爬虫目标网址:https://www.dongqiudi.com/news
打开网址后向下滑动看到我即将爬取的国际新闻板块

咦?说好的五大联赛的呢?看不起法甲?好吧,将就一下,就爬取“欧洲四大联赛的新闻”:英超,西甲,意甲,德甲。这四个小板块的结构肯定都是一样的,所以我们分析一个就可以了,这里以英超为例。点开英超新闻板块
向下滑动新闻列表,可以看到加载下一页的按钮

点击即加载下一页,打开控制台可以看到从第二页开始的新闻列表都是以JSON文件返回的
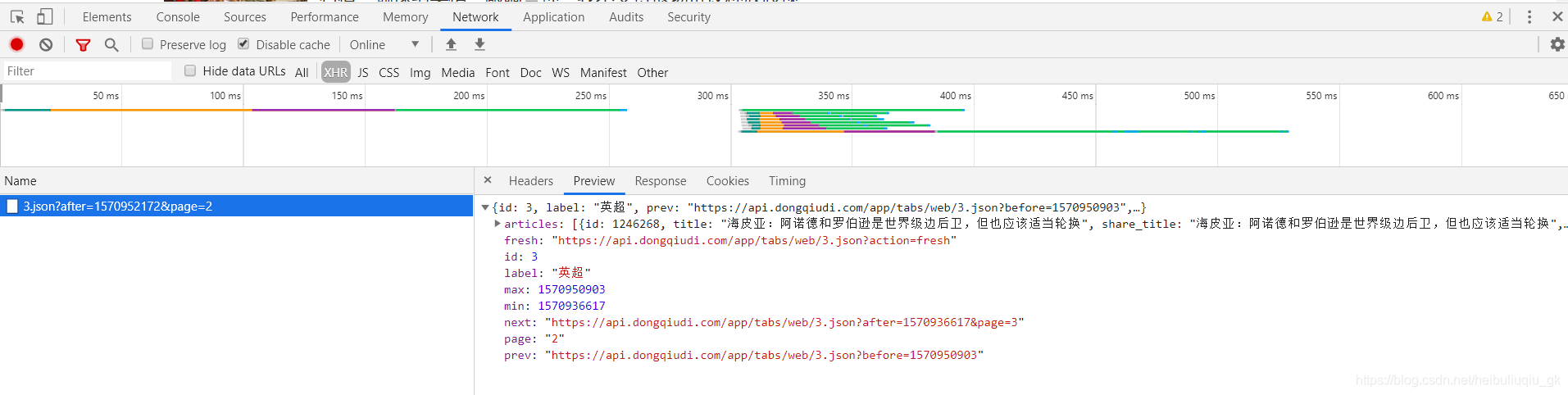
同时可以在JSON文件中发现下一页和上一页的链接,这就好办了,我们现在可以梳理一种思路:先获取英超新闻列表页的第一页JSON文件信息,从中提取所有新闻信息,然后再获取下一列表页的链接,然后再像获取第一页那样获取JSON文件,如此循环,就可以获取很多页的新闻信息。
可能有人会说,这里明明是从第二页开始才是用JSON文件返回的,而第一页是一开始就渲染好的,怎么第一页也会有JSON文件呢?至于这个问题,试试就知道了。
先来看看获取第二页JSON文件信息的链接

把这个url搞到,然后到浏览器请求看看

卧槽,这是啥?好吧,我们换一种方式
import json
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64'
') AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
}
url = 'https://www.dongqiudi.com/api/app/tabs/web/3.json?after=1570952172&page=2'
json_data = requests.get(url, headers=headers)
data = json.loads(json_data.text)
for k, v in data.items():
print(k, ':', v)
我们用requests来请求该链接,然后将获取的JSON数据转换成Python中的字典,然后对字典进行遍历解析,得到如下内容:

我们可以看到很多关键信息,这里我们主要关心的是当前页数,page=2,而如果我们需要获取第一页的JSON数据呢?看看请求链接的规律
https://www.dongqiudi.com/api/app/tabs/web/3.json?after=1570952172&page=2
观察链接,可以看出,那个数字3就是id(表示当前是英超新闻,和label对应),after这个参数应该是个时间戳,通过时间戳找规律太复杂了,不用管,page就是当前页数。我们试着改动一下参数,以获得第一页的JSON数据文件。通过改动后,得到了可获得第一页JSON数据的最简链接:
https://www.dongqiudi.com/api/app/tabs/web/3.json
请求数据显示如下:

好了,这里获取第一页新闻列表JSON数据,那么我们就可以从第一页开始,一页一页的往后面爬取了。
获取了新闻列表页,我们还需要获取到列表页中的新闻信息,观察上图可知,articles获取了当前列表页所有的新闻信息。
观察控制台JSON数据:

可以发现有很多重要信息,包括:is_video(是否是视频新闻),share(新闻详情页链接)。(这两个信息是之后主要会用到的)
通过这里。我们又可以思考:刚刚上面获取了每一列表页的信息,这里又获取了列表页中新闻的信息,这里可以通过新闻的链接获取到新闻的详情页,之后我们只需要解析新闻详情页中的内容,就可以爬取成功了?!岂不是美滋滋!没错,大概思路就是这样:逐步细化,逐渐深入。
我们现在来获取一页列表页中的所有新闻链接看看:
import json
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64'
') AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
}
url = 'https://www.dongqiudi.com/api/app/tabs/web/3.json'
json_data = requests.get(url, headers=headers)
data = json.loads(json_data.text)
articles = data.get('articles')
for article in articles:
print(article.get('share'))
运行结果如下:

我们发现有个长得不太一样的链接,解释下:这个应该是属于一些官方号发的一些动态,不是新闻。所以我们要把这个“异类”筛掉,不需要爬取他。
至于其他的链接,都是新闻,页面长成这样的:

我们最终要获取的就是新闻详情里面的内容,包括标题,作者,发布时间,正文文本内容,正文中的图片,正文中的视频。
到这里,现在可以来说一说这个爬虫具体要实现的功能和逻辑了:
先来看个图:

我们需要爬取的是懂球帝新闻中英超,西甲,意甲,德甲的新闻,由于这是四个结构一样的板块,所以解析一个就可以了,以英超为例。进入英超新闻第一页列表页,需要先获取到当前页所有的新闻链接等内容,再对链接进行筛选,然后将筛选通过的链接存入设置了唯一索引的数据表,如果存入成功,说明以前没有爬取过这条新闻,然后就通过成功存入的链接获取到新闻详情页,解析新闻详情页,获取到我们需要爬取的内容,然后存入数据库。解析完第一页列表页后,获取下一页列表页的链接,然后获取下一页页面,就像第一页这样爬取,这样不断循环,就可以爬取很多页了。最后再将其余三个板块的新闻都加进去,这样就差不多了。嗯,大概逻辑就是这样。。。当然还有很多细节,需要在代码中体现。
然后程序实现代码如下(代码中有详细注释哦!):
import json
import re
from lxml import etree
import pymysql
import requests
from datetime import datetime
from config import host, port, user, password, charset, database # 这是数据库配置文件,根据自己环境自己设置
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64'
') AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
}
class NewsSpider:
"""懂球帝新闻爬虫类"""
def __init__(self):
"""初始化函数"""
self.base_url = "https://www.dongqiudi.com/api/app/tabs/web/{}.json" # 基础url(后期处理)
self.label_num = [3, 4, 5, 6] # 新闻标签数字(与base_url组合)
self.start_urls = [] # 即将爬取的新闻列表页链接
# 生成最初的即将爬取的新闻列表页链接并添加到start_urls中
for num in self.label_num:
url = self.base_url.format(num)
self.start_urls.append(url)
self.headers = headers
self.db = pymysql.connect(host=host, port=port, user=user, password=password,
database=database, charset=charset) # 建立数据库连接
self.cur = self.db.cursor() # 创建游标
def get_news_page(self, url):
"""获取一页新闻列表页"""
try:
news_page = requests.get(url, headers=self.headers, timeout=5) # 请求链接
except requests.exceptions.ReadTimeout:
return None
news_dict = json.loads(news_page.text) # 将json解析成dict
label = news_dict.get('label', '') # 获取新闻标签名
next_page = news_dict.get('next', '') # 获取下一页新闻列表页链接
articles = news_dict.get('articles', []) # 获取当前新闻列表页的所有新闻
result = {'label': label, 'next_page': next_page, 'articles': articles}
return result
def url_to_mysql(self, url):
"""新闻链接存入数据库,数据库设置了唯一索引,用来去重,爬过的新闻不再爬取"""
try:
self.cur.execute("insert into news_urls(news_url, add_time) values ('%s', '%s')" % (url, datetime.now()))
self.db.commit()
return 'ok'
except pymysql.err.IntegrityError:
return None
def get_news_detail(self, url):
"""获取新闻详情,使用xpath解析技术"""
try:
detail = requests.get(url, headers=headers, timeout=5)
except requests.exceptions.ReadTimeout:
return None
html = etree.HTML(detail.text)
title = html.xpath('//div[@class="detail"]/h1/text()') # 标题
author = html.xpath('//div[@class="detail"]/h4/span[@class="name"]/text()') # 作者
create_time = html.xpath('//div[@class="detail"]/h4/span[@class="time"]/text()') # 新闻发布时间
content = html.xpath('//div[@class="detail"]/div[1]//text()') # 正文文本内容
images = html.xpath('//div[@class="detail"]/div[1]//img/@src') # 所有图片链接
videos = html.xpath('//div[@class="detail"]/div[1]//div[@class="video"]/@src') # 所有视频链接
news_detail = {
'title': title[0],
'author': author[0],
'create_time': create_time[0],
'content': re.escape(''.join(content)),
'images': '##'.join(images),
'videos': '##'.join(videos),
}
return news_detail
def detail_to_mysql(self, detail, label, news_type):
"""新闻详情存入数据库"""
try:
self.cur.execute(
"insert into news_details("
"label, news_type, title, author, content, images, videos, create_time, add_time"
") values ('%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s')" % (
label, news_type, detail['title'], detail['author'],
detail['content'], detail['images'], detail['videos'], detail['create_time'], datetime.now()))
self.db.commit()
return 'ok'
except pymysql.err.IntegrityError:
return None
def select_url(self, url):
"""筛选需要爬取的新闻链接"""
if 'https://www.dongqiudi.com/article' in url:
return 'ok'
else:
return None
def close_db(self):
"""关闭数据库连接"""
self.cur.close()
self.db.close()
def work_on(self):
"""逻辑执行函数"""
for i in range(1, 11): # 爬取多少页
if len(set(self.start_urls)) == 1: # 判断start_urls里面如果全是None,说明就没有要请求的新闻列表页了,就结束循环
break
for j in range(len(self.start_urls)): # 遍历start_urls来获取即将请求的列表页
url = self.start_urls[j]
if url is None: # 如果该url已经变成None,说明该类标签的新闻没有可以请求的列表页了
continue
a_page = self.get_news_page(url) # 获取一页新闻列表页
if a_page is None: # 如果返回是None,说明请求新闻列表页失败(请求超时),这时直接放弃该类标签新闻的所有列表页,因为当前页请求失败意味着没有办法获取到下一页的链接
self.start_urls[j] = None
continue
articles = a_page.get('articles') # 获取当前列表页的所有新闻信息
label = a_page.get('label') # 获取当前列表页属于哪种标签新闻
if articles: # 保险起见,判断下是否成功获取到新闻信息
for news in articles: # 遍历新闻信息列表
is_video = news.get('is_video') # 获取当前新闻类型
if is_video is True: # 判断当前新闻类型是视频还是文本
news_type = 'video'
else:
news_type = 'text'
news_url = news.get('share') # 获取当前新闻详情页的链接
if news_url: # 保险起见,判断下是否获取到当前新闻详情页的链接
if self.select_url(news_url) == 'ok': # 新闻详情页链接进行筛选
result = self.url_to_mysql(news_url) # 将筛选后的新闻详情页链接尝试存入数据库
if result == 'ok': # 如果成功存入数据库
news_detail = self.get_news_detail(news_url) # 获取当前新闻详情页信息
if news_detail: # 判断是否获取成功
info = self.detail_to_mysql(news_detail, label, news_type) # 将新闻详情尝试存入数据库
if info == 'ok': # 判断是否成功存入
print('存入%s新闻成功: %s' % (label, news.get('title')))
else:
print('存入%s新闻失败: %s' % (label, news.get('title')))
next_page = a_page.get('next_page') # 获取当前新闻列表页的下一页的链接
if next_page: # 判断是否有下一页
self.start_urls[j] = next_page # 如果有,就将start_urls里面当前列表页链接替换成下一页的链接
else:
self.start_urls[j] = None # 如果没有,就将start_urls里面当前列表页链接替换成None
self.close_db() # 关闭数据库连接
if __name__ == "__main__":
spider = NewsSpider()
spider.work_on()
print("执行完毕!!!")设置了数据库配置后就可以直接运行。
运行时,控制台显示如下:

运行后数据库数据如下:


这样这个爬虫就完成了,当然这个爬虫是有缺点的,现在只有功能的实现,但是没有考虑太多的安全性以及性能,比如可以加入ip池,使用多线程技术等等的技术,我后期会寻找机会改进。
