循环神经网络RNN、LSTM原理,并用Tensorflow搭建网络训练mnist数据集
RNN
▲原理:
●RNN(循环神经网络)用来处理序列形的数据,如:自然语言处理问题,语言处理,时间序列问题。序列形的数据就不太好用原始的神经网络了。为了建模序列问题,RNN,引入隐状态h的概念,h可以对序列形的数据提取特征,接着转化为输出。
●hidden state(特征提取):
h1=f(ux1+wh0+b)

圆圈或者方块表示的就是向量,一个箭头表示对该向量做一次变换。h0,x1分别有一个箭头连接,表示h0,x1各做了一次变换。
h2的计算与h1类似,每一步使用的u,w,b都是一样的,也就是说每一步的权重都是共享的,RNN的重要特点:权重共享
●RNN单词输出:

y1=softmax(ux1+c)
。
。
h1=f(ux1+wh0+b)
h2=f(ux2+wh1+b)
。
。
u和w不变,即共享权重
y:输出
c:特征向量,整个的完整的序列的信息
每使用一次,就要对h0进行初始化,一般为0,最终的输出c:特征向量,这样最终输出就包含x1,x2,…xn且是序列,x1,x2,…xn是一个整体,后面的要受到前面的制约与限制。
▲RNN结构
1.N vs 1
输入的是序列,输出的是单值(文字输入,图片输出)
Y=softmax(uh4+c)

2. 1 vs N

3.n vs m(组合网络)

●RNN存在的问题
1.梯度消失,梯度爆炸(连乘时易出现)
2.序列太长时,前面的东西容易消失(长期依赖问题)
▲LSTM出现
RNN结构中实际有个tanh,把数据压缩到(-1,1),避免梯度消失或者爆炸,理论上,RNN可以处理长期依赖问题,但实践中无法完成。


C(t-1)→C(t): Cell水平传送带
●节点称为门,σ:sigmoid作为输出是二分类问题,输出是lim→0或lim→1
(1):输入门(忘记门):判断数据是否存储到细胞的状态中,序列特征收集器,对输入的数据进行筛选、提取;决定是否把信息输入;
(2):更新门决定信息是否保留;
(3):输出门:
●梯度消失问题

输出C对b1求偏导:
sigmiod的导数如下:


由上面的推导,梯度爆炸的出现就显而易见了,即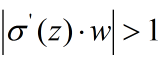
也就是w比较大的情况。梯度爆炸和消失的问题都是因为网络太深,网络权重更新不稳定造成的,本质上是因为梯度反向传播的连乘效应,对于更普遍的梯度消失问题,可以参考用Rule激活函数取代Sigmoid激活函数。另外LSTM的结构设计也可以改善RNN中梯度消失问题。
▲LSTM的变体:GRU
●将更新门与输入门组合成一个“更新门”。它还合并了单元状态和隐藏状态。由此产生的模型比标准模型LSTM更简单。
▲用Tensorflow搭建LSTM网络模型训练mnist数据集
虽然mnist数据并不是序列形式的,但是也可以拿来训练测试。
这里重点提醒,LSTM网络的数据输入格式为NSV*
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data",one_hot=True)
class LstmNet:
def __init__(self):
self.x = tf.placeholder(dtype=tf.float32,shape=[None,784])
self.y = tf.placeholder(dtype=tf.float32,shape=[None,10])
#NV变成N(100,28)V(28)后的第一层权重(28,28)
self.w1 = tf.Variable(tf.truncated_normal(shape=[28,128],stddev=0.1))
self.b1 = tf.Variable(tf.zeros(128))
#输出层权重
self.out_w = tf.Variable(tf.truncated_normal(shape=[128,10],stddev=0.1))
self.out_b = tf.Variable(tf.zeros(10))
def forward(self):
#变形
y = tf.reshape(self.x,shape=[-1,28])#[100*28,28]
y = tf.nn.relu(tf.matmul(y,self.w1)+self.b1)#[100*28,128]
#NV->NSV 2800,128,==>100,28,128
y = tf.reshape(y,[-1,28,128])
print(y.shape)
#定义细胞(超参数)
# lstm_cell = tf.nn.rnn_cell.LSTMCell(28)
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(128)
#初始化细胞状态
init_state = lstm_cell.zero_state(100,dtype=tf.float32)
#关键函数:前项NSV-SNV取最后一步NV
output,final_state = tf.nn.dynamic_rnn(lstm_cell,y,initial_state=init_state)
y = tf.transpose(output,[1,0,2])[-1]
# y = output[:,-1,:]
#NV
self.output = tf.nn.softmax(tf.matmul(y,self.out_w)+self.out_b)
def backward(self):
self.loss = tf.reduce_mean((self.output-self.y)**2)
self.opt = tf.train.AdamOptimizer().minimize(self.loss)
if __name__ == '__main__':
net = LstmNet()
net.forward()
net.backward()
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(10000):
xs,ys = mnist.train.next_batch(100)
loss,_ = sess.run([net.loss,net.opt],feed_dict={net.x:xs,net.y:ys})
if i % 100 ==0:
testxs,testys = mnist.test.next_batch(100)
test_output = sess.run(net.output,feed_dict={net.x:testxs})
test_y = np.argmax(testys,axis=1)
test_out = np.argmax(test_output, axis=1)
print(np.mean(np.array(test_y==test_out,dtype=np.float32)))
精度还是不错的

