该文章整理翻译自http://colah.github.io/posts/2014-10-Visualizing-MNIST/
众所周知,我们人类在二维和三维上能够理性的进行思考,通过努力,我们可以从第四维来思考。但是机器学习经常要求我们使用成千上万个维度——或者数万,或者数百万!即使是非常简单的事情,当你在非常高的维度上做的时候,也会变得难以理解。
这时,就需要一些工具的辅助。高手已经建立了工具来帮助我们。有一个完整的、发展良好的领域,称为降维,它实现了将高维数据转换成低维数据的技术。关于高维数据可视化的相关课题也做了大量工作。
这些技术就是我们需要的基本构建块,特别是如果我们希望进行可视化机器学习和深入学习。
通过可视化和更直接地观察实际发生的事情,我们可以更深入、更直接地理解神经网络。
因此,我们的首要任务是熟悉降维。要做到这一点,我们需要一个数据集来测试这些技术。
1. MNIST
MNIST是一种简单的计算机视觉数据集。它由28×28像素的手写数字图像组成,如:

每一个MNIST数据点,每一个图像,都可以被看作是一个数字数组,将每一个像素填充为黑色,如
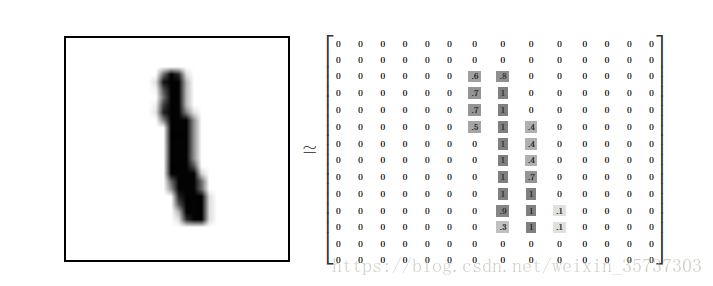
由于每个图像都有28×28个像素,所以我们得到了一个28×28的数组。我们可以将每个数组变为28×28=784维向量。矢量的每个分量是介于0和1之间的值,描述像素的强度。因此,我们通常认为MNIST是784维向量的集合。
并不是所有784维空间中的所有向量都是MNIST数据。这个空间的典型点是非常不同的!为了对一个典型点有点感觉,我们可以随机挑选几个点,并检查它们。在一个随机点上(就是随机的28×28图像)每个像素是随机的黑色,白色或一些灰色的阴影。

像MNIST数据这样的图像是非常罕见的。当MNIST数据点嵌入到784维空间中时,它们位于非常小的子空间中。通过一些稍微困难的参数,我们可以看到它们占据了更低维子空间。
人们对地位结果MNIST和相似的数据有很多理论,其中对受欢迎的就是机器学习中的歧义假设(manifold hypothesis):MNIST是一个低微多形(low dimensional manifold),通过其高维嵌入空间来扫描和弯曲。
与拓扑数据分析更相关的另一个假设是,像MNIST这样的数据是由具有突起状小突块突出到周围空间中构成的.
2 立方形MNIST
我们可以把MNIST数据点看作是悬浮在784维立方体中的点。立方体的每个维度对应于特定像素。数据点根据像素强度从0到1不等。在维度的一侧,有图像,其中像素是白色的。在维度的另一边,有一些图像是黑色的。在两者之间,有灰色的图像。

如果我们这样想,自然会出现问题。如果我们看一个特定的二维面,立方体会是什么样子?就像看雪球一样,我们看到数据点投射到两个维度,一个维度对应于一个特定像素的强度,另一个对应于第二像素的强度。检查这个使得我们以非常原始的方式探索MNIST。
在下面这个可视化中,每个点是一个MNIST数据点。点是根据数据点属于哪一类数字来着色的。当鼠标停留在一个点上时,该数据点的图像显示在每个轴上。每个轴对应于特定像素的强度,当标记和可视化后,在小图像旁边最为一个蓝色的点。通过点击图像,可以更改哪个像素显示在该轴上。

从上面我们可以看出MNIST的一些结构,注意到像素点P18,15和P7,12,我们能够分离很多零点到右下角和许多9到左上角。像素P点5、6和P7、9,我们可以看到很多的2在右上角和很多3在右下角。


另一种样式的9:

现在面临的困难是我们需要选择我们使用的角度,有一个叫做Principal Components Analysis (PCA)–主成分分析–的技术能为我们找到最好的角度,也就是说PCA会发现最大的点(捕捉尽可能多的变化)的角度。
但是,从一个角度看784维立方体是什么意思呢?我们需要决定立方体的每一个轴的倾斜方向:一个方向,另一个方向,或者介于两者之间的某个方向。
具体地说,下面是PCA选择的两个角度的图片。红色代表像素向一侧倾斜,蓝色向另一侧倾斜。

如果一个MNIST数字主要突出为红色,它就倾向一端。如果它突出主要为蓝色,它就倾向另一端。第一角度(就是”第一主要成分”)就是我们的水平角度。将1(突出大量红色少量蓝色)放到左边,将0(突出大量蓝色少量红色)放到右边。

现在我们知道了最好的水平和垂直角度,我们可以尝试从这个角度来看待立方体。
下面这个可视化很像上面的一个,但是现在轴被固定来显示第一个和第二个“主要成分”,是观察数据的基本角度。在每个轴上的图像中,蓝色和红色被用来表示那个像素的倾斜。蓝色区域中的像素强度将数据点推到一边,红色区域中的像素强度将我们推向另一个区域。


虽然比前面一个可视化操作好多了,但仍不客观。不幸的是,即使从最好的角度看数据,MNIST的数据也不能很好地反映我们的观点。这是一个非平凡的高维结构,而这些线性投影只是无法切割它。值得庆幸的是,我们有一些强大的工具来处理不合作的数据集。
3. 基于优化的降维
如果我们的可视化中的点之间的距离与原始空间中的点之间的距离相同,那就非常完美了。如果能做到这一步,我们将捕获数据的全局几何结构。
详细说就是,对于任意两个MNIST数据点,Xi和Yi,它们之间有两种距离的概念。一个是它们在原始空间中的距离,一个是它们在视觉上的距离。
我们有许多选项来定义这些高维向量之间的距离。对于这个帖子,我们将使用L2距离:
这里使用

现在就可以有下面这个定义了:

这个值描述了可视化的坏程度,它传达的信息就是:两个距离不相同不是一件好事,这种程度的坏而且还是平方级别的。如果这个值很大,意味着距离与原来的空间不一样如果它很小,就意味着它们是相似的;如果它是零,我们就有一个“完美”的嵌入。
这听起来像是一个优化问题!深度学习者知道如何处理这些!我们选择一个随机起点,并应用梯度下降。
我们通过在原点周围采样高斯来初始化点的位置。我们的优化过程不是标准梯度下降。相反,我们使用动量梯度下降的变体。 在向动量添加梯度之前,我们将梯度归一化。这减少了对超参数调谐的需要。
在原始文档中有一些可视化的图例,CSDN加载不出来,可以自行前往查看,对于这里所提到的可视化,通过鼠标可对其进行缩放


这种技术被称为多维缩放(或MDS)。首先,我们随机地将每个点定位在平面上。接下来,我们将每一对点与一个具有原始距离长度