前言:
最近博主在学习spark相关知识,感觉是个挺不错的框架,它的分布式处理大数据集的思想还是值得我们好好学习的。
个人感觉以后java开发肯定不仅仅是SSM这一套东西了,当数据量越来越大时,我们需要学习使用这些大数据工具。
本次博客学习使用java和scala两种方式来开发spark的wordCount示例
由于采用spark的local模式,所以我们可以完全不用启动spark,使用eclipse,添加spark相关jar包在本地跑就可以了
准备工作:
1.准备数据
在本地创建spark.txt文件,并添加一些语句
2.eclipse工具,用于java开发
3.scala ide for eclipse用于scala开发
下载界面:http://scala-ide.org/download/sdk.html
4.本地安装JDK8(由于笔者使用的spark版本为2.2.0,故需要jdk8及以上版本)
5.本地安装scala(一定要注意,scala的版本需要与spark的版本匹配,当spark版本为2.2.0时,scala版本为2.11,不能太高也不能低,一定要注意,否则创建scala project会报错)
1.java开发wordCount程序(使用工具eclipse)
1)创建maven项目 spark
2)添加Maven依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<scala.version>2.11</scala.version>
<spark.version>2.2.0</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>3)在spark项目中添加WordCountJava类,代码如下
import java.util.Arrays;
import java.util.Iterator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
public class WordCountJava {
public static void main(String[] args) {
// 1.创建SparkConf
SparkConf sparkConf = new SparkConf()
.setAppName("wordCountLocal")
.setMaster("local");
// 2.创建JavaSparkContext
// SparkContext代表着程序入口
JavaSparkContext sc = new JavaSparkContext(sparkConf);
// 3.读取本地文件
JavaRDD<String> lines = sc.textFile("C:/Users/lucky/Desktop/spark.txt");
// 4.每行以空格切割
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
public Iterator<String> call(String t) throws Exception {
return Arrays.asList(t.split(" ")).iterator();
}
});
// 5.转换为 <word,1>格式
JavaPairRDD<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String t) throws Exception {
return new Tuple2<String, Integer>(t, 1);
}
});
// 6.统计相同Word的出现频率
JavaPairRDD<String, Integer> wordCount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
// 7.执行action,将结果打印出来
wordCount.foreach(new VoidFunction<Tuple2<String,Integer>>() {
public void call(Tuple2<String, Integer> t) throws Exception {
System.out.println(t._1()+" "+t._2());
}
});
// 8.主动关闭SparkContext
sc.stop();
}
}4)执行(右键 run as java application即可)
2.scala开发wordCount程序(使用工具scala ide for eclipse)
1)创建scala project ,命名为spark-study
2)转变为maven项目
右键点击spark-study,选中configure,选择其中的convert to maven project选项,等待成功即可
3)添加maven依赖(同上)
注意:笔者使用到spark版本为2.2.0,由于spark版本与scala版本不匹配,导致报以下错误
breeze_2.11-0.13.1.jar of spark-study build path is cross-compiled with an incompatible version of Scala (2.11.0). In case this report is mistaken, this check can be disabled in the compiler preference page.如果读者看到这个报错,就先检查一下自己的scala版本与spark版本是否匹配,如何确定呢,可以在https://mvnrepository.com/artifact/org.apache.spark/spark-core maven仓库中确定,
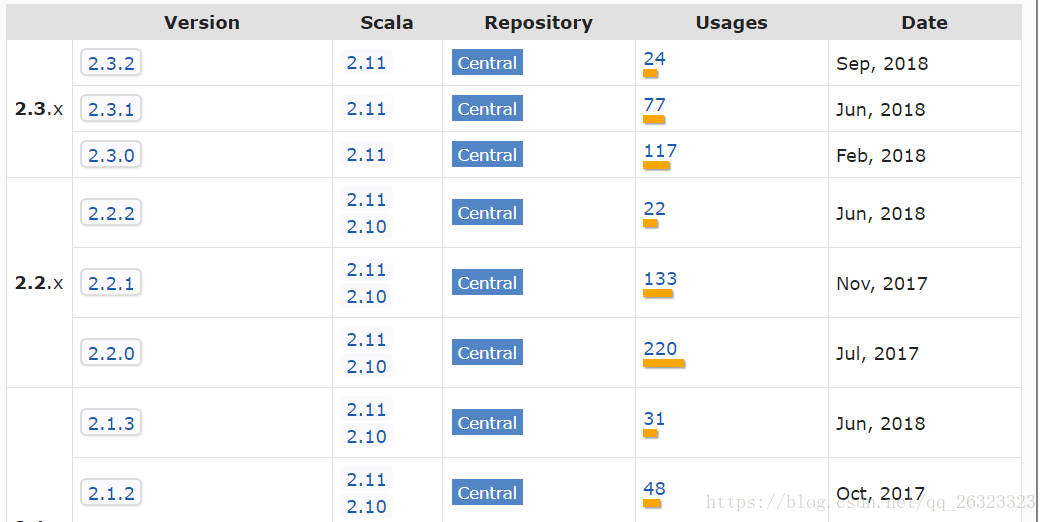
仓库中有spark对应的scala版本,严格按照这个来安装本地的scala即可,否则报错
4)在spark-study项目中创建scala object,命名为WordCountScala,代码如下
object WordCountScala {
def main(args: Array[String]): Unit = {
// 注意选择local模式
val sparkConf = new SparkConf().setMaster("local").setAppName("wordCount");
val sc = new SparkContext(sparkConf)
// 读取本地文件
val lines = sc.textFile("C:/Users/lucky/Desktop/spark.txt");
val words = lines.flatMap(line => line.split(" "))
val pairs = words.map(word => (word,1))
val wordCounts = pairs.reduceByKey((a,b) => (a+b))
// 最后执行action 操作
wordCounts.foreach(wordcount => println(wordcount._1 +" " + wordcount._2))
}
}以上这种方式,我们同样可以简写为:
val sparkConf = new SparkConf().setMaster("local").setAppName("wordCount");
val sc = new SparkContext(sparkConf)
sc.textFile("C:/Users/lucky/Desktop/spark.txt")
.flatMap(line => line.split(" "))
.map(word => (word,1))
.reduceByKey((a,b) => (a+b))
.foreach(wordcount => println(wordcount._1 +" " + wordcount._2))5)执行wordCount(右键run as Scala Application即可)
可以看到在本地控制台打印了結果