback MESI,
inclusive write-through GPU-VI
non-inclusive write-through GPU-VIni (described in Section 4).
These protocols introduce unnecessary coherence traffic overheads for GPU app
containing data that does not require coherence.
on a GPU, CPU-like worst case sizing [18] would require an impractical amount of storage for tracking thousands of in-flight coherence requests.
existing coherence protocols introduce complexity in the form of transient states and additional message classes.
They require additional virtual networks [58] on GPU interconnects to ensure forward progress, increase power consumption.
tracking a large number of sharers [28, 64] is not a problem for current GPU
only tens of cores.
using a time-based coherence framework
minimizing overheads of GPU coherence
no introducing design complexity.
Traditional coherence protocols rely
explicit message
inform others
when an address needs be invalidated.
describe a time-based coherence framework, TC,
uses synchronized counters to self-invalidate cache blocks
maintain coherence invariants without explicit messages
Existing hardware implements counters synchronized across components [23, Sec- tion 17.12.1] to provide efficient timer services.
Leveraging these counters allows TC to
eliminate coherence traffic,
lower area overheads,
reduce protocol complexity for GPU coherence.
TC requires prediction of cache block lifetimes for self-invalidation.
implements SC on CMPs by stalling writes to cache blocks until they have been self-invalidated by all sharers.
describe one implementation of the TC framework, TC-Strong,similar to LCC.
Section 8.3: TC-Strong poorly on a GPU.
second :TC-Weak, uses a novel timestamp-based memory fence to eliminate stalling of writes.
TC-Weak uses timestamps to drive all consistency operations.
It implements RC [19], enabling full support of C++ and Java memory models [58] on GPUs.
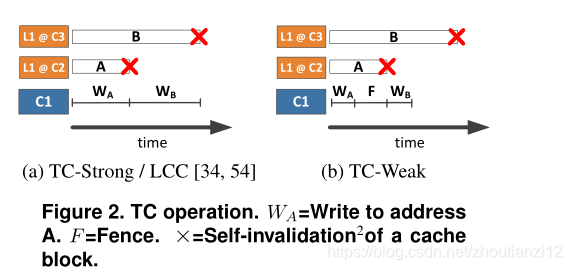
Figure 2 :high-level operation of TC-Strong and TC-Weak.
C2 、C3, addresses A and B cached in private L1
TC-Strong,C1’s write to A stalls completion
until C2 self-invalidates
its locally cached copy of A.
C1’s write to B stalls completion
until C3 self-invalidates
its copy of B.
TC-Weak, C1’s writes to A and B do not stall
waiting for other copies to be self-invalidated.
the fence operation ensures that all previously written addresses have been self-invalidated in other local caches.
This ensures that all previous writes from this core will be globally visible after the fence completes.
challenges of introducing existing coherence protocols to GPUs. introduce two optimizations to a VI protocol [30] to make it more suitable for GPU.
provides detailed complexity and performance evaluations of inclusive and non-inclusive directory protocols on a GPU.
describes Temporal Coherence,
a GPU coherence framework for exploiting synchronous counters in single-chip systems to eliminate coherence traffic and protocol races.
proposes the TC-Weak coherence protocol which employs timestamp based memory fences to implement Release Consistency [19] on a GPU.
proposes a simple lifetime predictor for TC-Weak that performs well across a range of GPU applications.
TC-Weak with a simple lifetime predictor improves performance apps with inter-workgroup communication by 85%
over the baseline non-coherent GPU.
performs as well as the VI protocols and 23% faster than MESI across all benchmarks.
for apps with intra-workgroup communication, it reduces the traffic overheads of MESI, GPU-VI and GPU-VIni by 56%,23% and 22%, reducing interconnect energy usage by40%, 12% and 12%.
Compared to TC-Strong, TC-Weak performs 28% faster with 26% lower interconnect traffic across all applications.
2 discusses related work,
3 reviews GPU architectures and cache coherence,
4 describes the directory protocols
5 describes the challenges of GPU coherence.
6 details the implementations of TC-Strong and TC-Weak,
7 and 8 present our methodology and results
9 concludes.
2 Related Work
timestamps explored in software coherence [42, 63]
Unlike LCC, TC-Strong supports multiple outstanding writes from a core and implements a rc model.
TC-Strong includes optimizations to eliminate stalls due to private writes and L2 evictions.
the stalling of writes in TC-Strong causes poor on GPU.
propose TC-Weak and a novel time-based memory fence to eliminate all write-stalling, improve performance, and reduce interconnect traffic compared to TC-Strong.
unlike for CPU apps [34, 54],
the fixed timestamp prediction
proposed by LCC is not suited for GPU applications.
We propose a simple yet effective lifetime predictor that can accommodate a range of GPU applications.
Lastly, present a full description of our proposed protocol, including state transition tables that describe the implementation in detail.
3 背景
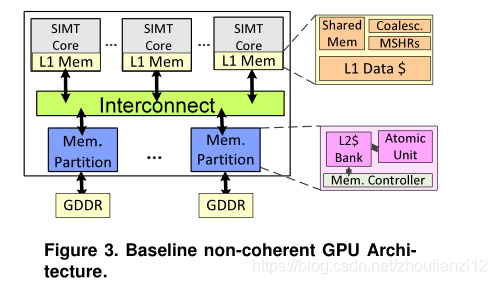
the memory system and cache hierarchy of the baseline non-coherent GPU ,
similar to NVIDIA’s Fermi [44],
we evaluate in this paper.
Cache coherence is also briefly discussed.
3.1 Baseline GPU Architecture
Figure 3 :the organization of baseline non-coherent GPU.
An OpenCL[29]or CUDA[46] application begins execution on a CPU
and launches compute kernels onto a GPU.
Each kernel launches a hierarchy of threads (an NDRange of work groups of wavefronts of work items/scalar threads) onto a GPU.
Each workgroup assigned to a multi-threaded GPU core.
Scalar threads are managed as a SIMD execution group