一、桶排序
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。桶排序 (Bucket sort)的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排)。
假设你有五百万份试卷,每份试卷的满分都是100分,如果要你对这些试卷按照分数进行排序,天噜啦,五百万份试卷啊,快速排序?堆排序?归并排序?面对这么多的数据,平均下来上面的每一种算法至少都要花费nlogn=5000000log5000000=111267433单位时间啊,将近一亿多,太慢了。
要是我们这样来做呢,首先买101只桶回来,分别为每一只桶编上0-100标号,我们就只管遍历一边所有的试卷,将分数为n的试卷丢入到编号为n的桶里面,当所有的试卷都放入到相应的桶里面时,我们就已经将所有的试卷按照分数进行排序了。遍历一遍所有数据的时间也就是五百万次,相比与一亿多次,那可是省了不少时间。这里所用到的就是桶排序的思想。
1、算法描述
1. 设置一个定量的数组当作空桶;
2. 遍历输入数据,并且把数据一个一个放到对应的桶里去;
3. 对每个不是空的桶进行排序;
4. 从不是空的桶里把排好序的数据拼接起来。
2、算法图解
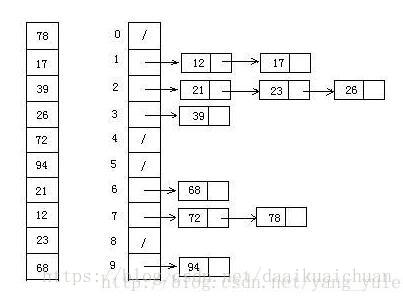
3、算法demo
#include <bits/stdc++.h>
using namespace std;
using llt = long long int;
void bucket_sort1(vector<int> number)
{
llt sz = number.size();
vector<int> bucket;
for (llt i = 0; i <= 100; ++i)//创建101个桶
bucket.push_back(0);
for (llt i = 0; i < sz; ++i)
{
bucket[number[i]]++;//把元素放入相应编号的桶中
}
for (llt i = 0; i < 100; ++i)
{
for (llt j = 0; j < bucket[i]; ++j)//输出桶的编号(即元素的大小)
cout << i << " ";
}
}
void bucket_sort2(vector<int> number)
{
llt sz = number.size();
vector<vector<int>> bucket(11);//创建11个桶
for (llt i = 0; i < sz; ++i)
{
//根据十位数放入相应编号的桶中(每个桶中元素的十位数相同)
bucket[number[i]/10].push_back(number[i]);
}
for (llt i = 10; i >= 1; --i)
{
if (!bucket[i].empty())
{
sort(bucket[i].begin(), bucket[i].end());//对每个桶中的元素排序
for (auto b : bucket[i])
cout << b << " ";
}
}
}
int main(int argc, char const *argv[])
{
vector<int> number = {45, 12, 23, 56, 45};
bucket_sort1(number);
cout << endl;
bucket_sort2(number);
return 0;
}4、算法总结
桶排序是稳定排序,对于数据为较小的整数且数据都在某一个范围内时,使用桶排序效率较高。桶排序最坏情况下是O(n^2),桶排序最好情况下使用线性时间O(n)。
桶排序的时间复杂度,取决与对各个桶之间数据进行排序的时间复杂度,因为其它部分的时间复杂度都为O(n)。很显然,桶划分的越小,各个桶之间的数据越少,排序所用的时间也会越少。但相应的空间消耗就会增大。
二、基数排序
基数排序不同于其他的排序算法,它不是基于比较的算法。基数排序是一种借助多关键字排序的思想对单逻辑关键字进行排序的方法。它是一种稳定的排序算法。多关键字排序中有两种方法:最高位优先法(MSD)和最低位优先法(LSD)。通常用于对数的排序选择的是最低位优先法,即先对最次位关键字进行排序,再对高一位的关键字进行排序,以此类推。
1、算法描述
1. 取得数组中的最大数,并取得位数;
2. arr为原始数组,从最低位开始取每个位组成radix数组;
3. 对radix进行计数排序(利用计数排序适用于小范围数的特点);
2、算法图解
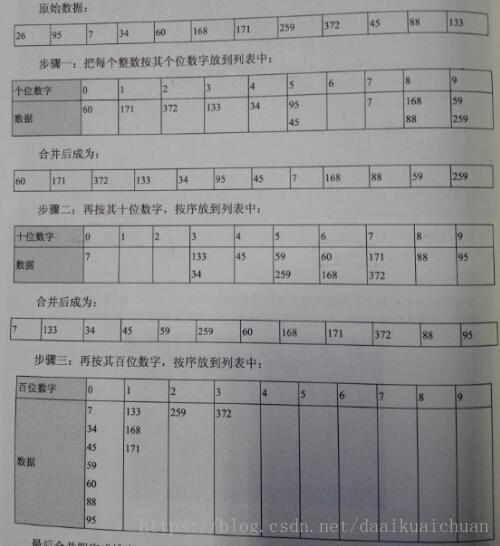
3、算法demo
#include <bits/stdc++.h>
using namespace std;
//d的值为1、2、3...,表示要求取的相应位的值,1表示求取个位,2表示十分位,类推
int getDigit(int i, int d)
{
int val;
while (d--)
{
val = i % 10;
i /= 10;
}
return val;
}
//基数排序算法的具体实现
//begin和end表示数据的起始下标,digit表示数据最大的位数
void RadixSort(vector<int> &list, int begin, int end, int digit)
{
int radix = 10; //基数
int i = 0, j = 0;
vector<int> count(radix, 0);
vector<int> bucket(end - begin + 1, 0);
for (int d = 1; d <= digit; d++)
{
//置空各个桶的统计数据
for (i = 0; i < radix; i++)
count[i] = 0;
//统计各个桶中所盛数据个数
for (i = begin; i <= end; i++)
{
j = getDigit(list[i], d);
count[j]++;
}
//count[i]表示第i个桶的右边界索引
for (i = 1; i < radix; i++)
count[i] = count[i] + count[i - 1];
//将数据依次装入桶中,保证数据的稳定性,此步即为基数排序的分配
for (i = end; i >= begin; i--)
{
j = getDigit(list[i], d);
bucket[count[j] - 1] = list[i];
count[j]--;
}
//基数排序的收集
//把桶中的数据再倒出来
for (i = begin, j = 0; i <= end; i++, j++)
{
list[i] = bucket[j];
}
}
}
int main(int argc, char const *argv[])
{
vector<int> number = { 45, 12, 23, 56, 45 };
RadixSort(number, 0, 4, 2);
for (auto v : number)
cout << v << " ";
return 0;
}4、算法总结
基数排序基于分别排序,分别收集,所以是稳定的。基数排序的时间复杂度是O(n*k),性能比桶排序要略差,每一次关键字的桶分配都需要O(n)的时间复杂度,而且分配之后得到新的关键字序列又需要O(n)的时间复杂度。假如待排数据可以分为d个关键字,则基数排序的时间复杂度将是O(d*2n) ,当然d要远远小于n,因此基本上还是线性级别的。