前言:期待已久的科研项目终于有眉目了,这是第一次去找研究生老师做项目,由于时间关系,老师没能给我安排上任务,叫我和一个研究生学长交接工作。第一个叫我解决的网站就是《贵州农经网》,由于有一个验证码,他也不得其解。后来发了一篇秀璋老师写的文章给我学习,这是秀璋老师在2017年写的爬虫,当时的网站还没有验证码,所以会简单很多,和如今的需求已经不一样了。
贵州农经网: 中国百强农业网站,贵州省优秀政府网站,是贵州省委、省政府为促进农业增效,促进农民增收而建立的省、地、县、乡四级农村综合经济信息网。
爬取网站: http://www.gznw.com/eportal/ui?pageId=595091
文章目录
1、分析网页
我认为学习网络爬虫的关键是分析网页数据的加载方式,然后再模拟客户端去请求数据。
1.1、分析数据加载的步骤
1. 先到搜索页面搜索某个商品,加载信息,如我以线椒为例: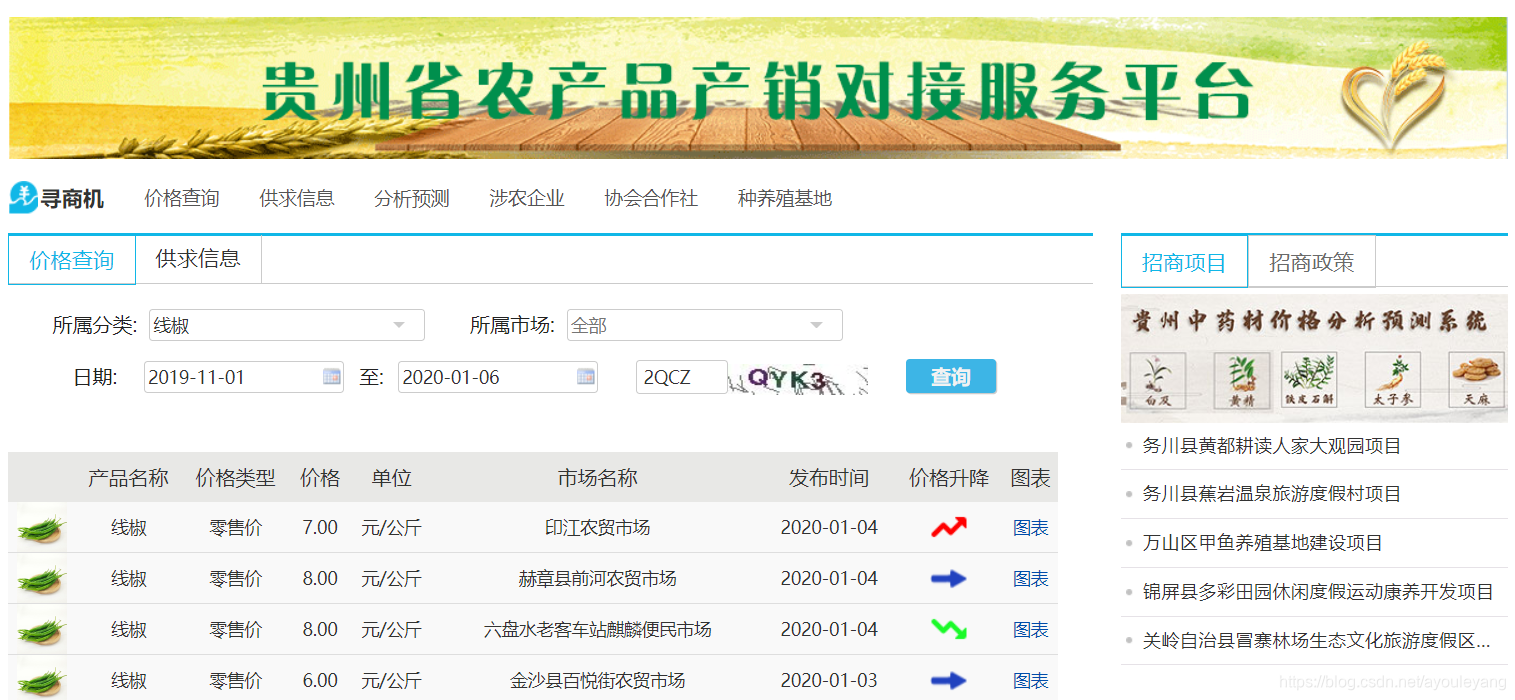
经过测试,只有输入验证码,验证正确后才能拿到到数据,对于这种必须要验证码的网页,我们可以选择selenium来爬取,但是我们先再看看其他的方式,如获取到数据传输通道,直接实现查询功能,这样的话速度就比selenium快很多!
2. 分析URL
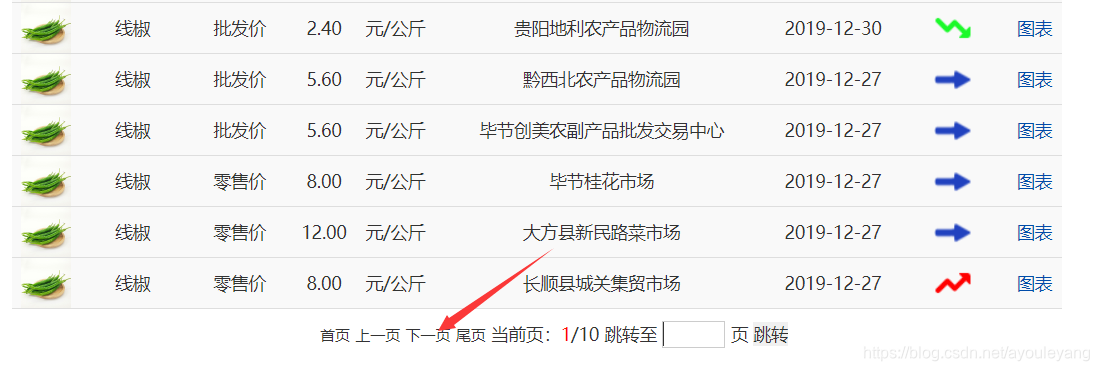
直接点击“下一页”,发现URL并没有什么变化,还是和以前是一样的,可以简单猜想这个数据是通过某种通道加载的,现在来检验一下。
3、寻找数据加载通道
这个方式也可以叫做数据抓包,找到这个通道后,就可以直接通过这个通道截取数据。
第一步:右击–>检查

第二步:打开Network,选择All
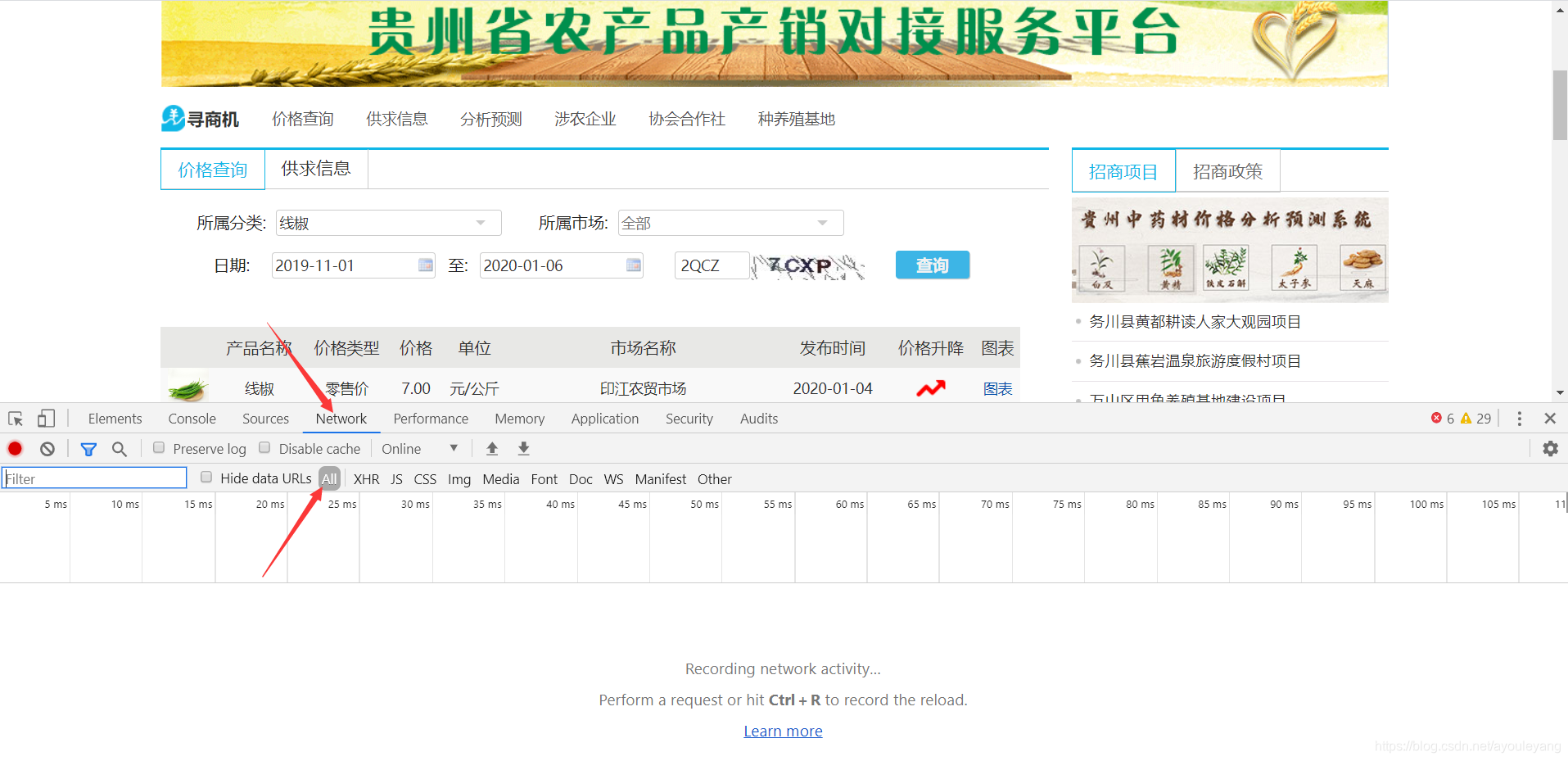
第三步:输入验证码,点击查询加载数据
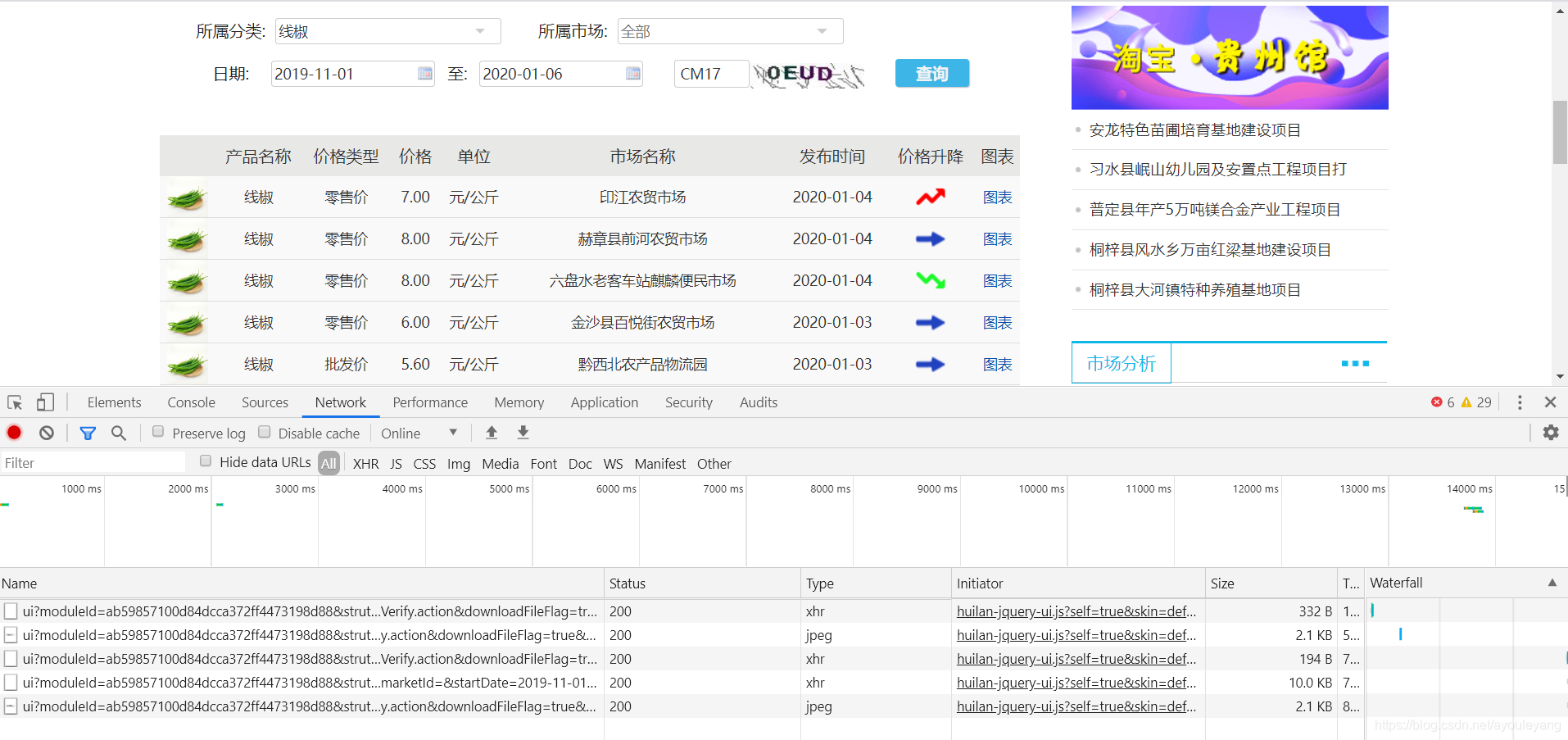
第四步:寻找数据传输通道
从加载出来的结果来看,并不是很多,也便于寻找数据。
我们要寻找的数据是文本型,所以在Type中,直接把目标定在xhr就行了,
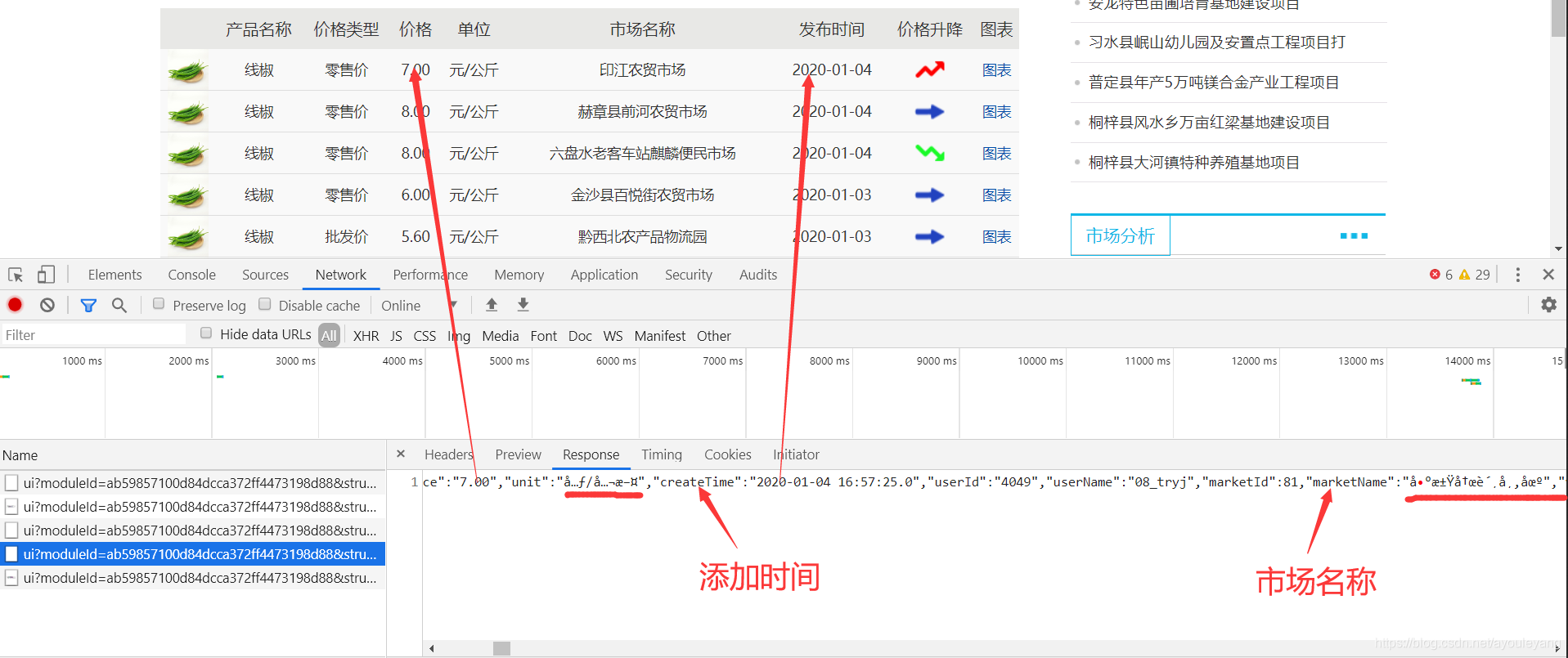
这样我们就找到了需要的数据,目前来看就只有价格和市场名称可见,添加时间,市场名称等内容不可见,先看看是否被加密了。
第五步:复制该路径到浏览器中打开试试

第六步:分析结果
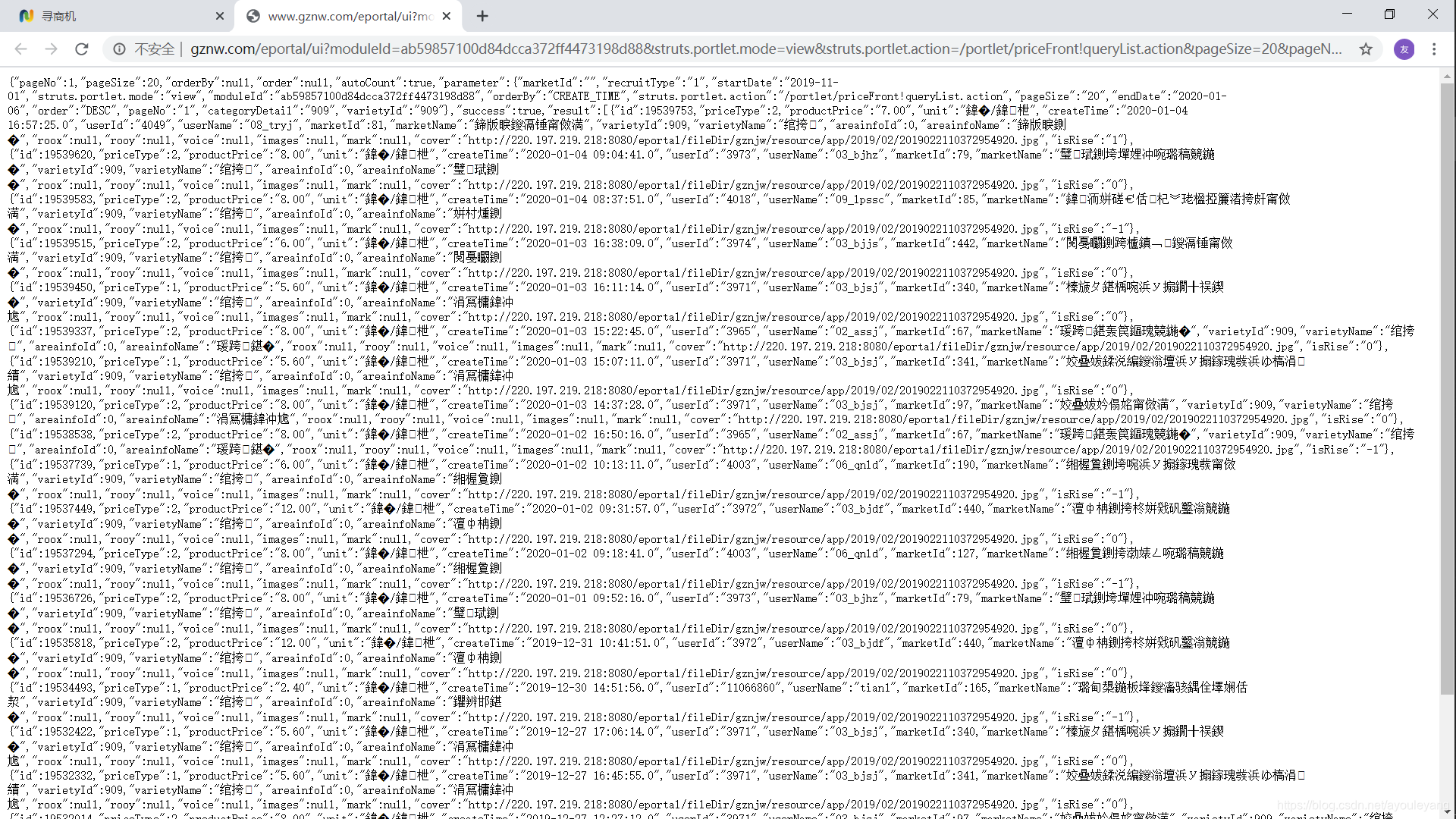
从上面的结果来看,其他数据都出来了,就只有中文看不见,全是乱码的,这样就可以笑了,因为数据没有加密传输,只是它们的解码问题而已~
1.2、请求通道数据
import requests
result = requests.get('http://www.gznw.com/eportal/ui?moduleId=ab59857100d84dcca372ff4473198d88&struts.portlet.mode=view&struts.portlet.action=/portlet/priceFront!queryList.action&pageSize=20&pageNo=1&recruitType=1&categoryDetail=909&marketId=&startDate=2019-11-01&endDate=2020-01-06')
print (result.text)
请求结果:
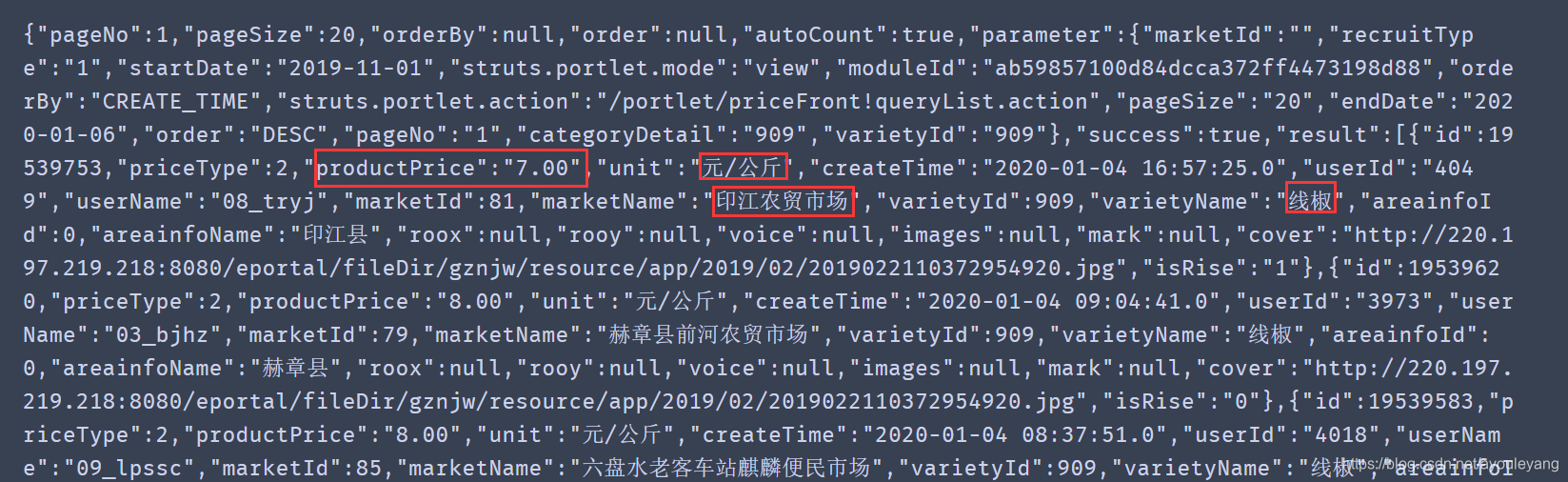
现在完全可以确定这就是我们需要的数据了,先来把它美化一下吧!
import pprint
pprint.pprint(result.json())
呈现结果:
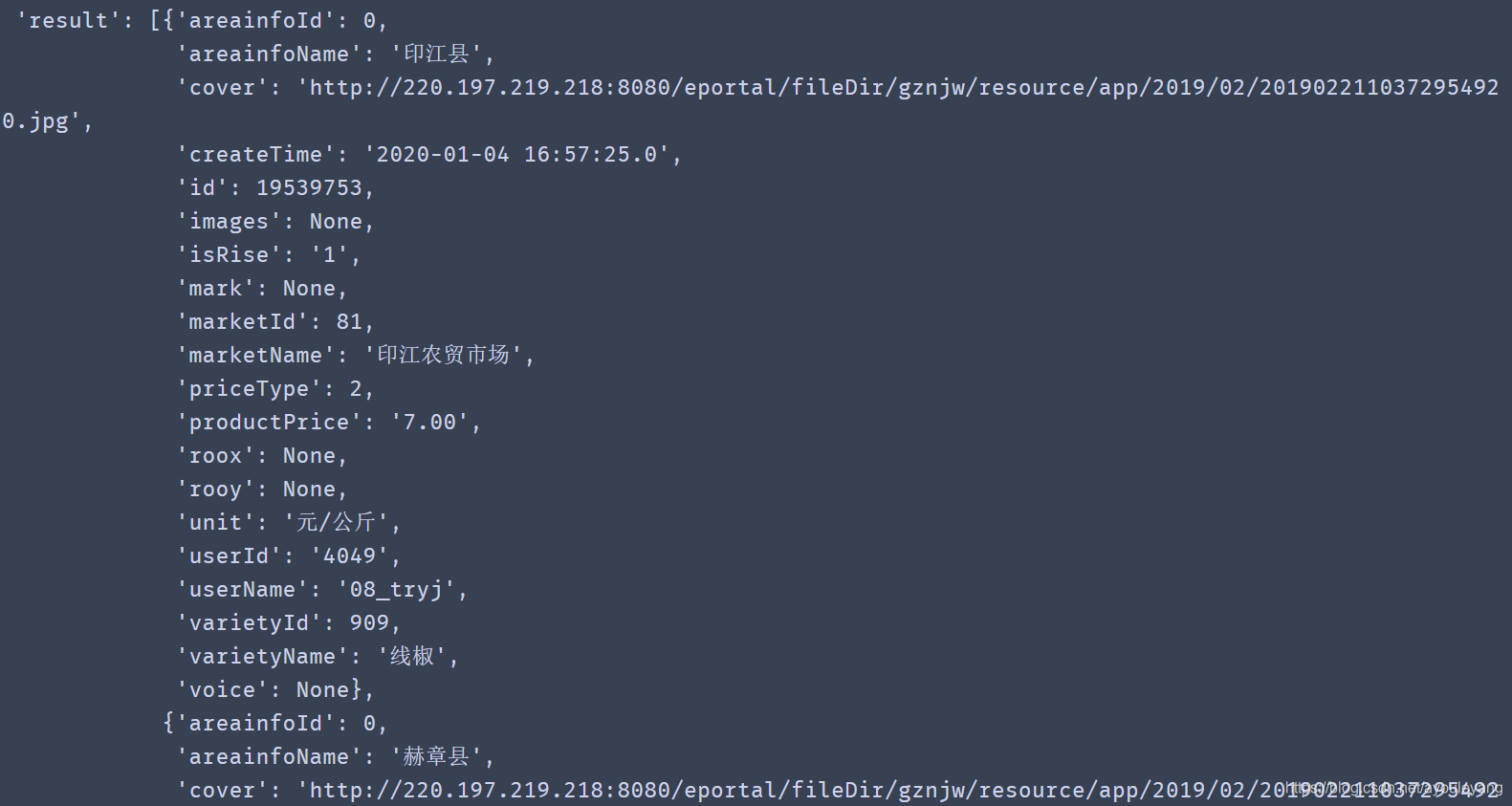
2、提取数据
2.1、核对需要爬取的信息

2.2、提取json数据
从上面可以看出这是json数据,可以直接根据目录查询到数据
import requests
json = requests.get('http://www.gznw.com/eportal/ui?moduleId=ab59857100d84dcca372ff4473198d88&struts.portlet.mode=view&struts.portlet.action=/portlet/priceFront!queryList.action&pageSize=20&pageNo=3&recruitType=1&categoryDetail=909&marketId=&startDate=2018-01-01&endDate=2019-12-03')
for result in json.json()['result']:
varietyName = result['varietyName']#商品名称
priceType = '批发价' if int(result['priceType']) == 1 else "零售价"#1为批发价,2为零售价
productPrice = result['productPrice']#产品价格
unit = result['unit']#单位
marketName = result['marketName']#市场名称
createTime = result['createTime'][:10]#[:10]截取出时间中的年月日,去掉具体时分
print (varietyName,priceType,productPrice,unit,marketName,createTime)
提取结果:
线椒 零售价 6.00 元/公斤 金沙县百悦街农贸市场 2019-11-20
线椒 批发价 50.00 元/公斤 黔西北农产品物流园 2019-11-20
线椒 零售价 12.00 元/公斤 大方县新民路菜市场 2019-11-20
线椒 批发价 5.00 元/公斤 毕节创美农副产品批发交易中心 2019-11-19
线椒 零售价 7.00 元/公斤 毕节桂花市场 2019-11-19
线椒 零售价 8.00 元/公斤 赫章县前河农贸市场 2019-11-19
线椒 零售价 6.00 元/公斤 凤冈县东环路过渡农贸市场 2019-11-19
线椒 批发价 2.60 元/公斤 双龙农副产品交易中心 2019-11-18
线椒 零售价 10.00 元/公斤 盘州农贸市场 2019-11-18
线椒 零售价 4.00 元/公斤 雷山县综合农贸市场 2019-11-16
线椒 批发价 5.00 元/公斤 黔西北农产品物流园 2019-11-15
线椒 批发价 5.00 元/公斤 毕节创美农副产品批发交易中心 2019-11-15
线椒 零售价 7.00 元/公斤 毕节桂花市场 2019-11-15
线椒 零售价 6.00 元/公斤 金沙县百悦街农贸市场 2019-11-15
线椒 零售价 20.00 元/公斤 望谟县望江新城农贸市场 2019-11-15
线椒 零售价 6.00 元/公斤 金沙县百悦街农贸市场 2019-11-14
线椒 批发价 5.00 元/公斤 黔西北农产品物流园 2019-11-14
线椒 批发价 5.00 元/公斤 毕节创美农副产品批发交易中心 2019-11-14
线椒 批发价 2.60 元/公斤 双龙农副产品交易中心 2019-11-14
线椒 批发价 2.60 元/公斤 贵阳地利农产品物流园 2019-11-14
2.3、实现翻页爬取
通过上面说过的分析网页数据的方法,我们看看第一页和第二页的json数据通道有什么不同,就可以得到我们想要的信息了

2.4、构造json通道
for page in range(1,6,1):
jsonUrl = "http://www.gznw.com/eportal/ui?moduleId=ab59857100d84dcca372ff4473198d88&struts.portlet.mode=view&struts.portlet.action=/portlet/priceFront!queryList.action&pageSize=20&pageNo={page}&recruitType=1&categoryDetail=909&marketId=&startDate=2019-11-01&endDate=2020-01-06"+str(page)
print (jsonUrl)
输出结果:
http://www.gznw.com/eportal/ui?moduleId=ab59857100d84dcca372ff4473198d88&struts.portlet.mode=view&struts.portlet.action=/portlet/priceFront!queryList.action&pageSize=20&pageNo=1&recruitType=1&categoryDetail=909&marketId=&startDate=2019-11-01&endDate=2020-01-061
http://www.gznw.com/eportal/ui?moduleId=ab59857100d84dcca372ff4473198d88&struts.portlet.mode=view&struts.portlet.action=/portlet/priceFront!queryList.action&pageSize=20&pageNo=2&recruitType=1&categoryDetail=909&marketId=&startDate=2019-11-01&endDate=2020-01-062
http://www.gznw.com/eportal/ui?moduleId=ab59857100d84dcca372ff4473198d88&struts.portlet.mode=view&struts.portlet.action=/portlet/priceFront!queryList.action&pageSize=20&pageNo=3&recruitType=1&categoryDetail=909&marketId=&startDate=2019-11-01&endDate=2020-01-063
http://www.gznw.com/eportal/ui?moduleId=ab59857100d84dcca372ff4473198d88&struts.portlet.mode=view&struts.portlet.action=/portlet/priceFront!queryList.action&pageSize=20&pageNo=4&recruitType=1&categoryDetail=909&marketId=&startDate=2019-11-01&endDate=2020-01-064
http://www.gznw.com/eportal/ui?moduleId=ab59857100d84dcca372ff4473198d88&struts.portlet.mode=view&struts.portlet.action=/portlet/priceFront!queryList.action&pageSize=20&pageNo=5&recruitType=1&categoryDetail=909&marketId=&startDate=2019-11-01&endDate=2020-01-065
2.5、写入csv
3、源码汇总
import requests,csv,time
startTime =time.time()#获取开始时的时间
fp = open('G:\\线椒.csv','a',newline='',encoding='utf-8')#创建CSV文件
writer = csv.writer(fp)
writer.writerow(('产品名称','价格类型','价格','单位','市场名称','发布时间')) #csv头部
for page in range(1,11,1):
jsonUrl = f"http://www.gznw.com/eportal/ui?moduleId=ab59857100d84dcca372ff4473198d88&struts.portlet.mode=view&struts.portlet.action=/portlet/priceFront!queryList.action&pageSize=20&pageNo={page}&recruitType=1&categoryDetail=909&marketId=&startDate=2019-11-01&endDate=2020-01-06"+str(page)
json = requests.get(jsonUrl)
print ("这在爬取第%s个页面"%page)
for result in json.json()['result']:
varietyName = result['varietyName']#商品名称
priceType = '批发价' if int(result['priceType']) == 1 else "零售价"#1为批发价,2为零售价
productPrice = result['productPrice']#产品价格
unit = result['unit']#单位
marketName = result['marketName']#市场名称
createTime = result['createTime'][:10]#[:10]截取出时间中的年月日,去掉具体时分
position = (varietyName,priceType,productPrice,unit,marketName,createTime)
writer.writerow((position))#写入数据
fp.close() #关闭文件
endTime =time.time()#获取结束时的时间
useTime =(endTime-startTime)/60
print ("该次所获的信息一共使用%s分钟"%useTime)
编辑器运行截屏:
**提示:**使用数据通道来获取数据的速度比请求html快n倍,如果没有其他条件限制的话,强烈推荐使用这个方法!!!
csv结果截屏:

