算法:排序算法之桶排序、计数排序与基数排序C、Java、Python表述
写的有点多,有些地方可以跳过
推荐
算法可视化网站:https://visualgo.net/zh/sorting
数据结构可视化 https://visualgo.net/zh/sorting
Data Structure Alghoritm Animation:https://dsa.rainboy.cc/#/
1. 桶排序
桶排序(Bucket sort),是一种较为高效的排序算法。桶排序的思想近乎彻底的分治思想。桶排序的时间复杂度在最坏情况下为Tworst(N) = O(N)。桶排序从 1956 年就开始被使用,该算法的基本思想是由 E.J.Issac R.C.Singleton 提出来。
分析:
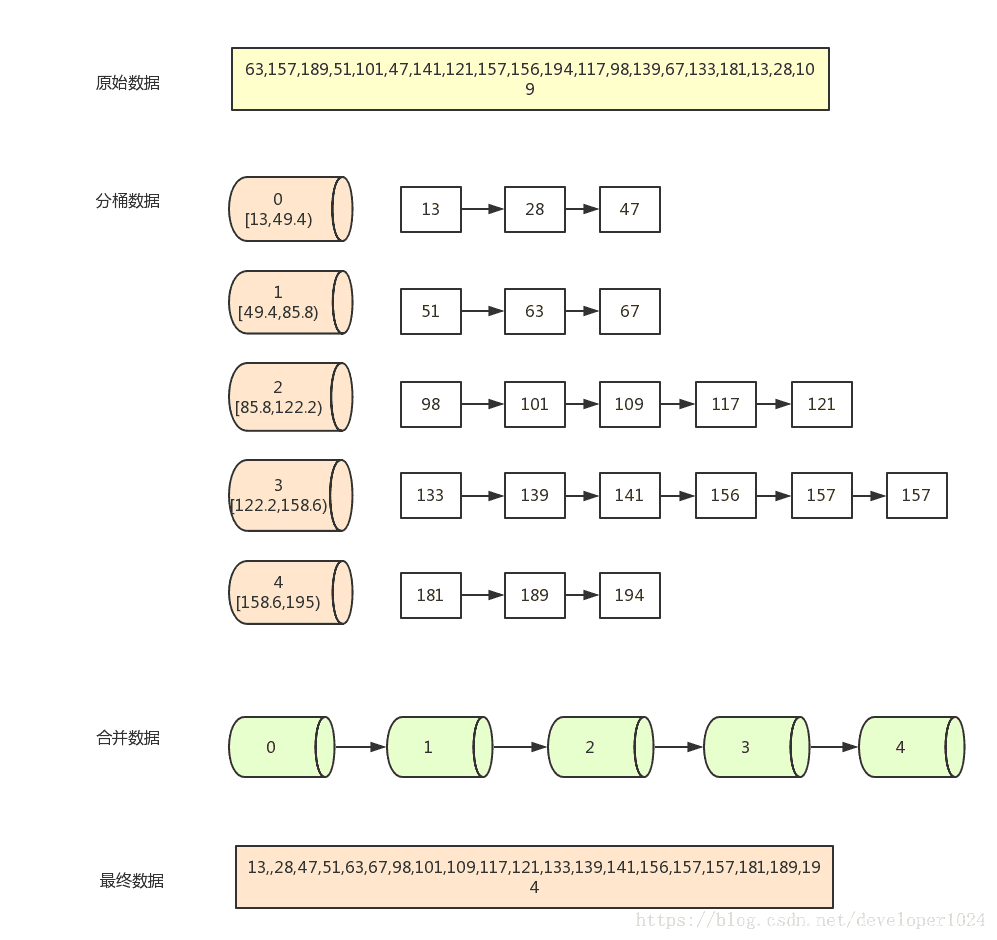
桶排序假设待排序集合(可以是一组实数)独立的分布在一个范围中,
然后根据某种映射将待排序集合中处于同一个值域的元素存入同一个桶中,也就是根据元素值特性将集合拆分为多个区域,则拆分后形成的多个桶,从值域上看是处于有序状态的。对每个桶中元素进行排序,则所有桶中元素构成的集合是已排序的。
映射函数一般是 F(i) = Array[i] / K; K2 = N; N是所有元素个数
一组待排数A[0]….A[N-1] [MaxValue, MinValue],将[MaxValue, MinValue]分为K个区间(1~k),由F(i)得到元素A[i]在桶中的位置k,将元素放到对应的桶中。
接着将各个桶中的数据有序的合并起来 : 对每个桶B[k] 中的所有元素进行排序(可以选择任意一种排序算法)。然后依次枚举输出 B[0]….B[K-1] 中的全部内容即是一个有序序列。
复杂度分析
假设数据是均匀分布的,则每个桶的元素平均个数为
。假设选择用快速排序对每个桶内的元素进行排序,那么每次排序的时间复杂度为 O(
log(
)) 。总的时间复杂度为 O(N)+O(K)O(
*log(
)) = O(N+Nlog(
)) = O(N+N*logN-N*logK)(分配到相应的桶:O(N),对K个桶排序取上界:O(K)O(
*log(
)))。当 K 趋近于 N 时,桶排序的时间复杂度就可以近似认为是 O(N) 的。
(注:K: 桶的数量,N: 待排序元素个数)
所以在效率和空间上
桶的数量越多空间占用越多,但时间效率越高。
相当于与牺牲空间来减少比较的次数从而提高效率,因为基于比较排序的最好平均时间复杂度只能达到Ω(N*logN)
有一个有趣的事情:
当K = N是,桶排序就变成了计数排序
而当K = 1时桶排序向比较性质排序算法演化,对集合进行堆排序,并将元素移动回初始集合,复杂度为 O(N+N*logN)
实现逻辑:
- 根据待排序集合中最大元素和最小元素的区间范围和映射规则,确定申请的桶个数K
- 遍历待排序集合,将每一个元素移动到对应的桶中
- 对每一个桶中元素进行排序,并移动到已排序集合中,由于已排序的元素在桶中,所以直接将桶中元素移动回原始集合即可。
复杂度分析
(注:K: 桶的数量,N: 待排序元素个数)
时间复杂度:O(N+NlogN-NlogK)
最坏时间复杂度:O(N*logN)
空间复杂度:O(N + K)(查资料的),但我算实际上最坏为O(N*K)
稳定性:稳定
动图演示:
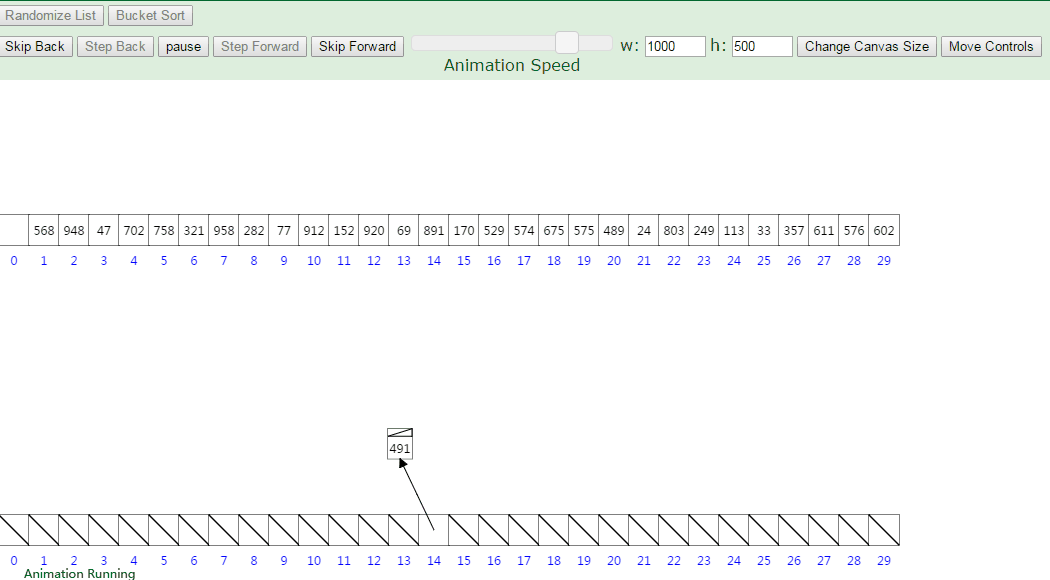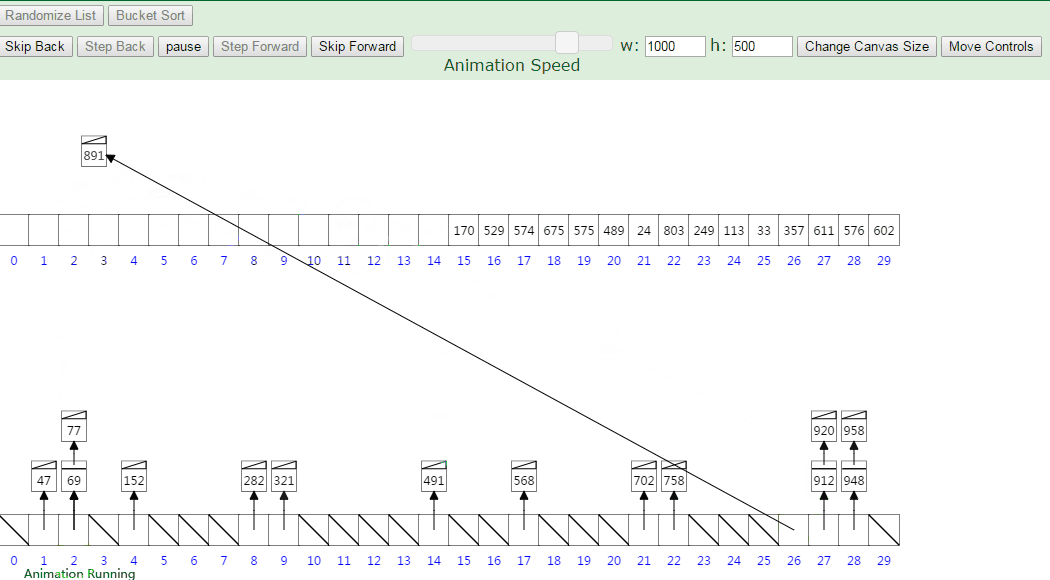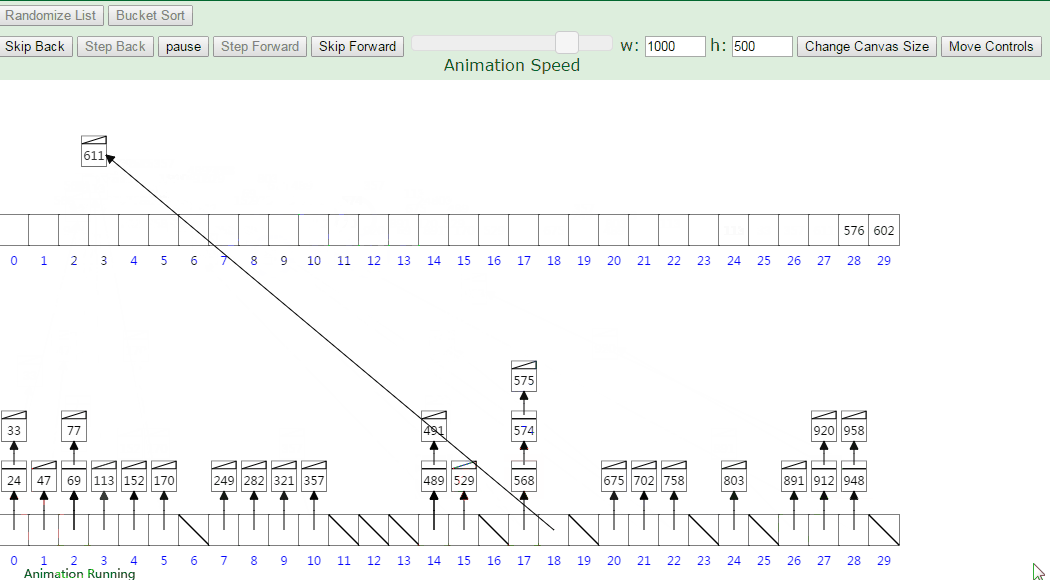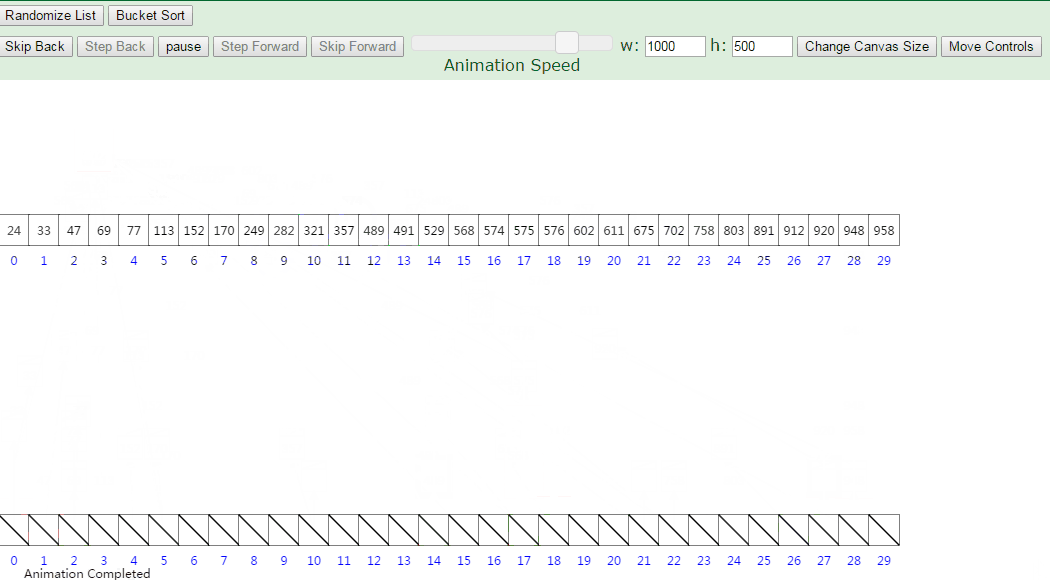
Array = [63, 157, 189, 51, 101, 47, 141, 121, 157, 156, 194, 117, 98, 139, 67, 133, 181, 13, 28, 109]
桶排序优缺点:
桶排序适用数据范围
桶排序可用于最大最小值相差较大的数据情况,比如[9012,19702,39867,68957,83556,102456]。
但桶排序要求数据的分布尽量均匀,否则可能导致数据都集中到一个桶中。比如[104,150,123,132,20000], 这种数据会导致前4个数都集中到同一个桶中。导致桶排序失效。
代码实现
#python
def BucketSort(arr):
MaxValue, MinValue = max(arr), min(arr)
Bucket = [[] for i in range(MaxValue // 10 - MinValue // 10 + 1)] # set the map rule and apply for space
for i in arr: # map every element in array to the corresponding bucket
index = i // 10 - MinValue // 10
Bucket[index].append(i)
arr.clear()
for i in Bucket:
heapSort(i) # sort the elements in every bucket
arr.extend(i) # move the sorted elements in bucket to array
//C实现C99
void
BucketSort(int Array[], int ArrayLength, int BucketNum)
{
//创建Bucket时,在二维中增加一组标识位,其中Bucket[x, 0]表示这一维所包含的数字的个数
//通过这样的技巧可以少写很多代码
int Bucket[BucketNum][ArrayLength+1];
for(int i = 0;i<BucketNum;i++)
Bucket[i][0] = 0;
int k = 0;//桶的标号
for(int i = 0;i<ArrayLength;i++)
{
k = Array[i]/BucketNum;
Bucket[k][++Bucket[k][0]] = Array[i];
}
//为桶里的每一行使用插入排序
for(int i = 0;i<BucketNum;i++)
InsertionSort(&Bucket[i][1],Bucket[i][0]);//插入排序
int count = 0;
//将所有桶里的数据回写到原数组中
for (int i = 0; i < BucketNum; i++) {
for (int j = 1; j <= Bucket[i][0]; j++) {
Array[count++] = Bucket[i][j];
}
}
}
void
InsertionSort(int A[], int N)
{
int j,P;
int Temp;
for(P = 1;P < N;P++)
{
Temp = A[P];
for(j = P;j > 0 && A[ j - 1 ] > Temp; j--)
A[ j ] = A[ j - 1 ];
A[ j ] = Temp;
}
}
public static void BucketSort(int[] arr){
int MaxValue = Integer.MIN_VALUE;
int MinValue = Integer.MAX_VALUE;
for(int i = 0; i < arr.length; i++){
MaxValue = Math.MaxValue(MaxValue, arr[i]);
MinValue = Math.MinValue(MinValue, arr[i]);
}
//桶数
int BucketNum = (MaxValue - MinValue) / arr.length + 1;
ArrayList<ArrayList<Integer>> Bucket = new ArrayList<>(BucketNum);
for(int i = 0; i < BucketNum; i++){
Bucket.add(new ArrayList<Integer>());
}
//将每个元素放入桶
for(int i = 0; i < arr.length; i++){
int num = (arr[i] - MinValue) / (arr.length);
Bucket.get(num).add(arr[i]);
}
//对每个桶进行排序
for(int i = 0; i < Bucket.size(); i++){
Collections.sort(Bucket.get(i));
}
System.out.println(Bucket.toString());
}
//C#->https://editor.csdn.net/md?articleId=104012776
总的来说桶排序算法思想和散列中的开散列法差不多,当冲突时放入同一个桶中;可应用于数据量分布比较均匀,或比较侧重于区间数量时。高效与否关键就在于这个映射函数F的确定。即建桶,如果桶设计得不好的话桶排序是几乎没有作用的。通常情况下,上下界有两种取法,第一种是取一个10n或者是2n的数,方便实现。另一种是取数列的最大值和最小值然后均分作桶.
2. 计数排序
计数排序时最快最简单的排序,时间复杂度在最坏情况下为Tworst(N) = O(N)。
基本思路:
假设待排数Array[N] = A[0]….A[N-1]
[MaxValue, MinValue]
- 开辟一个大小为MaxValue - MinValue + 1的数组,即桶Bucket[MaxValue - MinValue + 1](假设初始化为零)。
- 扫描一遍原始数组Array[N],以当前值Array[i] - MinValue作为下标k,将该下标对应的桶自增一Bucket[k]++;
- 最后扫描一遍桶,按顺序把值收集起来(收集过程见下图)
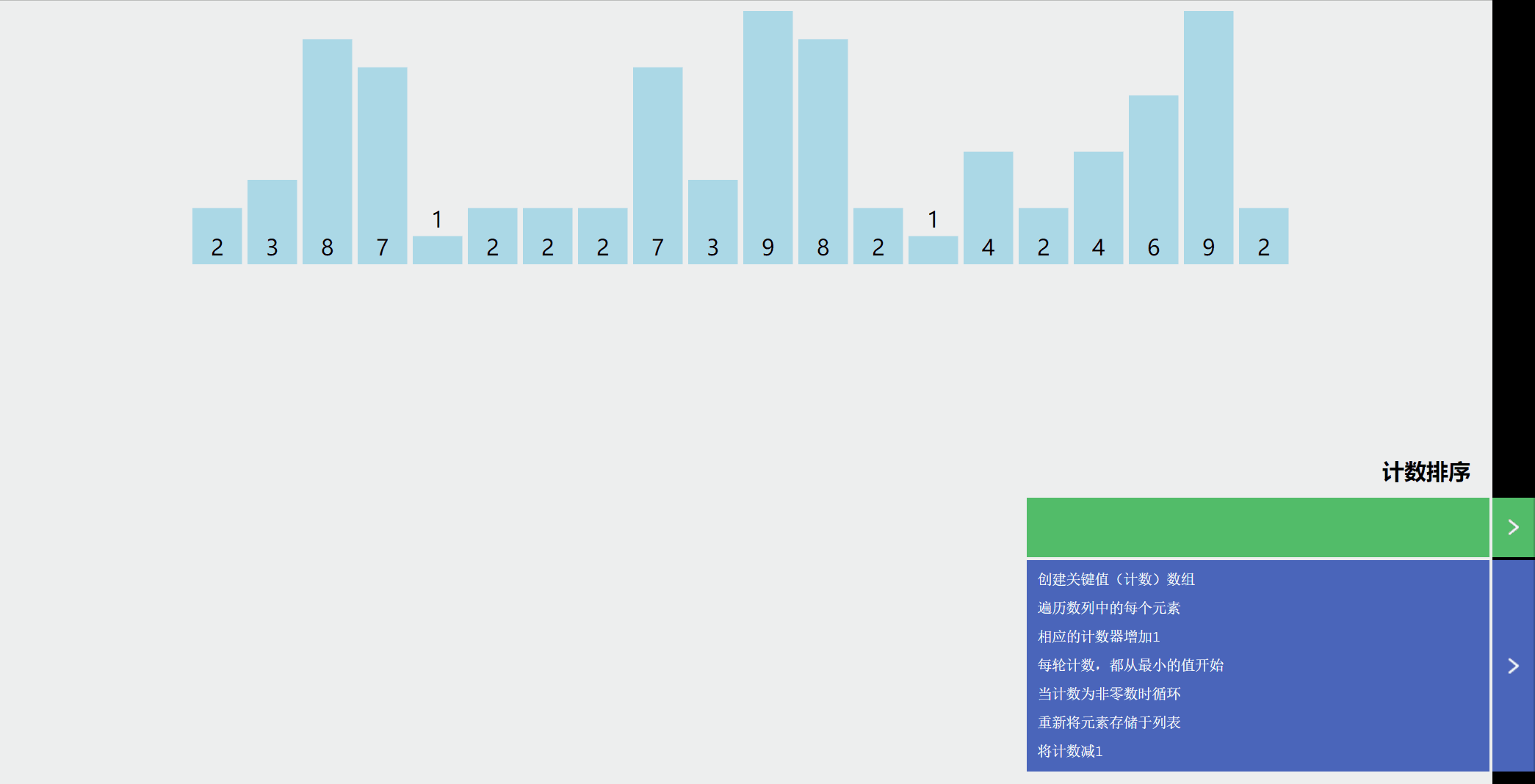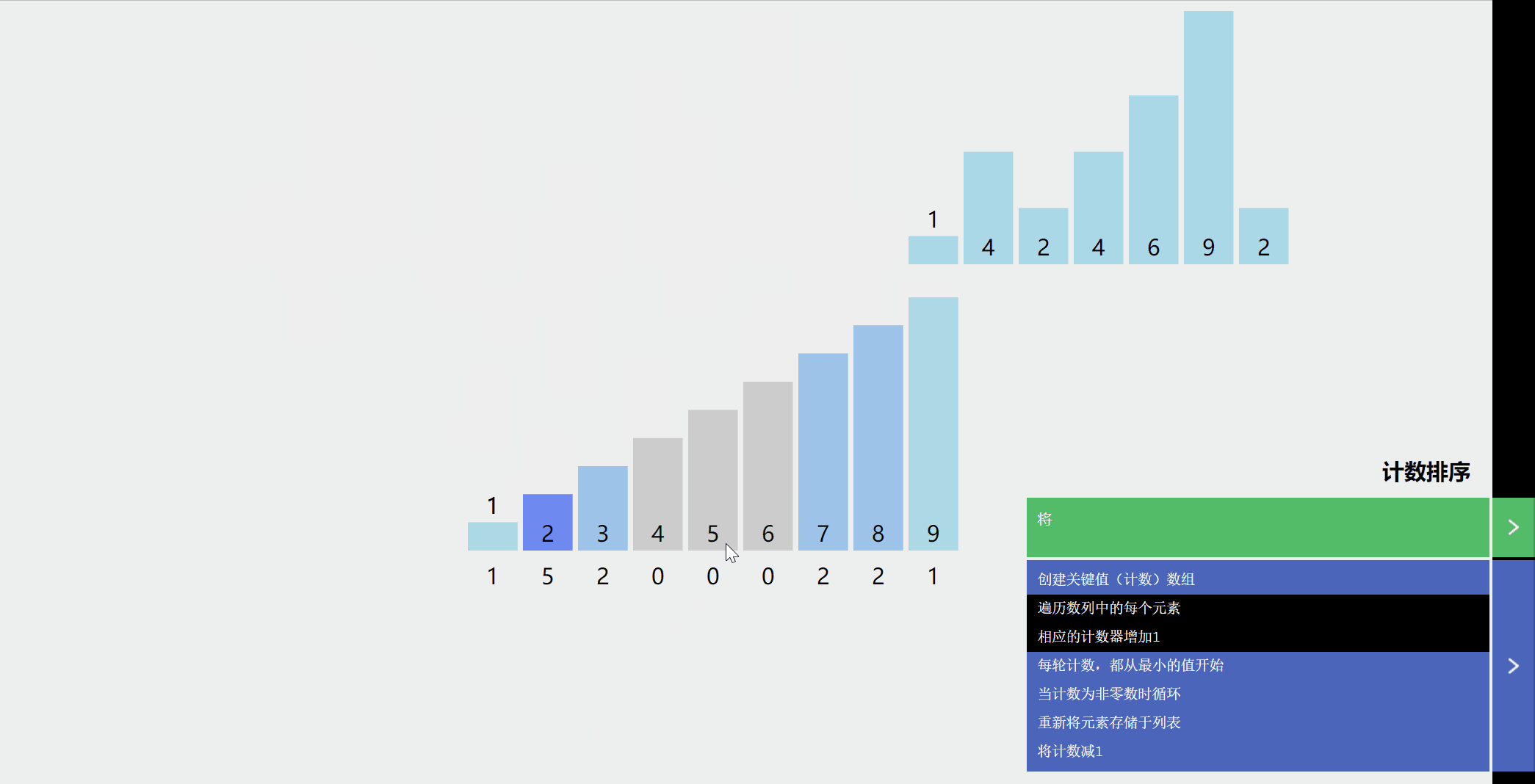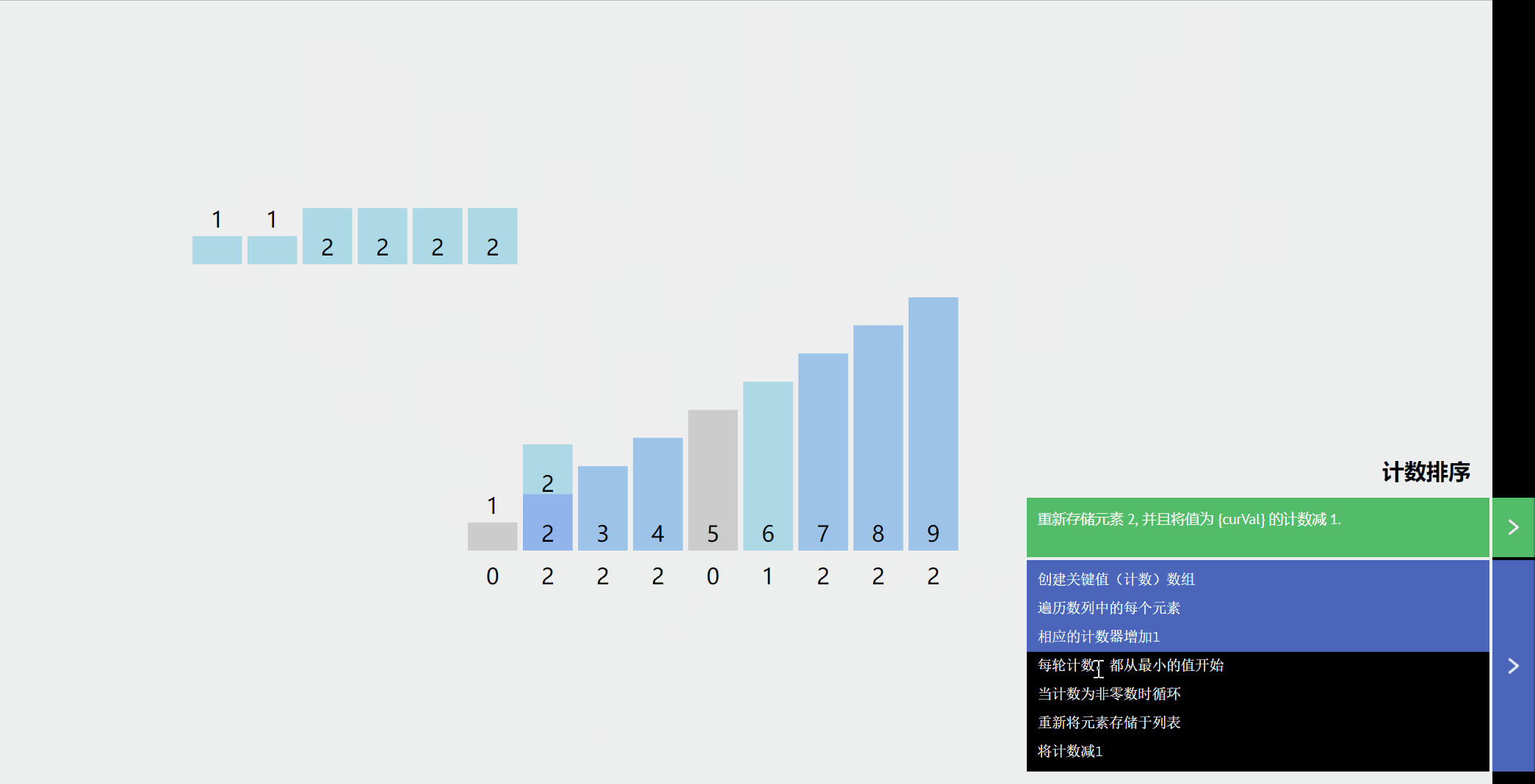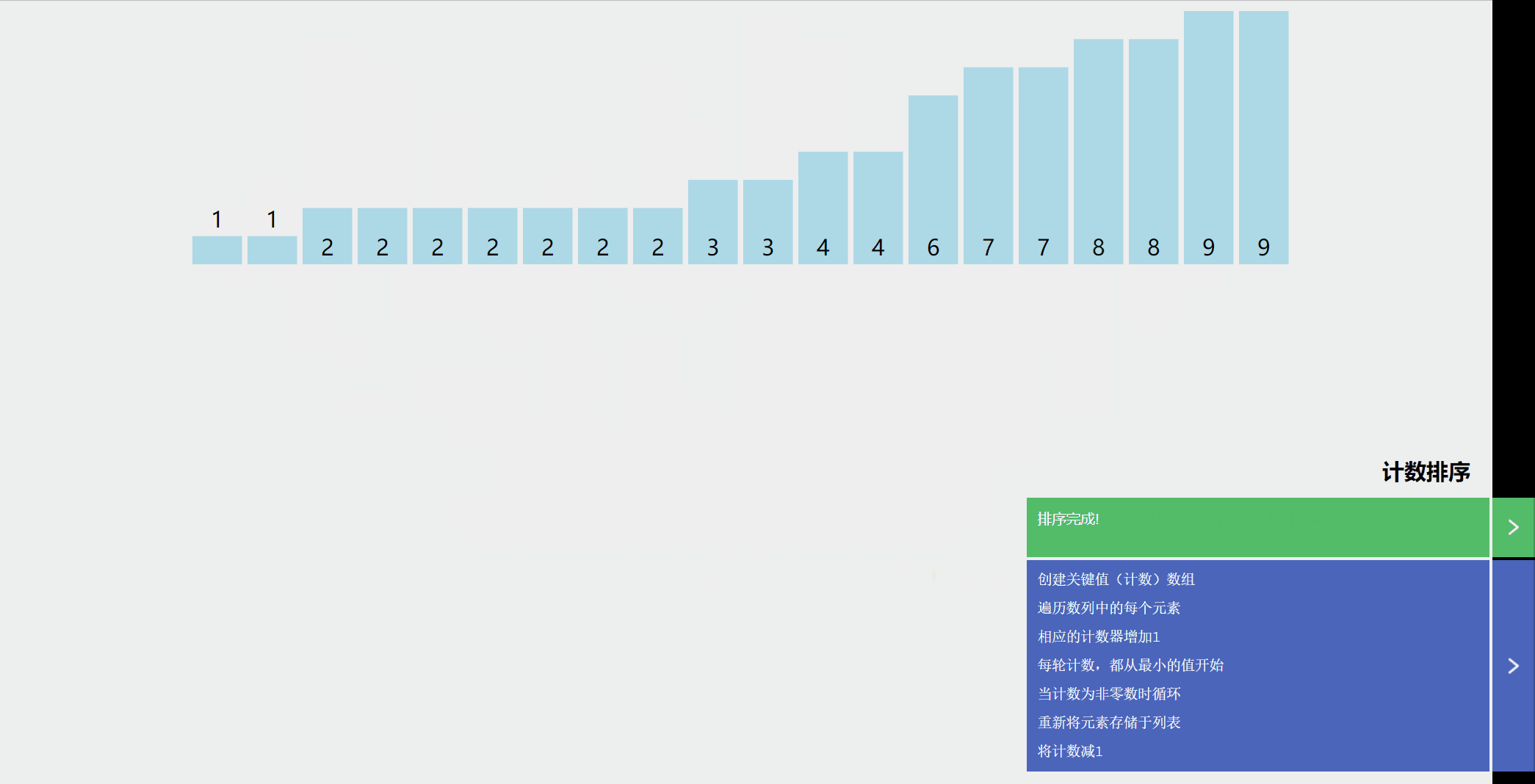
举个例子:
- 假设待排数Array[5] = 5,3,5,2,8
- 那么N = 5,MaxValue = 8, MinValue = 2
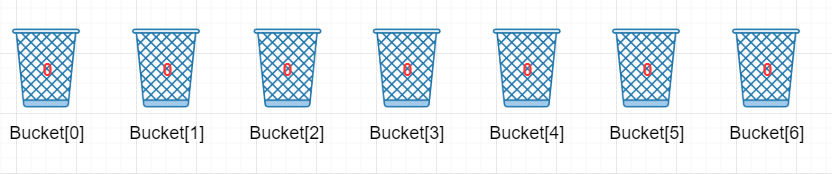
- 于是我们开辟一个大小为8 - 2 + 1 = 7 的桶Bucket[7], 初始化为0。(其实桶的大小只要比MaxValue - MinValue + 1大就行这里10个)
- 开始排序
这是桶
扫描一遍Array[N]
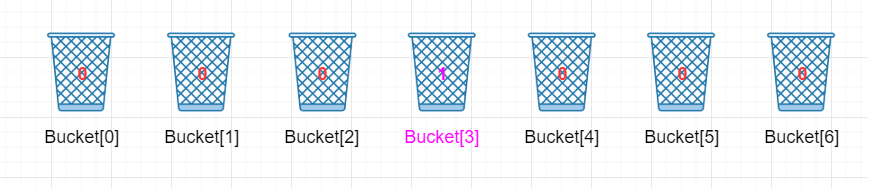
第一个元素是5,于是相应的k = 5 - 2 = 3, Bucket[3]在原理的基础上加一,即Bucket[3]的值从 0 改为 1,表示 5 出现过了一次。
第二个元素 3 ,我们就把相对应k = 3 - 2 = 1,Bucket[1]的值在原来的基础上增加 1,Bucket[1]的值从 0 改为 1,表示 3 出现过了一次。
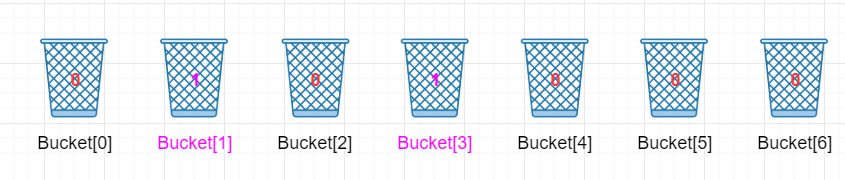
注意啦!第三元素也是“5 ”,所以Bucket[5 - 2]在原理的基础上再增加 1,即将Bucket[3]的值从 1 改为 2。表示 5 分出现过了两次。
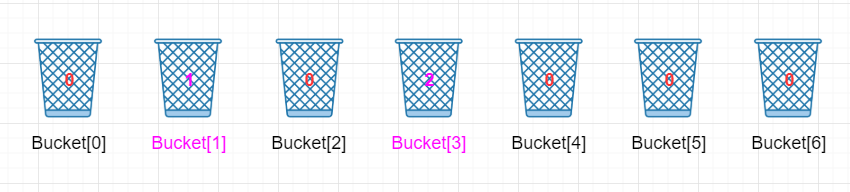
以此类推,处理第四个和第五个元素
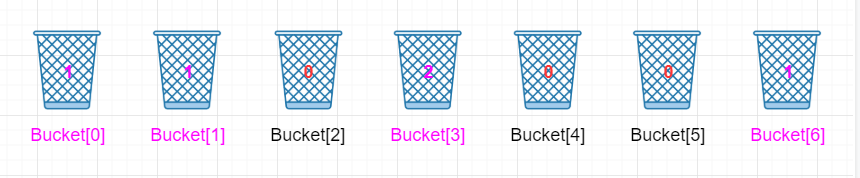
显然,Bucket[0]~Bucket[6]中的数值其实就是 MinValue =2 到 MaxValue = 8 每元素出现的次数。接下来,我们只需要将出现过的元素打印出来就可以了,出现几次就打印几次,具体如下。
以为都减了一个MinValue ,所以Bucket[i]为i+MinValue,表示“i+MinValue”出现的次数,于是
Bucket[0]为 1,表示“2”出现过 1 次,打印 2。
Bucket[1]为 1,表示“3”出现过 1 次,打印 3。
Bucket[2]为 0,表示“4”没有出现过,不打印。
Bucket[3]为 2,表示“5”出现过 2 次,打印5 5。
Bucket[4]为 0,表示“6”没有出现过,不打印。
Bucket[5]为 0,表示“7”没有出现过,不打印。
Bucket[6]为 1,表示“8”出现过 1 次,打印 8。
Bucket[7]为 0,表示“9”没有出现过,不打印。
最终屏幕输出“2 3 5 5 8”,排序完成
所以计数排序其实就是桶排序取极限的情况,即从每个桶代表一个区间取极限变为每个桶代表一个实数。
其次是网络各博文中流程的桶排序算法实际上都是计数排序,并非标准的桶排序
计数排优缺点:
计数排序需要占用大量空间,它仅适用于数据比较集中的情况。比如 [0~ 100],[10000 ~19999] 这样的数据。
复杂度分析:
时间复杂度为O(N)来计算频率,O(N + K)以排序顺序输出结果,其中 K 是输入的整数范围,在本例中为K = MaxValue - MinValue + 1。
计数排序(Counting Sort)的时间复杂度为O(N + K),如果 K 很小,那么它就是O(N)
空间复杂度:O()
算法实现:
//C99
//计数排序(Counting Sort)
void CountingSort(int Array[], int ArrayLength)
{
int MaxValue = Max(Array,ArrayLength);
int MinValue = Min(Array,ArrayLength);
//更贴切的名字 bok(book 这个单词有记录、标记的意思)
int *Bucket = (int*)malloc(sizeof(int)*(MaxValue - MinValue + 1));
//C99支持变长数组(Variable Length Arrays)
//Bucket[MaxValue - MinValue + 1];
for(int i = 0;i<MaxValue - MinValue + 1;i++)
Bucket[i] = 0;
//下面的部分才计入排序所需的时间
//扫描计数
for(int i = 0;i<ArrayLength;i++)
Bucket[Array[i] - MinValue]++;
//最后依次取出桶中排好序的元素放回数组
int k = 0;
for(int i = 0;i<MaxValue - MinValue + 1;i++)
for(int j = 0; j< Bucket[i]; j++)
Array[k++] = i+MinValue;//依次打印
}
int Max(int Array[], int ArrayLength)
{
int Tmp = Array[0];
for(int i = 0;i<ArrayLength;i++)
if(Array[i] > Tmp)
Tmp = Array[i];
return Tmp;
}
int Min(int Array[], int ArrayLength)
{
int Tmp = Array[0];
for(int i = 0;i<ArrayLength;i++)
if(Array[i] < Tmp)
Tmp = Array[i];
return Tmp;
}
//Java
public static int[] CountingSort(int[] arr){
if (arr == null || arr.length == 0) {
return null;
}
int MaxValue = Integer.MIN_VALUE;
int MinValue = Integer.MAX_VALUE;
//找出数组中的最大最小值
for(int i = 0; i < arr.length; i++){
MaxValue = Math.MaxValue(MaxValue, arr[i]);
MinValue = Math.MinValue(MinValue, arr[i]);
}
int Book[] = new int[MaxValue];
//找出每个数字出现的次数
for(int i = 0; i < arr.length; i++){
Book[arr[i] - MinValue]++;
}
int index = 0;
for(int i = 0; i < Book.length; i++){
while(Book[i]-- > 0){
arr[index++] = i+MinValue;
}
}
return arr;
}
#python
def BucketSort(arr):
MaxValue, MinValue = max(arr), min(arr)
Bucket = [0] * (MaxValue - MinValue +1)
for i in arr:
Bucket[i - MinValue]+=1
index = 0
for i in range(len(Bucket)):
for j in range(Bucket[i]):
arr[index] = i+MinValue
index+=1
3. 基数排序
**基数排序 (Radix Sort)**是一种非比较排序算法,时间复杂度是 O(N) 。
主要思路:
- 将所有待排序整数(注意,必须是非负整数)统一为位数相同的整数,位数较少的前面补零。一般用10进制,也可以用16进制甚至2进制。所以前提是能够找到最大值,得到最长的位数,设 K 进制下最长为位数为 d 。
- 从最低位开始,依次进行一次稳定排序。这样从最低位一直到最高位排序完成以后,整个序列就变成了一个有序序列。
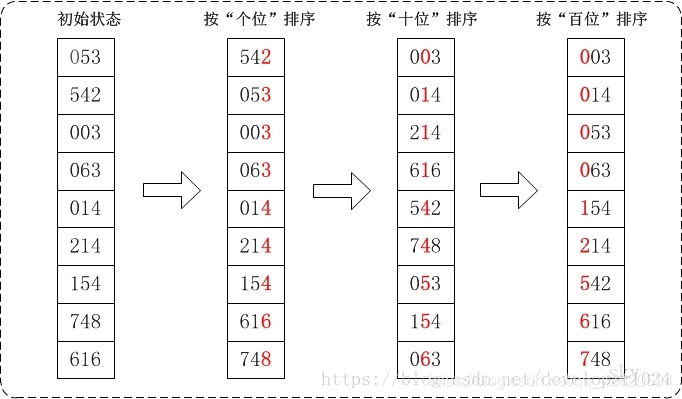
举个例子:
有一个整数序列Array[5] = 0, 123, 45, 386, 106
下面是排序过程:
第一次排序,个位,000 123 045 386 106,无任何变化
第二次排序,十位,000 106 123 045 386
第三次排序,百位,000 045 106 123 386
最终结果,0, 45, 106, 123, 386, 排序完成。
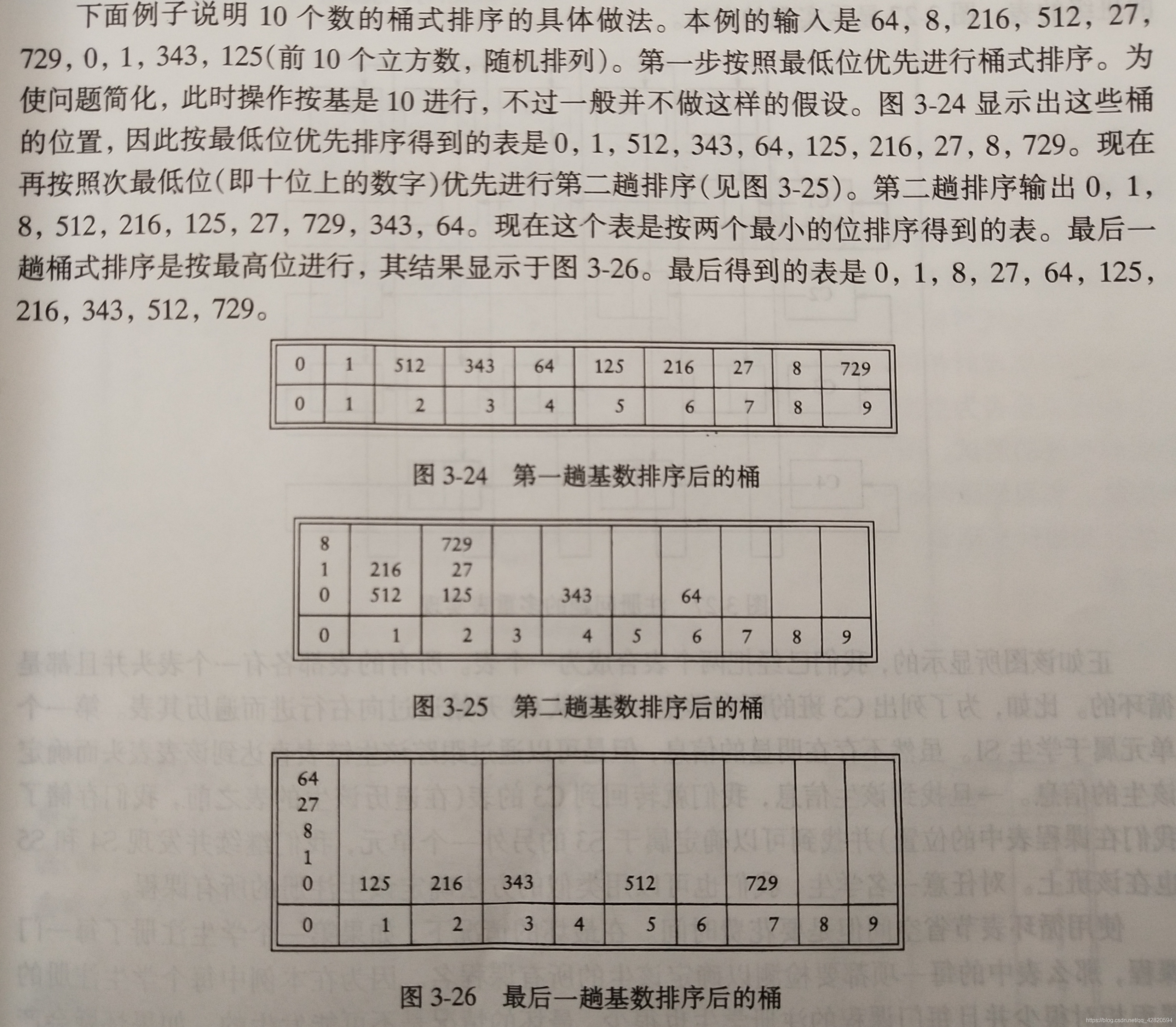
复杂度分析:
基数排序的运行时间是O(P(N+ B))
其中P是排序的趟数,N是要被排序的元素的个数,而B是桶数,即B进制数D。P,B都是常数,所以Tworst(N) = O(N)。
空间复杂度:O(D*N)
算法实现:
//C99
#define SCALE 10 //所使用的进制
void RadixSort(int Array[], int ArrayLength)
{
int MaxValue = Max(Array,ArrayLength);
int MaxValueLen = GetNumLen(MaxValue); //最大元素位数
//按十进制来,创建Bucket时,在二维中增加一组标识位
//其中Bucket[x, 0]表示这一维所包含的数字的个数
int BucketNum = SCALE;
Bucke[SBucketNum][ArrayLength+1];
for(int i = 0;i<BucketNum;i++)
Bucket[i][0] = 0;//将桶里的计数器初始化为0
//下面部分排序,计入时间复杂度
//进行D = SCALE 次排序
int index = 0;//
for(int i = 0;i<BucketNum;i++)
for(int i = 0;i<BucketNum;i++)
for(int j = 0;j<ArrayLength;j++)
{
int l = GetNum(Array[j],i);
index = BucketNum[0][0];
BucketNum[0][0]++;
BucketNum[0][0] = Array[j];
}
///我不想写了。。。。怎么这个这么麻烦。。。。。偷个懒不写了
//看这个吧https://blog.csdn.net/qq_42820594/article/details/104021351
}
//活动num的figures位的值(123,0) = 3
int GetNum(int num, int figures) // 123 123 / 1 % 10 == 3 123 / 10 % 10 == 2 123 / 100 % 10 == 1
{
int base = pow((double)10,(figures));
return num / base % 10;
}
//C++
int maxbit(int data[], int n) //辅助函数,求数据的最大位数
{
int maxData = data[0]; ///< 最大数
/// 先求出最大数,再求其位数,这样有原先依次每个数判断其位数,稍微优化点。
for (int i = 1; i < n; ++i)
{
if (maxData < data[i])
maxData = data[i];
}
int d = 1;
int p = 10;
while (maxData >= p)
{
//p *= 10; // Maybe overflow
maxData /= 10;
++d;
}
return d;
/* int d = 1; //保存最大的位数
int p = 10;
for(int i = 0; i < n; ++i)
{
while(data[i] >= p)
{
p *= 10;
++d;
}
}
return d;*/
}
void radixsort(int data[], int n) //基数排序
{
int d = maxbit(data, n);
int *tmp = new int[n];
int *count = new int[10]; //计数器
int i, j, k;
int radix = 1;
for(i = 1; i <= d; i++) //进行d次排序
{
for(j = 0; j < 10; j++)
count[j] = 0; //每次分配前清空计数器
for(j = 0; j < n; j++)
{
k = (data[j] / radix) % 10; //统计每个桶中的记录数
count[k]++;
}
for(j = 1; j < 10; j++)
count[j] = count[j - 1] + count[j]; //将tmp中的位置依次分配给每个桶
for(j = n - 1; j >= 0; j--) //将所有桶中记录依次收集到tmp中
{
k = (data[j] / radix) % 10;
tmp[count[k] - 1] = data[j];
count[k]--;
}
for(j = 0; j < n; j++) //将临时数组的内容复制到data中
data[j] = tmp[j];
radix = radix * 10;
}
delete []tmp;
delete []count;
}
#这里将列表进行基数排序,默认列表中的元素都是正整数
def radix_sort(s):
"""基数排序"""
i = 0 # 记录当前正在排拿一位,最低位为1
max_num = max(s) # 最大值
j = len(str(max_num)) # 记录最大值的位数
while i < j:
bucket_list =[[] for _ in range(10)] #初始化桶数组
for x in s:
bucket_list[int(x / (10**i)) % 10].append(x) # 找到位置放入桶数组
print(bucket_list)
s.clear()
for x in bucket_list: # 放回原序列
for y in x:
s.append(y)
i += 1
if __name__ == '__main__':
a = [334,5,67,345,7,345345,99,4,23,78,45,1,3453,23424]
radix_sort(a)
print(a)
package sort;
public class RadixSort {
private static void radixSort(int[] array,int d)
{
int n=1;//代表位数对应的数:1,10,100...
int k=0;//保存每一位排序后的结果用于下一位的排序输入
int length=array.length;
int[][] bucket=new int[10][length];//排序桶用于保存每次排序后的结果,这一位上排序结果相同的数字放在同一个桶里
int[] order=new int[length];//用于保存每个桶里有多少个数字
while(n<d)
{
for(int num:array) //将数组array里的每个数字放在相应的桶里
{
int digit=(num/n)%10;
bucket[digit][order[digit]]=num;
order[digit]++;
}
for(int i=0;i<length;i++)//将前一个循环生成的桶里的数据覆盖到原数组中用于保存这一位的排序结果
{
if(order[i]!=0)//这个桶里有数据,从上到下遍历这个桶并将数据保存到原数组中
{
for(int j=0;j<order[i];j++)
{
array[k]=bucket[i][j];
k++;
}
}
order[i]=0;//将桶里计数器置0,用于下一次位排序
}
n*=10;
k=0;//将k置0,用于下一轮保存位排序结果
}
}
public static void main(String[] args)
{
int[] A=new int[]{73,22, 93, 43, 55, 14, 28, 65, 39, 81};
radixSort(A, 100);
for(int num:A)
{
System.out.println(num);
}
}
}
总结
-
为什么同一数位的排序子程序要用稳定排序?
-
因为稳定排序能将上一次排序的成果保留下来。例如十位数的排序过程能保留个位数的排序成果,百位数的排序过程能保留十位数的排序成果。能不能用2进制?能,可以把待排序序列中的每个整数都看成是01组成的二进制数值。那这样的话,岂不是任意一个非负整数序列都可以用基数排序算法?理论上是的,假设待排序序列中最大整数为2 4 . 1,则最大位数 d=64 ,时间复杂度为 O(64n) 。可见任意一个非负整数序列都可以在线性时间内完成排序。
-
既然任意一个非负整数序列都可以在线性时间内完成排序,那么基于比较排序的算法有什么意义呢?
-
基于比较的排序算法,时间复杂度是 O(nlogn) ,看起来比 O(64n) 慢,仔细一想,其实不是, O(nlogn) 只有当序列非常长,达到2 个元素的时候,才会与 O(64n) 相等,因此,64这个常数系数太大了,大部分时候, n 远远小于2 ,基于比较的排序算法还是比 O(64n) 快的。
基数排序:根据键值的每位数字来分配桶;
计数排序:每个桶只存储单一键值;
桶排序:每个桶存储一定范围的数值;
- 当使用2进制时, k=2 最小,位数 d 最大,时间复杂度 O(nd) 会变大,空间复杂度 O(n+k) 会变小。当用最大值作为基数时, k=maxV 最大, d=1 最小,此时时间复杂度 O(nd) 变小,但是空间复杂度 O(n+k) 会急剧增大,此时基数排序退化成了计数排序。
引用:
有些图片是引用了这些文章里的
https://blog.csdn.net/qq_19446965/article/details/81517552
https://blog.csdn.net/developer1024/article/details/79770240
https://www.jianshu.com/p/204ed43aec0c
https://www.cnblogs.com/cjm123/p/9477450.html
https://www.cnblogs.com/bqwzx/p/11029264.html
https://baike.baidu.com/item/%E6%A1%B6%E6%8E%92%E5%BA%8F/4973777?fr=aladdin
https://www.cnblogs.com/sfencs-hcy/p/10616446.html
https://www.cnblogs.com/developerY/p/3172379.html
