最近一直在学习python,研究了一下爬虫,也写了一些demo,所以准备把自己所学分享出来。
一提到python大家第一想法就是爬虫了吧,确实,python在爬虫方面提供了各种强大的模块,再加上python本身语法的简洁易懂,让它在爬虫方面独树一帜。
今天要分享的就是用python爬取新浪新闻网站新闻。
这里要感谢网易云课堂丘祐玮老师,本篇博文内容都是基于老师所讲内容而写,想要学习python学习爬虫的可以去看老师的课程
说在前面:
博主使用的python版本是2.7,版本不一致可能导致一些错误;编辑器使用的是jupyter notebook,系统是windows;写这篇文章主要是为了分享一下爬取新闻的思路,所以博主不会真的去耗费时间爬取整个站点(有这个想法的可以自己去深入研究)
开始学习之前需要安装两个必须的模块:
requests–是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到,BeautifulSoup4–将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象
命令行输入:
pip install requests
pip install BeautifulSoup4
安装完后即可开始进行新闻爬取了
请出今天的主角:https://news.sina.com.cn/world/
要爬取的地方如下:
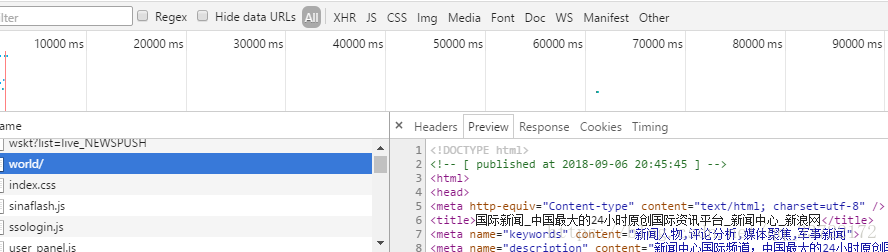
鼠标右键打开检查–network,刷新页面,通过查看请求信息我们可以看到整个页面的内容是通过请求https://news.sina.com.cn/world/ 这个链接获取到的
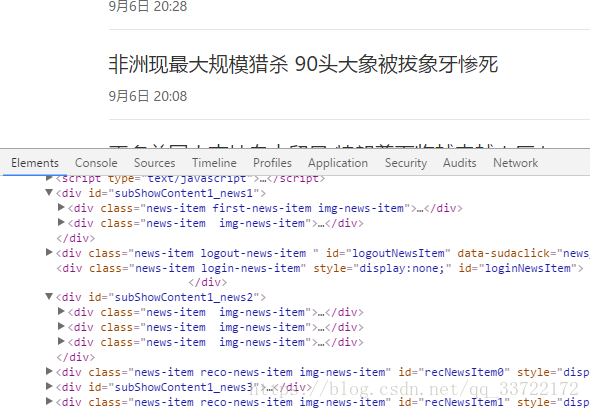
我们抓取新闻无外乎就是新闻标题,来源,发布时间,编辑,内容等,而我们想要的新闻标题,时间 都是可以通过访问https://news.sina.com.cn/world/获得,分析页面元素我们可以发现我们想要抓取的新闻都有一个共同的class new-item
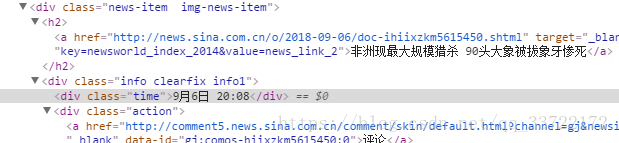
可以看到文章的发布时间和链接
那么我们可以这样写:
import requests
from bs4 import BeautifulSoup
res = requests.get('https://news.sina.com.cn/world/')#模拟get
请求获取链接返回的内容
res.encoding = 'utf-8'#设置编码格式为utf-8
soup = BeautifulSoup(res.text, 'html.parser')#前面已经介绍将html文档格式化为一个树形结构,每个节点都是一个对python对象,方便获取节点内容
for new in soup.select('.news-item'):#BeautifulSoup提供的方法通过select选择想要的html节点类名,标签等,获取到的内容会被放到列表中
if len(new.select('h2')) > 0:
#加[0]是因为select获取内容后是放在list列表中[内容,],text可以获取标签中的内容
print new.select('.time')[0].text+' '+new.select('h2')[0].text +' '+ new.select('a')[0]['href'] 输出结果如下:

有了文章标题,链接,那么还需要文章的内容,来源,我们随便点击一篇文章进入文章内容页,分析页面html标签
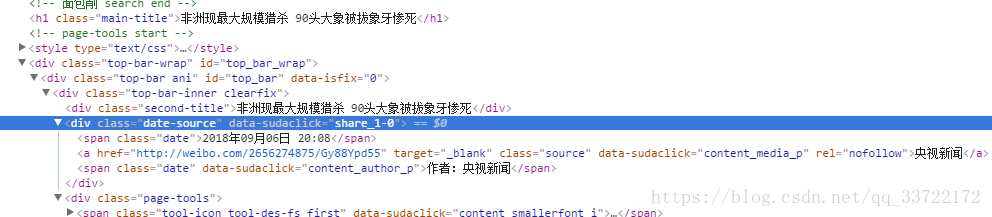

可以看到文章大标题有一个类second-title,文章发布时间有一个类名date,文章来源有一个类名source,文章内容则是在类名article中被段落标签p包着,文章编辑则是有一个类名show_author,了解了这些我们就可以编写爬取新闻代码了
import time
import requests
from bs4 import BeautifulSoup
info = requests.get('http://news.sina.com.cn/w/2018-09-04/doc-ihiixzkm4326136.shtml')
info.encoding = 'utf-8'
html = BeautifulSoup(info.text, 'html.parser')
print html.select('.second-title')[0].text#获取大标题
print html.select('.date')[0].text#获取发布时间
#dt = time.strptime(timesource, '%Y年%m月%d日 %H:%M') #用来格式化时间字符串为时间格式方便储存
#dt.strftime('%Y-%m-%d')
print html.select('.source')[0].text + ' '+html.select('.source')[0]['href']
article = []
for v in html.select('.article p')[:-1]:#获取article中被p包含的内容去除最后一个p标签即责任编辑
article.append(v.text.strip())#将内容添加到列表中,并去除两边特殊字符
author_info = '\n'.join(article)#将列表中内容以换行连接
print author_info
print html.select('.show_author')[0].text.lstrip(u'责任编辑:')#输出编辑姓名输出如下:

这里面还有一个评论数需要特殊处理才能获得,查看请求信息发现,评论数是通过ajax异步获取的如下图:

请求这个链接获取评论数
注意:由上图可以看出请求返回的是json格式数据,所以需要引入json模块进行处理,不过我们可以看到返回的结果左面多出了jsonp_1536240250267(字符,所以要想正确的转化为我们要的数据还得引入re模块进行正则匹配去除掉这个字符串
import json
import re
# comos- hiixzkm4227444为文章id
comments = requests.get('http://comment5.news.sina.com.cn/page/info?version=1&format=json&channel=gj&newsid=comos-hiixzkm4227444&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=3&t_size=3&h_size=3&thread=1&callback=jsonp_1536041889769&_=1536041889769')
regex = re.compile(r'(.*?)\(')#去除左边特殊符号
tmp = comments.text.lstrip(regex.search(comments.text).group())
jd = json.loads(tmp.rstrip(')'))#转换为字典
print jd['result']['count']['total'] #获取评论数经过对比获取评论的链接和文章的链接
http://comment5.news.sina.com.cn/page/info?version=1&format=json&channel=gj&newsid=comos-hitesuz3520331
http://news.sina.com.cn/w/2018-09-06/doc-ihitesuz3520331.shtml
我们可以发现comos-后面的字符和doc-i后面的字符一样,不难猜出这应该就是文章的id了,我们可以通过下面两个方法获取文章id(这个很重要)
newsurl = 'http://news.sina.com.cn/o/2015-12-28/doc-ifxmxxsr3837772.shtml'
newsid = newsurl.split('/')[-1].rstrip('.shtml').lstrip('doc-i')或者
m = re.search('doc-i(.+).shtml', newsurl)
newsid = m.group(1)现在我们已经能够获取文章的各个内容了,那么如何获取每一页的文章呢?
通过点击分页我们不难观察到文章随着页码切换会访问=1536044408917”>https://interface.sina.cn/news/get_news_by_channel_new_v2018.d.html?cat_1=51923&show_num=27&level=1,2&page=4&callback=newsloadercallback&=1536044408917这个链接,懂得一些网站开发的人员都能看出page就是指的当前的页码数,page变化访问的文章列表信息就会变化

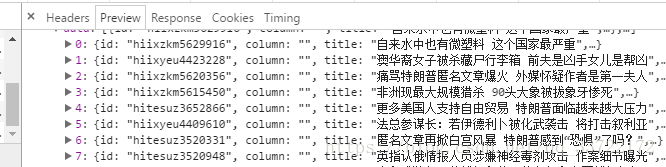
现在我们获取这个页面的内容
test = requests.get('https://interface.sina.cn/news/get_news_by_channel_new_v2018.d.html?cat_1=51923&show_num=27&level=1,2&page=4&callback=newsloadercallback&_=1536044408917')
test2 = test.text.lstrip('newsloadercallback(')
jd = json.loads(test2.rstrip(')\n'))
for v in jd['result']['data']:
print v['url']输出文章的链接如下:

现在我们能够获得每页的文章url,同样也能获取每篇文章的标题内容,发布时间,评论数,来源,编辑,那么剩下的就是把所有代码组织起来拼出一个可以自动批量爬取文章的爬虫了,这里我就不详细叙述了,直接贴出最终整合版,感兴趣的同学可以自己尝试将上述代码组织起来
完整代码如下:
ps:完整代码中我使用了pandas将爬取的文章输出到excel表格中
pandas:基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一
import requests
from bs4 import BeautifulSoup
import time
import json
import re
import pandas
import sys
if sys.getdefaultencoding() != 'utf-8':
reload(sys)
sys.setdefaultencoding('utf-8')
def getnewcontent(url):
result = {}
info = requests.get(url)
info.encoding = 'utf-8'
html = BeautifulSoup(info.text, 'html.parser')
result['title'] = html.select('.second-title')[0].text
result['date'] = html.select('.date')[0].text
result['source'] = html.select('.source')[0].text
article = []
for v in html.select('.article p')[:-1]:
article.append(v.text.strip())
author_info = '\n'.join(article)
result['content'] = author_info
result['author'] = html.select('.show_author')[0].text.lstrip('责任编辑:')
newsid = url.split('/')[-1].rstrip('.shtml').lstrip('doc-i')
commenturl = 'http://comment5.news.sina.com.cn/page/info?version=1&format=json&channel=gj&newsid=comos-{}&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=3&t_size=3&h_size=3&thread=1&callback=jsonp_1536041889769&_=1536041889769'
comments = requests.get(commenturl.format(newsid))
regex = re.compile(r'(.*?)\(')#去除左边特殊符号
tmp = comments.text.lstrip(regex.search(comments.text).group())
jd = json.loads(tmp.rstrip(')'))
result['comment'] = jd['result']['count']['total'] #获取评论数
return result
def getnewslink(url):
test = requests.get(url)
test2 = test.text.lstrip('newsloadercallback(')
jd = json.loads(test2.rstrip(')\n'))
content = []
for v in jd['result']['data']:
content.append(getnewcontent(v['url']))
return content
def getdata():
url = 'https://interface.sina.cn/news/get_news_by_channel_new_v2018.d.html?cat_1=51923&show_num=27&level=1,2&page={}&callback=newsloadercallback&_=1536044408917'
weibo_info = []
for i in range(1,3):
newsurl = url.format(i)#字符串格式化用i替换{}
weibo_info.extend(getnewslink(newsurl))
return weibo_info
new_info = getdata()
df = pandas.DataFrame(new_info)
df #去除全部 df.head() 取出5行 head(n) n行
#将文件下载为excel表格 df.to_excel('weibonews.xlsx')