二. 循环神经网络(RNN)
1.RNN神经网络的概念及相关介绍
- 概念:
对时间序列上的变化进行建模的一种神经网络。
- 优点:
基于之前的运行结果或者时间点,进行当前的预测。

2.代码部分
import tensorflow as tf
#引入RNN
from tensorflow.contrib import rnn
from tensorflow.examples.tutorials.mnist input_data
mnist = input_data.read_data_sets("data/",one_hot=True)
#定义参数
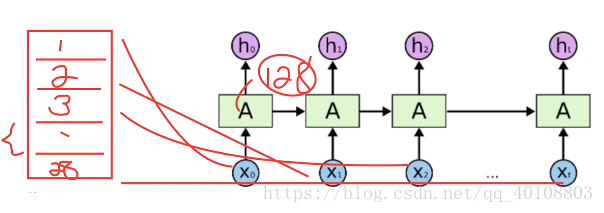
batch_size = 128
#定义训练数据
x = tf.placeholder("float",[None,28,28])
y = tf.placeholder("float",[None,10])
#定义W和b
weights = {
'out':tf.Variable(tf.random_normal([128,10]))
}
biases = {
'out':tf.Variable(tf.random_normal([10]))
}
def RNN(x,weights,biases):
#按照RNN的方式处理输入层
x = tf.unstack(x,28,1)
#lstm层
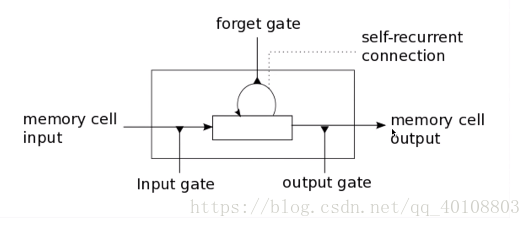
#forget_bias (默认值为1)到遗忘门的偏置,为了减少在开始训练时遗忘的规模。
lstm_cell = rnn.BasicLSTMCell(128,forget_bias=1.0)
#获取lstm层的输出
outputs,states = rnn.static_rnn(lstm_cell,x,dtype=tf.float32)
#得到最后一层的输出
return tf.matmul(outputs[-1],weights['out']) + biases['out']
#预测值
pred = RNN(x,weights,biases)
#定义代价函数和最优算法
#寻找全局最优点的优化算法,引入二次方梯度校正
#AdamOptimizer 不容易陷入局部最优点,速度更快
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred,labels=y))
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(cost)
#结果对比
correct_pred = tf.equal(tf.argmax(pred,1),tf.argmax(y,1))
#求正确率
accuracy = tf.reduce_mean(tf.cast(correct_pred,tf.float32))
#初始化所有参数
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
step = 1
while step * batch_size < 100000:
batch_x,batch_y = mnist.train.next_batch(batch_size)
batch_x = batch_x.reshape((batch_size,28,28))
sess.run(optimizer,feed_dict={x:batch_x,y:batch_y})
if step % 10 == 0:
acc = sess.run(accuracy,feed_dict={x:batch_x,y:batch_y})
loss = sess.run(cost,feed_dict={x:batch_x,y:batch_y})
print("Tter "+str(step * batch_size) + ",Minibatch Loss="+"{:.6f}".format(loss)+",Training Accuracy="+"{:.5f}".format(acc))
step += 1
print("Optimization Finished!")
#数据验证
test_len = 128
test_data = mnist.test.images[:test_len].reshape((-1,28,28))
test_label = mnist.test.labels[:test_len]
print("Testing Accuracy:",sess.run(accuracy,feed_dict={x:test_data,y:test_label}))