使用机器学习算法过程中,如果太过于追求准确率,就可能会造成过拟合。使用正则化技术可以在一定程度上防止过拟合。首先来回顾一下过拟合的概念。
过拟合简单来说就是对于当前的训练数据拟合程度过高以至于模型失去了泛化能力。下面是一个房屋预测的例子:

左侧的图是欠拟合,即对于当前数据集的拟合程度不够,欠拟合的特征是在训练集和测试集上的准确率都不好。右边的为过拟合状态,过拟合对于当前数据拟合得太好了,以至于模型只在当前的数据集上表现良好而在其他数据集上表现就不是那么好了,所以过拟合的特征是在训练集上准确率很高而在训练集上表现一般。
解决过拟合主要有两种方法:
1.减少特征数量
2.正则化
这里我们主要说一说L1与L2范数正则化。
L2范数(L2-normal)
L2范数也被称为权重衰减(weight decay),为什么称为权重衰减,这个我们一会就会知道。线性回归中应用L2范数也被称为岭回归,在其他文献中也有将L2范数称为Tikhonov正则。首先我们通过线性回归来看一下L2范数。
线性回归的代价函数为:
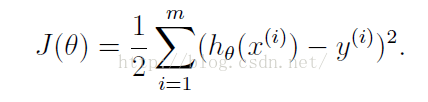
加入正则化后,代价函数变为:
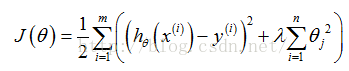
如何理解上式?可以把上式分为两部分,左边部分即为原始的代价函数,右边部分为L2正则化项(注意:正则化项中不包含theta0)。lambda为超参数,通常会取一个较大的数。为了最小化整个代价函数,因为lambda是固定的,那么就要减小theta1-n的值。对于上图中的那种过拟合状态,加入正则项后,theta1-theta4减小,也就是使得权重衰减,这样就会降低高阶项对于整个函数的影响,使得估计函数变得比较平滑。可以想象一种极端的情况,如果lambda为无穷大,那么theta1-thetan趋近于0,那么整个式子就只剩一个theta,为一条和y轴垂直的直线,这种状态为严重的欠拟合状态。可以看到,当lambda为0时,即为原来的状态,此时过拟合,而当lambda过大时又会导致欠拟合,所以会有一个恰当的lambda使得模型处于既不过拟合又不欠拟合的状态。
加入正则项后,梯度下降算法变为:
Repeat{
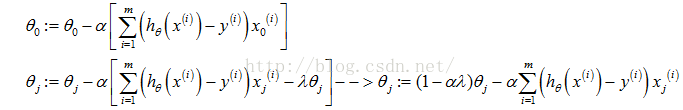
}
可以看到,由于学习速率a>0, 
上面我们对线性回归应用的正则化就是L2正则化,通常被称为权重衰减(weight decay)的L2参数范数惩罚。在其他文献或论文中,L2有时也被称为岭回归和Tikhonov正则。
正如在线性回归中的应用,L2参数正则化就是在损失函数中加入一个L2范数和一个超参数lambda,L2范数用||w||^2这种符号表示,它的意思是对于向量w中的各个数先求平方再加和。线性回归中加入的对于theta j求平方和就是一个L2范数。而超参数lambda则用于控制参数惩罚的程度。
L1范数(L1-normal)与L0范数
L0范数是指向量中非0的元素的个数。如果我们用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0,换句话说,就是让参数W是稀疏的。通常使参数稀疏都是用L1范数实现,L1范数是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。既然L0可以实现稀疏,为什么不用L0,而要用L1呢?个人理解一是因为L0范数很难优化求解(NP难问题),二是L1范数是L0范数的最优凸近似,而且它比L0范数要容易优化求解。
L1范数为什么可以实现稀疏呢?
L1范数的表达式如下:

J0为原始的损失函数,加号后面的一项是L1正则化项,是正则化系数。注意到L1正则化是权值的绝对值之和,是带有绝对值符号的函数,因此是不完全可微的。机器学习的任务就是要通过一些方法(比如梯度下降)求出损失函数的最小值。当我们在原始损失函数后添加L1正则化项时,相当于对做了一个约束。令,则,此时我们的任务变成在约束下求出取最小值的解。考虑二维的情况,即只有两个权值和,此时对于梯度下降法,求解的过程可以画出等值线,同时L1正则化的函数也可以在的二维平面上画出来。如下图:
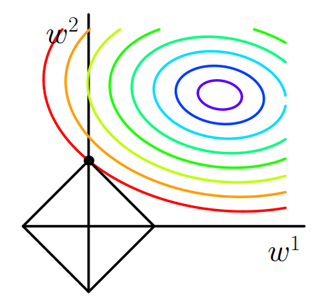
图中等值线是的等值线,黑色方形是函数的图形。在图中,当等值线与图形首次相交的地方就是最优解。上图中与在的一个顶点处相交,这个顶点就是最优解。注意到这个顶点的值是。可以直观想象,因为函数有很多『突出的角』(二维情况下四个,多维情况下更多),与这些角接触的机率会远大于与其它部位接触的机率,而在这些角上,会有很多权值等于0,这就是为什么L1正则化为什么可以产生稀疏模型。
上面我们反复提到了稀疏,也知道了L1范数可以实现稀疏,那么稀疏有什么好处呢?
1.特征选择,稀疏的矩阵可以起到特征选择的作用。我们知道,稀疏矩阵是只有少数值为非零,大多数值为0的矩阵。有些场景中特征数量可能会非常多,不利于直接使用机器学习算法。如果这是可以将参数矩阵转换稀疏的,那么就可以只保留一小部分特征(只有系数为非零的那一部分特征被保留)。这样转换成稀疏矩阵就可以起到特征选择的作用。
2.可解释性。另一个青睐于稀疏的理由是,模型更容易解释。例如患某种病的概率是y,然后我们收集到的数据x是1000维的,也就是我们需要寻找这1000种因素到底是怎么影响患上这种病的概率的。假设我们这个是个回归模型:y=w1*x1+w2*x2+…+w1000*x1000+b(当然了,为了让y限定在[0,1]的范围,一般还得加个Logistic函数)。通过学习,如果最后学习到的w*就只有很少的非零元素,例如只有5个非零的wi,那么我们就有理由相信,这些对应的特征在患病分析上面提供的信息是巨大的,决策性的。也就是说,患不患这种病只和这5个因素有关,那医生就好分析多了。
3.减少内存消耗。有些人认为稀疏矩阵可以减少内存消耗,因为这样存的元素会少一些。对于这一点,我不太确定。
L1与L2范数的差别
1.下降速度。我们知道,L1和L2都是规则化的方式,我们将权值参数以L1或者L2的方式放到代价函数里面去。然后模型就会尝试去最小化这些权值参数。而这个最小化就像一个下坡的过程,L1和L2的差别就在于这个“坡”不同,如下图:L1就是按绝对值函数的“坡”下降的,而L2是按二次函数的“坡”下降。所以实际上在0附近,L1的下降速度比L2的下降速度要快。所以会非常快得降到0。

2.能否使参数矩阵稀疏。我们已经知道L1范数可以使得参数矩阵稀疏,那么L2范数呢?L1范数与L2范数的对比图如下:

对于左图的L1范数我们已经知道,因为有棱角,在棱角出更容易得到解,而在棱角出一定程度上可以使得矩阵稀疏。而L2范数项的图形是一个原型,没有棱角,不能使得矩阵稀疏。
总结一下L1与L2范数:
L1范数:L1范数在正则化的过程中会趋向于产生少量的特征,而其他的特征都是0(L1会使得参数矩阵变得稀疏)。因此L1不仅可以起到正则化的作用,还可以起到特征选择的作用。
L2范数:L2范数是通过使权重衰减,进而使得特征对于总体的影响减小而起到防止过拟合的作用的。L2的优点在于求解稳定、快速。
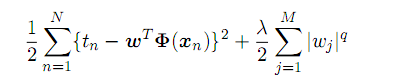
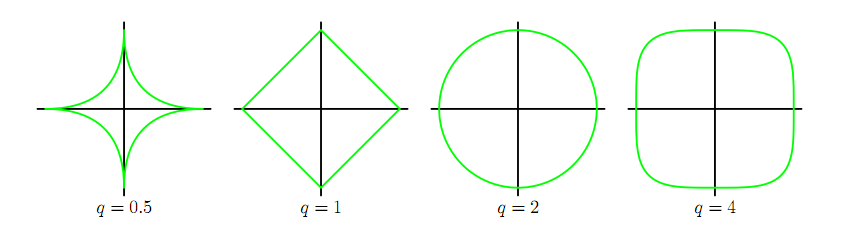
上式前半部分为原有的损失函数,后半部分为正则项。其中,q=1时即为L1正则化,q=2为L2正则化。
对于q取不同的值,正则化项的轮廓线如下: