Inter-prediction for Multiview video coding(多视图视频编码的帧间预测)
1 实验目的与要求
在多视角视频领域,对于多角度的视频的大数据量通常需要压缩。在对于高帧率视频的压缩中,我们通常会遇到如下问题,即对于前后相邻的两帧图像,因为十分相似,所以会有许多的冗余(重复性)信息;除此之外,对于同一帧但不同拍摄角度的多幅图像,由于摄像头的角度变动范围较小,所以通常也会存在众多的冗余(重复性)信息。所以在图像压缩中,我们会对于以上的问题进行分析,从而进一步压缩视频的存储规模。
在本实验中,我们需要根据前后相邻两帧的共17幅图像,进行其中1幅图像的预测。其中17幅图像分别为,前一帧图像的9个不同角度位置拍摄的图片,其中编号依次为左上角的图片为R1,上部中间的图片为R2,右上角的图片为R3,右侧中间的图片编号为R4,中心图片编号为R5,以此类推;对于后8个图像是当前帧的8幅图片,相比于前一帧的9张图片,缺少的中心的图像即是我们要预测的图像。上述过程可以用下图1.1表示:

上图中的X就是我们最终需要预测的图像。此问题可以归纳为根据参考图像R1-R17生成预测的图像,并尽可能使得预测图像X与label的PSNR尽可能的大。此问题的数学表示如下:
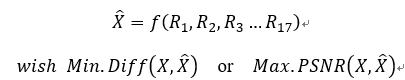
对于数据集,我们要用到的数据集包括以下七组图像:Boys、Cam_Still、NagoyaDataLeading、NagoyaFujita、NagoyaOrigami、Toys和Trees。其都为RGB三通道,范围为0-255的图像。
实验要求,图像X的真实值不能在计算中出现;在算法中必须使用前一帧图像中的至少一幅图像,必须使用当前帧中的至少一幅图像进行预测;对于图像要进行分块化处理,而且每一个小图像块的区域大小需要在以下范围内选择:4×4,8×8,16×16,32×32,64×64,同时要保证R1-R17的分割大小与预测图像X的分割大小相同,且一一匹配。此过程可以用图1.2进行表示:

最终的计算指标是RBG三通道的RSNR的平均值,具体计算公式如下:
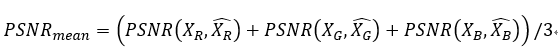
2 实验过程与具体算法
2.1 算法流程简单描述
我们首先将此优化问题归纳为以下的步骤:
- 将R1-R17这17幅图片分割。分割的区域的边长应符合题目要求,并将分割后的区域打上标签Rx(i,j),Rx(i,j)表示在图x中水平方向的第i个,在垂直方向的第j个block,这样可以做到17个图像中的小区域的一一对应。
- 在前一帧的R1-R9中得到分割后的每一个小区域中R2(i,j)、R4(i,j)、R6(i,j)、R8(i,j)与R5(i,j)的对应关系。此问题可以表示为下面的数学问题:
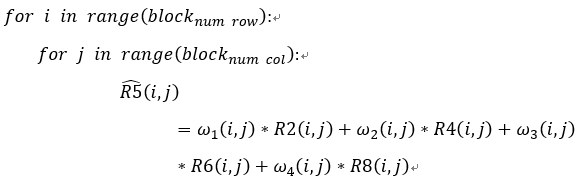
其中ω_x (i,j)是位置为i,j的权重矩阵。使用CVX,设置权重矩阵ω_x (i,j)作为优化变量,min.diff(R5,(R5) ̂ )为优化目标,进行优化得到最优的权重矩阵ω_xbest (i,j)。 - 将第(2)步得到最优的权重矩阵ω_xbest (i,j)进行直接使用到当前帧的图片中并使用此计算出X ̂。
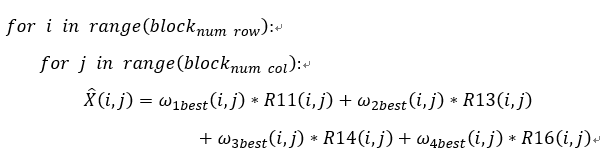
并计算最终的PSNR指标。
整体算法的主要伪代码如下:

算法的时间复杂度计算公式如下:
Complexity=lock_num rowblock_num col complexity_of_cvx_problem
整体的算法流程如下图所示,下面将详细介绍每一步骤的具体实现流程,以及步骤内对于问题的分类讨论情况:

2.2 算法每一步骤的具体实现
在切割步骤中,由于实验对于block的边长有约束,所以这里使用了求模的方法,对于不够block边长的区域进行边界补零操作。并将分割后的结果打上标签:Rx(i,j),即表示在图x中水平方向的第i个、在垂直方向的第j个block。
计算在前一帧的图像中分割后的每一个小区域中R2(i,j)、R4(i,j)、R6(i,j)、R8(i,j)与R5(i,j)的对应关系。在这里考虑到摄像机不同的移动方向,我们对于实际的block进行了位置的调整,例如R2(i,j)是R5(i,j)在摄像头“上仰”时得到的图像,所以与R5(i,j)的图像最接近的R2中的图像应该位于R2(i,j)的正下方附近,所以,在这里我们设定了一个offset,让R2(i,j)这个block在offset中进行步长为1,方向为下的平移,并在每一次平移后进行新的(R2) ̂(i,j)与R5(i,j)的PSNR的计算,最终计算得到PSNR最大的(R2) ̂(i,j)作为我们的实际算法中使用的R2(i,j)这个block。我们对于R4、R6以及R8也进行上述操作,与R2不同的是,R4的offset方向是向右的;R6的offset方向是向左的;R8的offset方向是向上的,因为这些方向与对应的R5的匹配度是最高的。最终得到一个小block中的5个图像。具体的实验过程可以表示为图2.2:

在此基础上,我们将计算得到的R2(i,j)、R4(i,j)、R6(i,j)、R8(i,j)看作自变量,将(R5) ̂(i,j)视为因变量,进行模型构建,即:
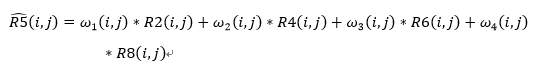
其中的ω_1 (i,j)表示 R2(i,j)对应的权重矩阵,大小为block_sizeblock_size的,R2(i,j)的大小为block_sizeblock_size3的,这里的3指的是RGB三通道,这里我们认为同一pixel上的RBG值的权重相同,这样可以减少优化参数,提高运算速度。
在实验中,我们发现待处理block有两种情况,其中一种为前一帧的block和对应的当前帧的block无较为明显的差异,这种情况下我们选择将每一个block中进行pixel-to-pixel的匹配,即使用权重矩阵ω_x (i,j)进行模型的优化,这里的权重矩阵就是大小为block_sizeblock_size的矩阵,图形化表示为图2.3:

在另一方面,前一帧的block和对应的当前帧的block有较明显的差异,例如在boys图片中,出现了右侧男生手中的玩具熊的位置明显变化的情况,这时再使用精细化的pixel-to-pixel的方法没有意义,而且会降低运算速度并造成过拟合。所以在这种情况下,我们采用将权重矩阵ω_x (i,j)变为一个数值,进行简化,其图形化表示为图2.4:

基于此,构建一个优化函数的模型,如下图2.5、图2.6所示:

或者是:

我们在代码中设置,当前一帧与后一帧对应的block的PSNR小于某一阈值时(即两block不相似),使用基于图2.4的权重数值对应的loss值进行计算;当前一帧与后一帧对应的block的PSNR大于某一阈值时(即两block相似),使用基于图2.3的权重矩阵对应的loss值进行计算。此过程的可视化描述见图2.7:
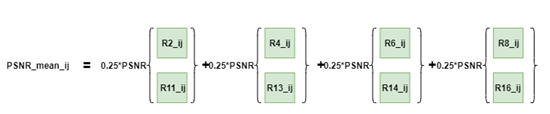
除此之外,我们使用了一范数、二范数(速度极慢)、无穷范数以及Frobenius范数分别进行优化尝试,得到了最终的最优权重矩阵(权重值)。
通过上面的步骤,可以得到最优的权重矩阵或者权重参数ω_xbest (i,j),直接使用以下公式进行图像x的计算,计算公式如下。
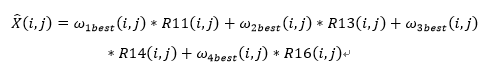
这个过程可以使用图2.8进行可视化:

计算得到图像x的预测值后,使用Matlab自带的PSNR函数进行计算,公式如下:
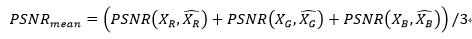
3 实验结果与分析
3.1 分块大小对结果的影响
首先我们以Trees为例,探究了不同的分块大小对最终结果的影响。当权重ω分别为单值或者矩阵,分块大小分别为8,16,32和64时,通过上面介绍的方法得到的Trees图片的PSNR结果如表3.1 所示:
表3.1 分块大小对Trees预测结果影响表
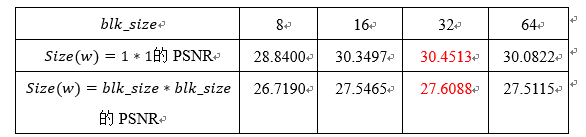
从以上结果可以看出,无论是当权重ω是单值的时候还是当权重ω是矩阵的时候,均是在blk_size=32的时候取到最优值,对于其他的六组图片的结果也均类似,因此在后续的实验中,均采用32为图像分块的大小。
3.2 权重ω对于结果的影响
在Blk_size=32的情况,我们对比了当权重ω是单值和ω是矩阵的情况下,7组预测图片和原图的PSNR对比结果,结果如下表:
表3.2 w形态对结果的影响表

从结果可以看出,对于Trees图片,当权重ω的取值是单值时结果的PSNR更高,而对于其余的6张图片,当权重ω的取值是矩阵的时候,输出图片的PSNR更高。这主要是因为,当ω为权重的时候,是在像素级别进行优化,而当ω是单值的时候,是在分块的级别进行的优化。通过观察,发现Trees上下两帧图片之间的差别很大,相机存在着轻微的移动,且图片中的树叶会存在一定的移动,因此如果利用上一帧像素级别的权重信息来预测下一帧的图片,可能会产生较大的误差。而对于静态的图片,特别是NagoyaDataLeading、NagoyaFujita、NagoyaOrigami这三张图片,上下帧的同一位置的图片的差别很小,但是同一帧相邻位置图片之间的差别较大,且不同纹理部分的差别不同,存在这一定的角度差异,因此仅仅将ω作为一个单值,不能够完全表述存在的这种细节差异,因此当ω为矩阵的时候,最后的结果会比较好。
3.3 模型融合的结果
通过观察上面的实验结果,我们发现,Trees和其他图片的输出结果之间存在这一定的矛盾。为了进一步探索为何会存在这种差别,我们定量化地输出了每张图片的32*32的分块的psnr_means的之别,前面的原理部分已经介绍,psnr_means是衡量上下两帧图片的相似性的,下面的每幅图中,横坐标表示psnr_means的取值,纵坐标表示对应的分块数量。


从上面的图片可以看出,除了Trees图片,其余六幅图的psnr_means分布的峰值基本都在35以上,而Trees的psnr_means分布的峰值在15左右,这可能是造成Trees结果和其余图片结果不同的一个原因,因此我们对于不同psnr_means的块进行不同的处理。对于psnr_means小于一定阈值的分块,采取的权重ω是一个单值;对于psnr_means超过一定阈值的分块,采取的权重ω是一个矩阵。
通过观察上面psnr_means的分布图,我们发现选择25作为阈值,可以不影响NagoyaDataLeading、NagoyaFujita和NagoyaOrigami三张静态的图片,同时能够包含trees大部分的分块。最终得到的结果如下表:
表3.3 阈值方法得到的七个图片的PSNR结果

我们将三种方法的结果整合得到如下表格:
表3.4 三种结果对比表

可以看出,通过将两种模型进行融合,最终得到的结果中,Trees的结果相对于ω是矩阵的情况,得到了明显的提升,虽然相对于ω是单值的时候还有一点点差距,而且其余的图片的PSNR相对于ω是矩阵的时候均变化不大,略有上升或下降,或者保持不变。除此之外,进行模型融合后七组照片的平均PSNR得到了较为显著的提高。所以根据图片的先验特性,将两种模型进行融合,能最大程度地合并两种模型的优点,从而达到较好的效果。
最终的结果图如下:




各张图片分块的结果及其对应的各个block的PSNR热力图如下:

Boys_blocks_num=816
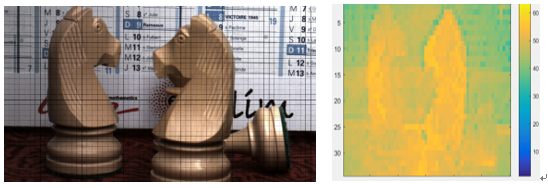
Cam_Still_blocks_num=2040

NagoyaDataLeading_blocks_num=812

NagoyaFujita_blocks_num=812

NagoyaOrigami_blocks_num=812

Toys_blocks_num=238

Trees_blocks_num=238
4 结论与思考
具有以下的三个创新点:
首先,我们创新性地使用了以权重为优化变量的思想,而不是将待预测图片作为优化的变量(以待预测图片作为优化变量的方法,在课程的小上机作业中被大部分同学所使用),同时目标优化函数采用的是前一帧图像的R5的真实值和预测值之间的范数损失。
除此之外,我们也将前一帧图像中的不同位置的图片的先验知识进行归纳,并根据前后两帧同一位置的block的具体特征进行权重形式分类讨论。如果前后两帧同一位置的block的PSNR很大,即采用矩阵形式的权重,进而突出图片的细节特征;如果前后两帧同一位置的block的PSNR较小,即图片在前后两帧中的动态特征较为明显,则采用单个数值形式的权重,从而进行分块级别的优化,防止使用权重矩阵时出现图像的过拟合。
最后,我们在选择合适的权重矩阵时,对于阈值的考虑也是比较科学的,没有通过手动尝试的方法,我们是将所有block对应的PSNR进行了统计,根据每张图片统计出来的PSNR直方图的“峰值”和“谷值”进行对应阈值的选取。通过实际的测试,在七张图片平均PSNR较高的情况下,对于每一个图片得到了最好的PSNR的数值结果。
对于模型我们也有进一步的优化思路:
首先,可以尝试在损失函数的计算中加入正则化项,进而增加模型的鲁棒性,这个方案我们尝试过,不过由于计算复杂度太高导致计算过程极为缓慢,在模型指标和运算时间代价的权衡下,我们放弃了加入正则项这个方法。
除此之外,我们可以借鉴其他方法所得到的结果与我们现在所得到的结果再进行模型融合,从而得到更优的模型结果。例如我们在小上机作业中所采用的以待预测图片作为优化变量的这一思路得到的模型,其结果与我们的模型得到的结果进行加权取平均等融合操作,也许会得到更好的结果。
这次实验我们使用凸优化的CVX包,完成了“多视图视频编码的帧间预测”,通过分析问题,并将预测问题归纳为一个凸优化问题,寻找优化目标函数以及约束条件,完成了图片的预测,在PSNR的模型评价指标下,我们的算法实现了较好的预测效果。本次实验为我们将来的课题研究积累了实践的经验,也提高了我们将普通问题转化为凸优化问题来思考并解决的能力。
5 附录
报告中所有参数的具体含义:
Rx(i,j):在图x中水平方向的第i个、在垂直方向的第j个block;
block_size:block的边长(这里取值范围在4.8.16.32.64中);
block_(num row):在水平方向block的总个数;
block_(num col):在竖直方向block的总个数;
Offset:计算用于优化问题的Rx(i,j)是,偏移量的范围;
ω_x (i,j):位置在i,j的block对应的权重矩阵;
〖 ω〗_xbest (i,j):经过计算得到的,位置在i,j的block对应的最优的权重矩阵;
(R5) ̂:图像R5的预测值;
X ̂:图像X的预测值;
PSNR(X_R,(X_R ) ̂ ):在R通道中的PSNR的数值;
PSNR_mean:RGB三通道的PSNR的平均值。