此部分博客是我在知乎上摘录下来的,感谢知乎大神的用心回答。
一、通俗易懂的解释
作者:王赟 Maigo
链接:https://www.zhihu.com/question/37096933/answer/70426653
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
则最优的 x 在绿点处,x 非零。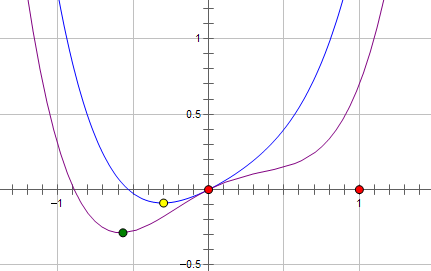
 最优的 x 在黄点处,x 的绝对值减小了,但依然非零。
最优的 x 在黄点处,x 的绝对值减小了,但依然非零。

 最优的 x 就变成了 0。这里利用的就是绝对值函数的尖峰。
最优的 x 就变成了 0。这里利用的就是绝对值函数的尖峰。
链接:https://www.zhihu.com/question/37096933/answer/70426653
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
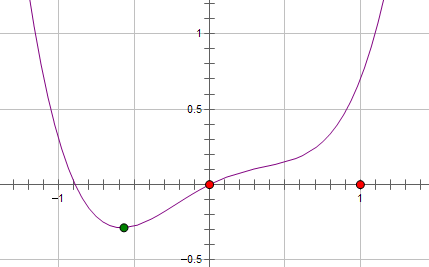
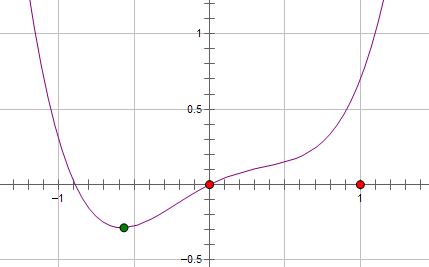
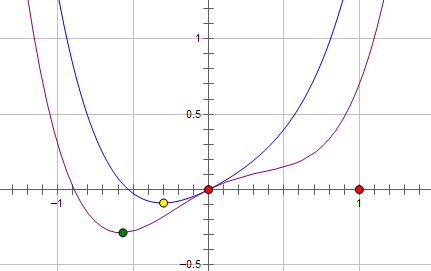
假设费用函数 L 与某个参数 x 的关系如图所示:
则最优的 x 在绿点处,x 非零。
现在施加 L2 regularization,新的费用函数()如图中蓝线所示:
最优的 x 在黄点处,x 的绝对值减小了,但依然非零。
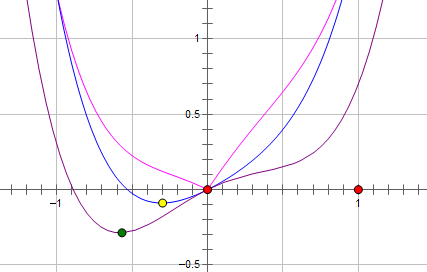
而如果施加 L1 regularization,则新的费用函数()如图中粉线所示:
最优的 x 就变成了 0。这里利用的就是绝对值函数的尖峰。
两种 regularization 能不能把最优的 x 变成 0,取决于原先的费用函数在 0 点处的导数。
如果本来导数不为 0,那么施加 L2 regularization 后导数依然不为 0,最优的 x 也不会变成 0。
而施加 L1 regularization 时,只要 regularization 项的系数 C 大于原先费用函数在 0 点处的导数的绝对值,x = 0 就会变成一个极小值点。
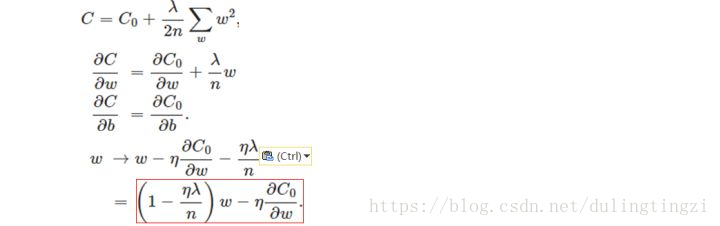
二、公式化的一般解释(这部分也是参考的知乎上的,作者十方)
设原先的损失函数是C0,那么在L0和L1条件下的损失函数对参数w求导得到: