flink环境搭建很简单,只需要jdk1.8环境即可。
这里使用的是win10子系统ubuntu2004,直接下载flink,解压,就可以运行了。 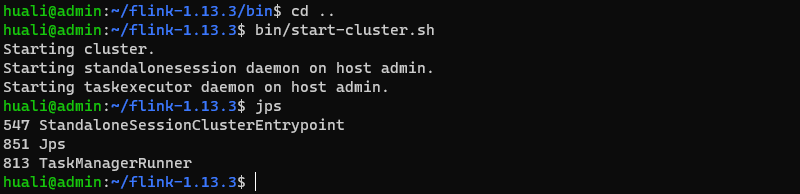
flink程序启动,默认会监听8081端口,可以通过http://localhost:8081,查看flink控制台:

java编写flink示例,既可以在本地运行,也可以打包提交到flink任务管理器中执行。
每一个flink示例,都是一个job。
本地开发flink示例,需要用到的依赖和打包插件:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xxx</groupId>
<artifactId>flinkdemo</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>flinkdemo</name>
<url>http://maven.apache.org</url>
<properties>
<flink.version>1.13.1</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_${scala.binary.version}</artifactId>
<version>1.11.4</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.7.8</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
可以配置一个log4j.properties,便于查看flink运行日志。
log4j.rootLogger=info, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n第一个示例,词频统计,这里读取一个文本文件,然后将每一行数据打散,拆分为单个单词,然后根据单词分组,统计出现的次数。
wordcount.txt

hello flink
hello java
hello worldWordCountApp.java
package com.xxx.flinkdemo;
import java.util.Arrays;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.tuple.Tuple2;
public class WordCountJob {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource<String> dataSource = env.readTextFile("wordcount.txt");
FlatMapOperator<String, Tuple2<String, Integer>> flatMap = dataSource.flatMap((FlatMapFunction<String, Tuple2<String, Integer>>) (lines, out) -> {
Arrays.stream(lines.split(" ")).forEach(s -> out.collect(Tuple2.of(s, 1)));
}).returns(Types.TUPLE(Types.STRING,Types.INT));
AggregateOperator<Tuple2<String, Integer>> sum = flatMap.groupBy(0).sum(1);
sum.print();
}
}
直接在本地运行,打印结果:

以上程序是一个简单的批处理任务,读取文件,然后做词频统计,最后输出结果。是有明显的输入输出界限的,他的流处理完成,任务结束。
还有一类操作,监听一个网络输入事件,会一直持续等待网络写入,不会终止,这类流,称为无界流。flink很适合做这个工作,他的流处理可以做实时数据统计。
下面给出一个示例,连接本地9999网络端口,等待用户输入。然后做词频统计,这时候,因为流是无边界的,只能一步一步统计,不能直接给出最终统计结果。
package com.xxx.flinkdemo;
import java.util.Arrays;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class UnboundStreamJob {
@SuppressWarnings("deprecation")
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.socketTextStream("localhost", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = source.flatMap((FlatMapFunction<String, Tuple2<String, Integer>>) (lines, out) -> {
Arrays.stream(lines.split(" ")).forEach(s -> out.collect(Tuple2.of(s, 1)));
}).returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy(0).sum(1);
sum.print("test");
env.execute();
}
}
运行这个示例之前,我们先启动一个9999网络监听服务,这里使用ubuntu 系统自带的命令netcat:
huali@admin:~/flink-1.13.3$ netcat -lk 9999然后,启动这个任务,之后输入一些单词并回车:

这个任务,我们可以在本地打包,然后提交到flink任务管理器中执行,进入工程所在目录,然后在命令行下执行打包命令:
mvn clean package打包成功,会生成一个工程名的jar包。在flink webui界面,我们切换到Submit New Job菜单:

点击列表右侧的"Add New"按钮,然后添加刚才的jar。jar包上传成功,点击列表中的jar包对象,会弹出下拉选项:

在第一个红框中输入我们要执行的job类名:com.xxx.flinkdemo.UnboundStreamJob,最后点击"Submit"提交按钮。
页面会切换到如下所示的页面,提示任务正在running,表示正常。这时候,网络没有输入,这时候等待用户输入,所以这边的输出显示红色。

同样的,我们在监听9999端口服务的地方,输入一些单词,然后回车,这边的状态立马变成蓝色。
最后,我们要查看job运行的结果,我们切换到菜单Job Manager ,页面有个Tab标签页,切换到Log List,这里面如果有执行过得任务,那么最新的一个应该就是对应我们的这个任务。

点击out这个文件,这个是任务输出记录:

这个结果符合我们的输入。跟我们本地运行结果基本一致。
flink示例,只需要一个main函数入口即可,他运行的时候,一般是以作业的形式,提交到flink任务管理器。