A Primer on Memory Consistency and Cache Coherence—第五章 Relaxed Memory Model
Motivation of Relaxed Model
- SC模型或者TSO模型在某些需要正确存储顺序的场景下能够保证程序正确执行,但是在某些不需要存储顺序的情况下,限制了程序的性能优化
- 当系统不约束程序的存储顺序时,更多的优化技术可以被使用
存储操作执行顺序无关的示例
示例1
程序员所期望的执行顺序和结果:
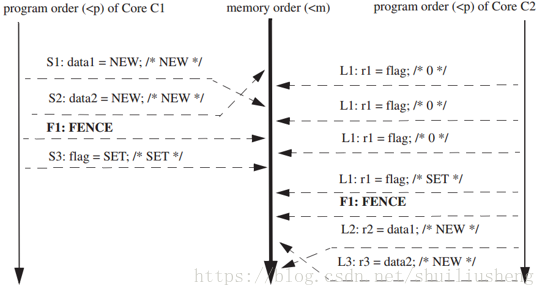
S1 → S3 → L1 loads SET → L2 和 S2 → S3 → L1 loads SET → L3
但是TSO和SC模型强制要求程序的执行顺序为:
S1 → S2 → S3 → L1 loads SET → L2 → L3
示例2
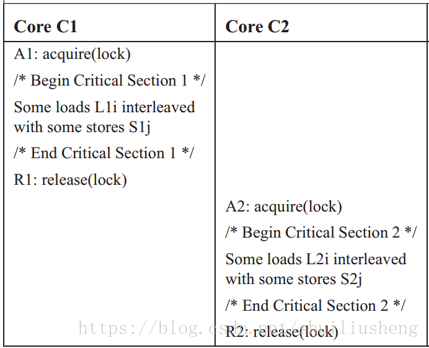
代码主要功能是利用系统提供的锁操作,访问临界区资源程序员的主要目的是不希望两个线程同时访问同一资源,即程序执行的顺序为:All L1i, All S1j → R1 → A2 → All L2i, All S2j但是在SC和TSO模型中:所有的L1i和S1j之间需要按照程序顺序执行,所有的L2i和S2j之间需要按照程序顺序执行
利用Reordering进行可能的优化
为程序员提供显式的FENCE操作,在软件层面利用FENCE强制要求某些存储操作的执行顺序
Non-FIFO, Coalescing Write Buffer
当两个stores的目的地址一致时,支持在write buffer中两个stores合并在一个表项,但是需要保证这两个stores之间没有FENCE指令
Simpler Support for Core Speculation
优化在严格存储模型中的Speculative Loads。SC模型中的Speculative Loads必须在提交之前进行严格的检查以保证结果正确,但是对于顺序无关的存储操作,这种检查将不再必须
Coupling Consistency and Coherence
通过临时打破Cache的SWMR不变量约定,加快Store和Load的执行,允许出现不同的处理器Load不一样的值
XC模型(An E**x**ample Relaxed **C**onsistency Model )
简介
出于教学目的,提出的一种松散序模型。用于介绍松散序模型的基本思想和一些可能的实现方案
基本思想
- 提供FENCE指令,显式的指示需要按序执行的时机
- 除了FENCE指令,默认情况下所有的Stores和Loads可以乱序
- 针对同一个地址的存储操作,保持和TSO一致的约束
- 保证Loads能够立刻看到同一个线程内发生的Stores
XC模型中的FENCE指令
- 用处:为程序员提供一种可以控制程序执行顺序的操作
- 如果Ci先执行Xi (Stores + Loads),然后执行FNECE指令,之后执行Yi,那么FENCE指令会保证所有的Xi指令先于FENCE执行完成,所有的Yi在FENCE指令执行结束后开始执行
- XC模型中FENCE指令的影响范围:当前处理器中
- XC模型保留的约束:Load->FENCE,Store->FENCE,FENCE->FENCE,FENCE->Load,FENCE->Store
XC模型的定义
所有cores的loads,stores和FENCEs指令在插入Memory Order时遵守的约束
所有cores的地址相同的loads,stores指令在插入Memory Order时遵守的约束
每个Load能够获取到在此之前最后一个具有相同访问地址的Store的数据
XC模型的执行示例
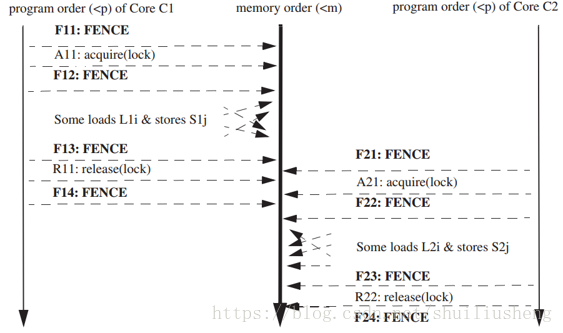
使用足够的FENCE指令,一个松散序模型(XC)可以表现出和SC一样的直接结果
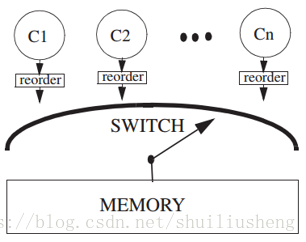
XC模型的简单实现
使用switch实现的XC模型的工作流程
- 每个处理器的Loads,Stores和FENCEs按照Program Order进入该处理器的Reorder unit的尾部
- Reorder Unit按照Program Order存储指令或者根据一些规则重新对指令进行排序。FENCE指令只有处于Unit的头部时才能够被丢弃
- 当switch选择Ci,Ci从Reorder Unit的头部取出load/store开始执行
XC模型的原子操作的实现
一种简单的实现方式
- 获取RMW要访问的cache block的read-write权限
- 执行RMW的Load部分和Store部分
- 在执行RMW的过程中,该cache block的权限不能被修改
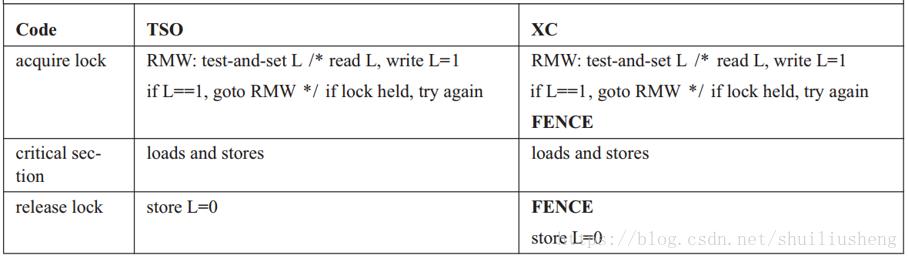
XC和TSO的RMW操作比较
- 实现方式的不同
- TSO在实现RMW的过程中,需要保证在RMW执行之前,Write Buffer中所有的Store都已经执行完成(或者都具有read-write权限)。原因是防止出现RMW中的Store部分在之前的Store之前完成
- XC模型则没有这个步骤,因为XC模型没有Store->Store的约束
- 使用RMW进行同步的方式不同
- TSO保持了除了Store->Store之外的三种约束,所以在这种情况下,使用RMW进行同步操作(临界区资源访问),RMW之后的指令不会提前执行,RMW之前的指令不会滞后执行
- XC模型由于没有约束,所以使用RMW进行同步,如果不加限制将会出现问题,因此RMW指令在进行同步操作时必须配合FENCE指令使用
- 实现方式的不同
松散序模型的性质—因果性
因果性:If I see it and tell you about it, then you will see it too.
假设data2=NEW,此时如果r3=NEW,模型满足因果性;如果r3=0, 模型不满足因果性
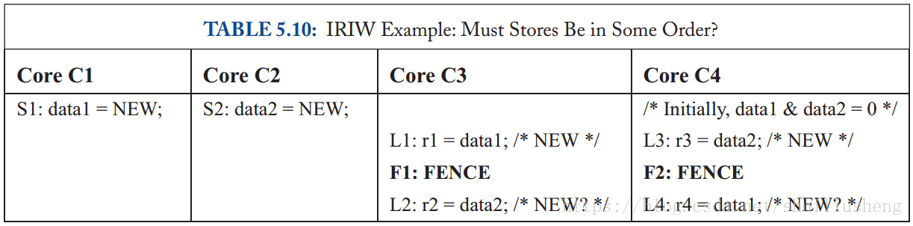
松散序模型的性质—写原子性
写原子性:A core’s store is logically seen by all other cores at once.
假设r1=r3=NEW,此时,如果r2=0&r4=0,模型不满足写原子性。因为S1或者S2并没有一次被C3和C4看到,因此模型不满足写原子性。
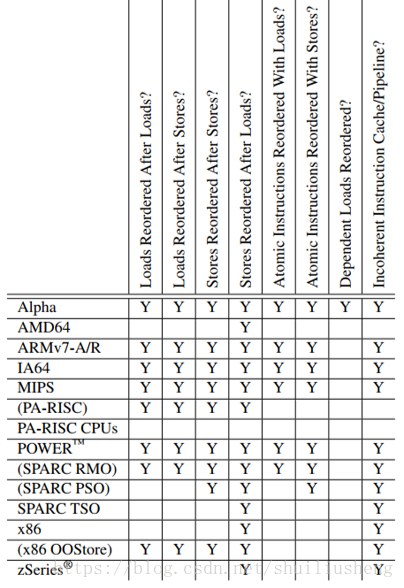
处理器支持的存储操作