基于PCA/LDA的数据降维和可视化
Introduction
Project Intro
1、结合实际应用理解数据降维;
2、采用PCA或LDA两种方法对数据集的数据进行降维,并进行可视化;
3、通过进一步查阅文献,了解相关研究方向的最新研究进展。
File Intro
| Files | Function |
|---|---|
| feat_before_classifier.npy | 数据集;形状为720 * 1 * 1024 ,720代表720个特征向量,每个特征向量为1 * 1024大小 |
| feat_from_resnet_set.npy | 数据集;形状为720 * 8 * 1024 ,720代表720个特征向量,每个特征向量为8 * 1024大小 |
| label.npy | 数据集;形状为720,表示720个特征向量的类别 |
| output.py | 测试文件,仅用于测试数据集以及相关函数的输出,注释部分还测试了.npy文件和.txt文件的相互转化 |
| pca_lda_dimension_reduction.py | PCA及LDA降维及可视化的实现 |
Tools Intro
Python3+VSCode
Code&Dataset Link
GitHub:Program 1:PCA_LDA_dimension_reduction
Process
Preparations of Imports
本题需要实现PCA以及LDA的降维以及可视化,我选择从二维和三维两个维度进行呈现,必不可少的是需要引入PCA库和LDA库,以及可视化图表库。
在深度学习以及机器学习中,数据集的表示形式为.npy文件,在我使用VSCode打开的时候,VSCode提示此文件是二进制文件或使用了不支持的文本编码,无法在编辑器中显示,我最初的设想为,将其转化为.txt或者.py进行显示,但是后来发现,只需要使用numpy库中的load()函数即可,所以此库也需要引入。
##用于3D可视化
from mpl_toolkits.mplot3d import Axes3D
##用于可视化图表
import matplotlib.pyplot as plt
##用于做科学计算
import numpy as np
##导入PCA库
from sklearn.decomposition import PCA
##导入LDA库
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
对于没有的库 进行pip install +库名
Initialization of data
在引入numpy库后,使用np.load()函数进行数据的引入。在output.py文件中我能了解到,#根据测试文件output.py的输出结果,可以了解到:feat_before_classifier_set.npy以及feat_from_resnet_set.npy数据集的输出结果以三维数组的方式呈现,但是:LinearDiscriminantAnalysis expected <= 2,所以要对数据集进行reshape()处理。
#加载数据集
label=np.load("label.npy") #标签信息
resnet_set=np.load("feat_from_resnet_set.npy") #用于LDA降维
classifier_set=np.load("feat_before_classifier_set.npy") #用于PCA降维
#形状重构
#根据测试文件output.py的输出结果,可以了解到:feat_before_classifier_set.npy以及
# feat_from_resnet_set.npy数据集的输出结果以三维数组的方式呈现
#但是:LinearDiscriminantAnalysis expected <= 2.
resnet_reshape=resnet_set.reshape(720,8*1024)
classifier_reshape=classifier_set.reshape(720,1*1024)
在前面的准备做好之后,便可以进行PCA和LDA的降维实现了。在实现时,分别调用PCA和LinearDiscriminantAnalysis库中的fit_transform()函数即可,若要指定二维还是三维进行呈现,改变n_components=2or3。然后分别进行训练。
注意:下面代码存在重复部分,请根据自己的要求进行更改
PCA
two-dimensional
绘制二维散点图:
#加载PCA模型并训练,降维
#注意:PCA为无监督学习 无法使用类别信息来降维
model_pca=PCA(n_components=2) #二维
X_pca=model_pca.fit_transform(classifier_reshape) #降维后的数据
X_pca=model_pca.fit_transform(resnet_reshape)
#绘图
labels=[0,1,2,3,4,5]
Colors=['red','orange','yellow','green','blue','purple']
label_express=['anger', 'disgust','fear','happy','sad','surprise'] #0-5对应的标签含义
#二维散点图
#初始化画布
plt.figure(figsize=(8, 6), dpi=80) # figsize定义画布大小,dpi定义画布分辨率
plt.title('Transformed samples via sklearn.decomposition.PCA')
#分别确定x和y轴的含义及范围
plt.xlabel('x_values')
plt.ylabel('y_values')
plt.xlim([-60,60])
plt.ylim([-40,60])
# 为了不同标签的数据显示不同颜色 不能对读取数据list直接进行输入
# 需要每一个点进行label判断 根据对应数字进行绘制
# 若label情况较少 可采取包含list直接输入的([:,0]/[:,1])其他方法
for tlabel in labels:
# pca读取数据
x_pca_data=X_pca[label==tlabel,0]
y_pca_data=X_pca[label==tlabel,1]
plt.scatter(x=x_pca_data,y=y_pca_data,s=20,c=Colors[tlabel],label=label_express[tlabel])
plt.legend(loc="upper right") #输出标签信息在右上角
plt.grid()
plt.show()
three-dimensional
绘制三维散点图:
#加载PCA模型并训练,降维
#注意:PCA为无监督学习 无法使用类别信息来降维
model_pca=PCA(n_components=3) #三维
X_pca=model_pca.fit_transform(resnet_reshape,label)
X_pca=model_pca.fit_transform(classifier_reshape,label)
#绘图
labels=[0,1,2,3,4,5]
Colors=['red','orange','yellow','green','blue','purple']
label_express=['anger', 'disgust','fear','happy','sad','surprise'] #0-5对应的标签含义
#三维散点图
#初始化画布
fig=plt.figure(figsize=(8, 6), dpi=80) # figsize定义画布大小,dpi定义画布分辨率
ax =fig.add_subplot(111,projection='3d')
ax.set_title('Transformed samples via sklearn.decomposition.PCA')
#分别确定x和y轴的含义及范围
ax.set_xlabel('x_value')
ax.set_ylabel('y_value')
ax.set_zlabel('z_value')
for tlabel in labels:
#pca读取数据
x_pca_data=X_pca[label==tlabel,0]
y_pca_data=X_pca[label==tlabel,1]
z_pca_data=X_pca[label==tlabel,2]
ax.scatter(xs=x_pca_data,ys=y_pca_data,zs=z_pca_data,s=20,c=Colors[tlabel],label=label_express[tlabel])
plt.legend(loc="upper right") #输出标签信息在右上角
plt.show()
LDA
two-dimensional
绘制二维散点图:
#加载LDA模型并训练,降维
#LDA为监督学习 需要使用标签信息
model_lda=LinearDiscriminantAnalysis(n_components=2) #二维
X_lda=model_lda.fit_transform(resnet_reshape,label)
X_lda=model_lda.fit_transform(classifier_reshape,label)
print("各主成分的方差值:",model_lda.explained_variance_) #打印方差
print("各主成分的方差贡献率:",model_lda.explained_variance_ratio_) #打印方差贡献率
#绘图
labels=[0,1,2,3,4,5]
Colors=['red','orange','yellow','green','blue','purple']
label_express=['anger', 'disgust','fear','happy','sad','surprise'] #0-5对应的标签含义
#二维散点图
#初始化画布
plt.figure(figsize=(8, 6), dpi=80) # figsize定义画布大小,dpi定义画布分辨率
plt.title('Transformed samples via sklearn.decomposition.LDA')
#分别确定x和y轴的含义及范围
plt.xlabel('x_values')
plt.ylabel('y_values')
plt.xlim([-60,60])
plt.ylim([-40,60])
# 为了不同标签的数据显示不同颜色 不能对读取数据list直接进行输入
# 需要每一个点进行label判断 根据对应数字进行绘制
# 若label情况较少 可采取包含list直接输入的([:,0]/[:,1])其他方法
for tlabel in labels:
# lda读取数据
x_lda_data=X_lda[label==tlabel,0]
y_lda_data=X_lda[label==tlabel,1]
plt.scatter(x=x_lda_data,y=y_lda_data,s=20,c=Colors[tlabel],label=label_express[tlabel])
plt.legend(loc="upper right") #输出标签信息在右上角
plt.grid()
plt.show()
three-dimensional
绘制三维散点图:
#加载LDA模型并训练,降维
#LDA为监督学习 需要使用标签信息
model_lda=LinearDiscriminantAnalysis(n_components=3)
X_lda=model_lda.fit_transform(resnet_reshape,label)
X_lda=model_lda.fit_transform(classifier_reshape,label)
print("各主成分的方差值:",model_lda.explained_variance_) #打印方差
print("各主成分的方差贡献率:",model_lda.explained_variance_ratio_) #打印方差贡献率
#绘图
labels=[0,1,2,3,4,5]
Colors=['red','orange','yellow','green','blue','purple']
label_express=['anger', 'disgust','fear','happy','sad','surprise'] #0-5对应的标签含义
#三维散点图
#初始化画布
fig=plt.figure(figsize=(8, 6), dpi=80) # figsize定义画布大小,dpi定义画布分辨率
ax =fig.add_subplot(111,projection='3d')
ax.set_title('Transformed samples via sklearn.decomposition.LDA')
#分别确定x和y轴的含义及范围
ax.set_xlabel('x_value')
ax.set_ylabel('y_value')
ax.set_zlabel('z_value')
for tlabel in labels:
# lda读取数据
x_lda_data=X_lda[label==tlabel,0]
y_lda_data=X_lda[label==tlabel,1]
z_lda_data=X_lda[label==tlabel,2]
ax.scatter(xs=x_lda_data,ys=y_lda_data,zs=z_lda_data,s=20,c=Colors[tlabel],label=label_express[tlabel])
plt.legend(loc="upper right") #输出标签信息在右上角
plt.show()
Visualization
feat_from_resnet_set.npy:
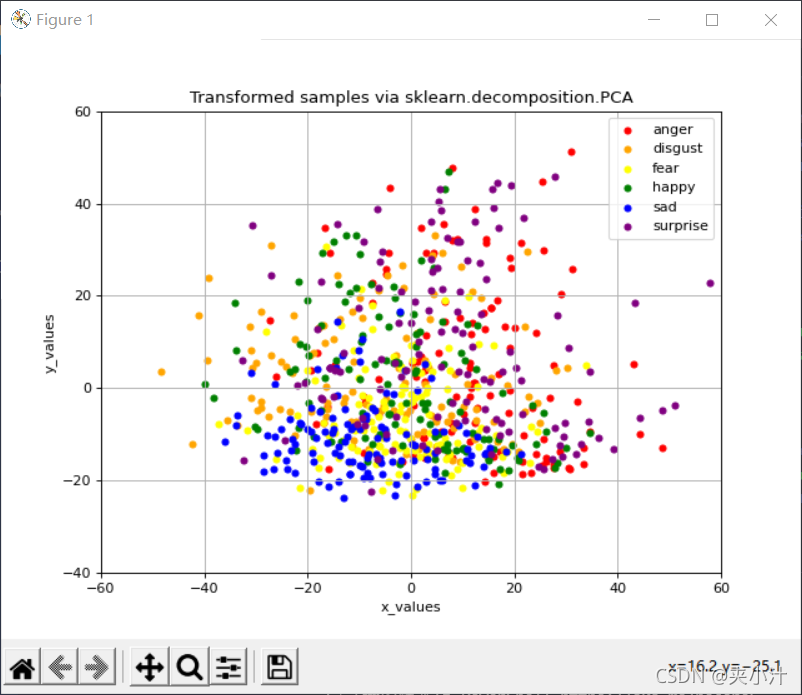


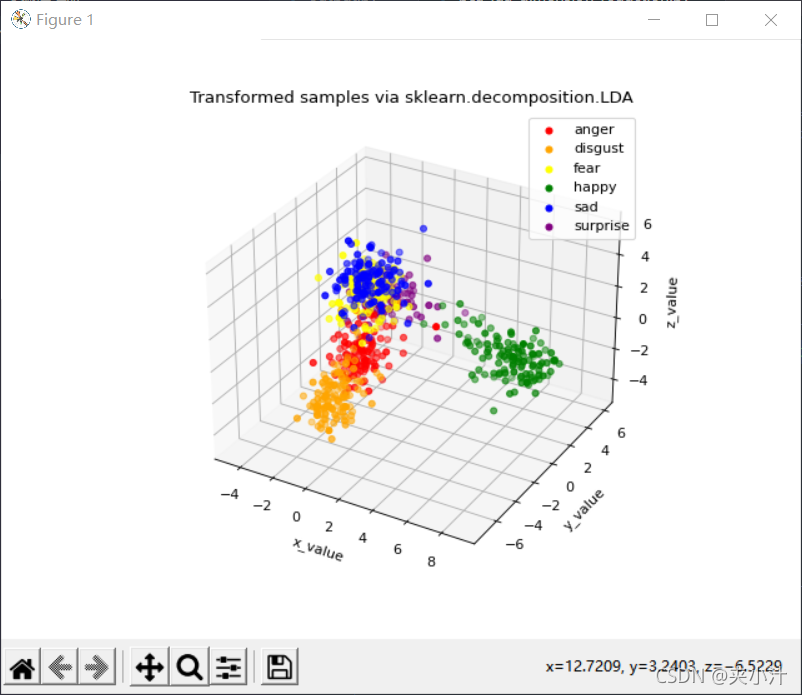
feat_before_classifier_set.npy:
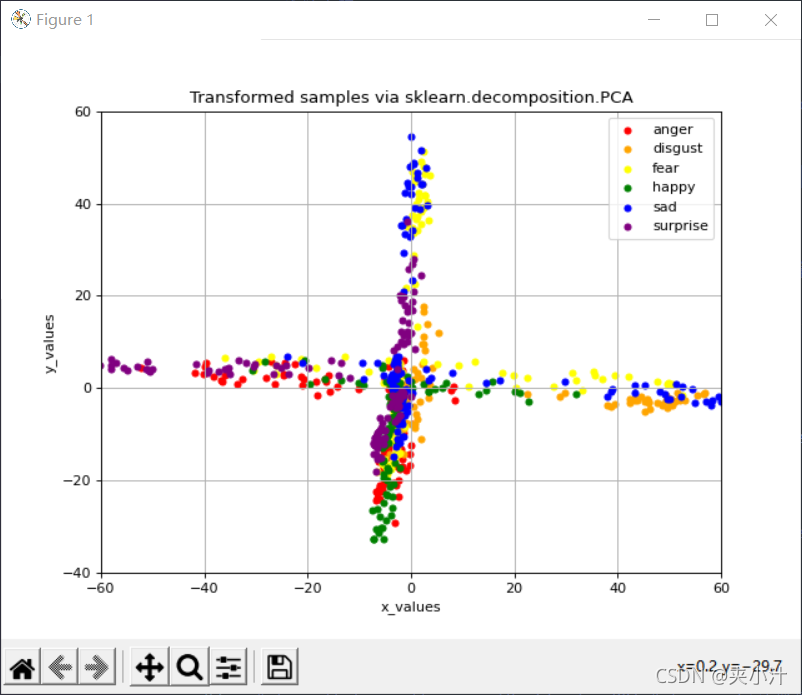
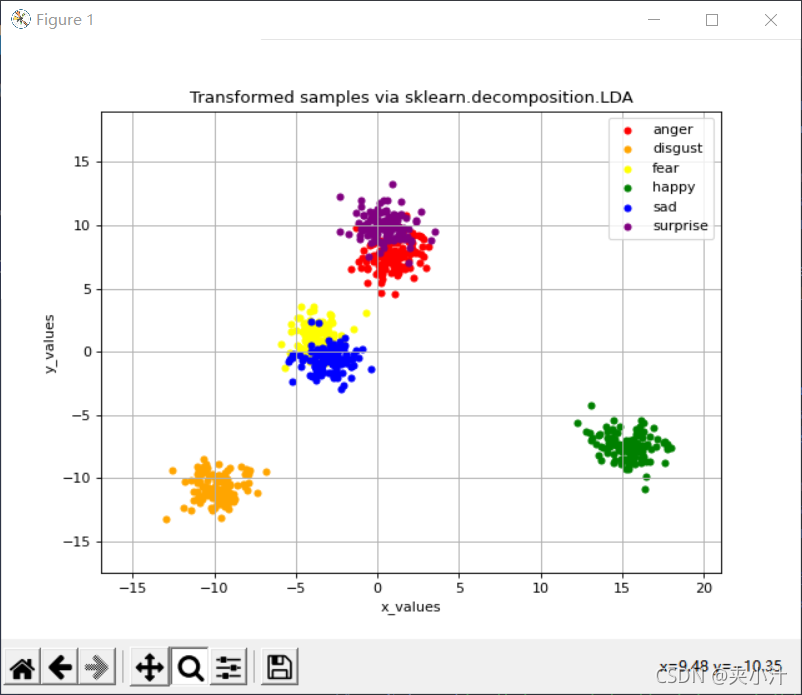

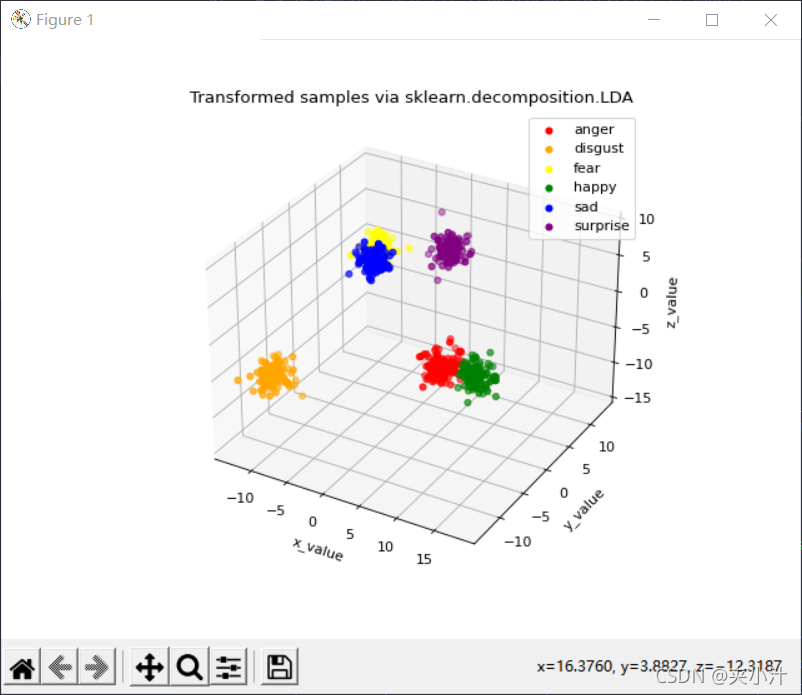
Comparsion
根据训练模型的可视化结果,对于feat_from_resnet_set.npy和feat_before_classifier_set.npy文件,更适合使用LDA进行降维,因为这样呈现的数据分类更加明确。
Conclusion
本次实习中,我学习到了PCA与LDA降维的基本原理,以及可视化库的运用,让我在这个入门实验上对之前认为一头雾水的机器学习产生了一些兴趣。我在本次实验中还有许多不足之处,比如:应该做更充足的数据分析;在文件部分可以将每个模块进行细化,因为在同一文件中进行注释很浪费时间等。
作为一名机器学习小白,此次实验也暴露出来我很多问题,欢迎各位前来批评指正!
Reference
1、.npy文件
2、python读取txt文件并转换成数值型数组以及如何将数值型数组存入txt文件
3、python实现npy格式文件转换为txt文件
4、Numpy中reshape函数、reshape(1,-1)的含义(浅显易懂,源码实例)
5、python绘图基础—scatter用法
6、使用Python一步步实现PCA算法
7、【机器学习实战】降维方法的sklearn实现----PCA和LDA