复制链接1
复制链接
import pandas as pd
cust_sale=pd.read_excel('C:/Users/XI/fzql.xls')
cust_sale=pd.merge(temp1,temp2,on='CUST_ID',how='inner')
cust_sale=cust_sale.dropna()
cust_sale.head()
import sklearn.preprocessing as preprocessing#方法一
min_max_scaler = preprocessing.MinMaxScaler()
cust_sale.loc[:,['特征一','特征二','特征三','特征四','特征五']]=min_max_scaler.fit_transform(cust_sale[['特征一','特征二','特征三','特征四','特征五']].values)#数据归一化,按比例映射到(01)区间
cust_sale.head()
from sklearn import preprocessing#方法二
cust_sale=cust_sale.dropna()
cust_sale[['特征一','特征二','特征三','特征四','特征五']] = preprocessing.scale(cust_sale[['特征一','特征二','特征三','特征四','特征五']])#指定均值方差按列标准化!(默认mean=0,std=1)
print('mean:', cust_sale[["特征一","特征二"]].mean(axis=0), '\nstd:', cust_sale[["特征一","特征二"]].std(axis=0))
cust_sale.head()
#-------KMeans聚类-------
%matplotlib inline
from sklearn.cluster import KMeans
from sklearn import metrics
import numpy as np
import matplotlib.pyplot as plt
#df_onehot_pred = clf.fit_predict(df_onehot)
RS = 20180101
Silhouette_scores=[]
Calinski_Harabaz_scores=[]
for i in np.arange(2,11):
kmeans_model = KMeans(n_clusters=i).fit(cust_sale["特征一"].values.reshape(-1,1)) #单个特征要reshape(-1,1)
labels = kmeans_model.labels_
Silhouette_scores.append(metrics.silhouette_score(cust_sale["特征一"].values.reshape(-1,1),labels,metric='euclidean'))
Calinski_Harabaz_scores.append(metrics.calinski_harabaz_score(cust_sale["特征一"].values.reshape(-1,1),labels))
print('Silhouette:%f' %metrics.silhouette_score(cust_sale["特征一"].values.reshape(-1,1),labels,metric='euclidean'))
print('Calinski_Harabaz:%0.3f'% metrics.calinski_harabaz_score(cust_sale["特征一"].values.reshape(-1,1),labels))
pd.DataFrame(Silhouette_scores,index=np.arange(2,11),columns=['metric']).plot(subplots=True,figsize=(10,5),grid=True,title="silhouette_score")
pd.DataFrame(Calinski_Harabaz_scores,index=np.arange(2,11),columns=['metric']).plot(subplots=True,figsize=(10,5),grid=True,title="Calinski_Harabaz_scores")
pd.merge(cust_sale,pd.DataFrame(labels,index=cust_sale.index,columns=['Y']),left_index=True,right_index=True).to_csv('C:/Users/4-6_second.csv', index=None)
plt.show()
print(pd.DataFrame(labels,index=cust_sale.index,columns=['Y'])['Y'].value_counts())
import numpy as np
import sklearn
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import matplotlib.patheffects as PathEffects
import matplotlib
RS = 20190101 #Random state
import seaborn as sns
sns.set_style('darkgrid')
sns.set_palette('muted') #调色板颜色温和
sns.set_context("notebook", font_scale=1.5,
rc={"lines.linewidth": 2.5})
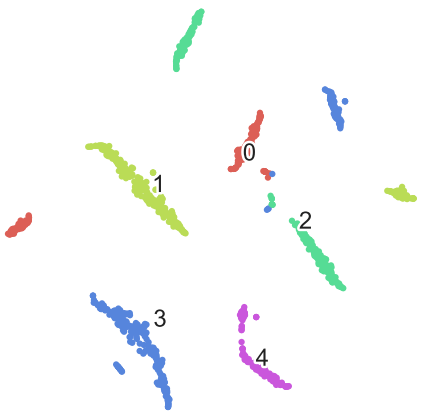
X = cust_sale.iloc[:,1:6].values
y = labels
digits_proj = TSNE(random_state=RS).fit_transform(X) #将X降到2维
def scatter(x, colors):
palette = np.array(sns.color_palette("hls", 5))
f = plt.figure(figsize=(8, 8))
ax = plt.subplot(aspect='equal')
sc = ax.scatter(x[:,0], x[:,1], lw=0, s=40,
c=palette[colors.astype(np.int)])
plt.xlim(-25, 25)
plt.ylim(-25, 25)
ax.axis('off')
ax.axis('tight')
#给类群点加文字说明
txts = []
for i in range(5):
xtext, ytext = np.median(x[colors == i, :], axis=0) #中心点
txt = ax.text(xtext, ytext, str(i), fontsize=24)
txt.set_path_effects([PathEffects.Stroke(linewidth=5, foreground="w"),PathEffects.Normal()]) #线条效果
txts.append(txt)
return f, ax, sc, txts
scatter(digits_proj, y)
#plt.savefig('digits_tsne-generated.png', dpi=120)
plt.show()