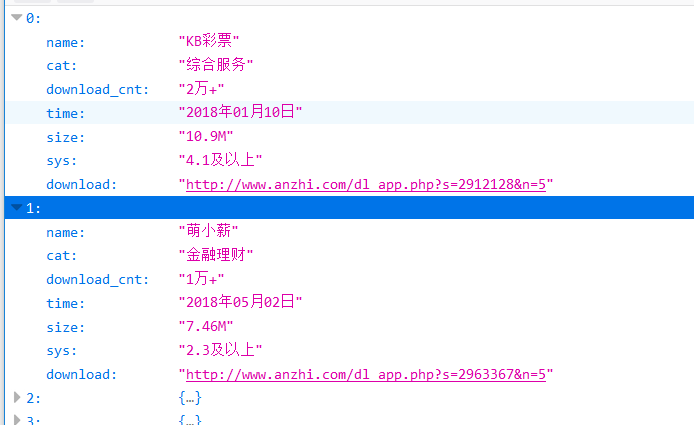
爬取目标网站安卓应用的信息,爬取分类、更新时间、系统要求、下载量以及下载链接等描述信息
http://www.anzhi.com/
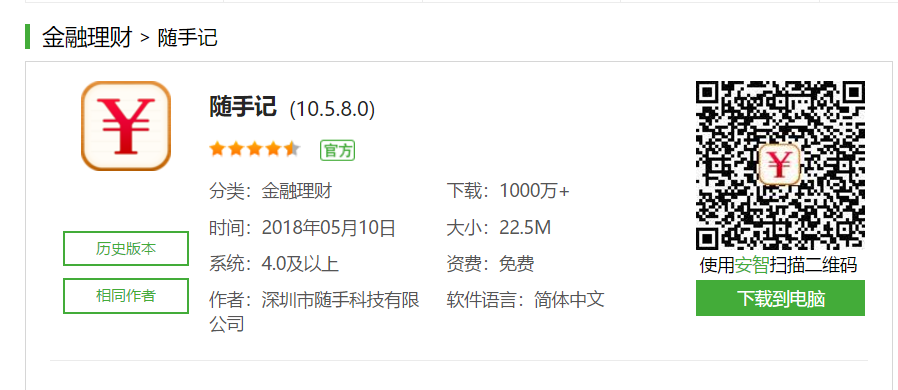
在dom中查看内容
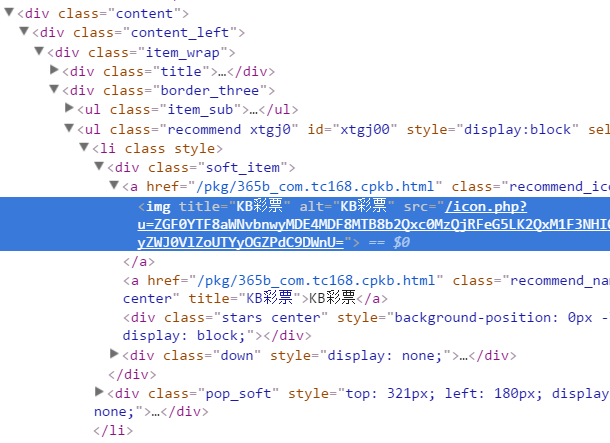
但是在源码中发现并没有相关的信息,是使用js生成的

查看ajax请求,找到html片段,和分类详情,直接拼接相应的url,在使用soup解析即可


应用信息获取
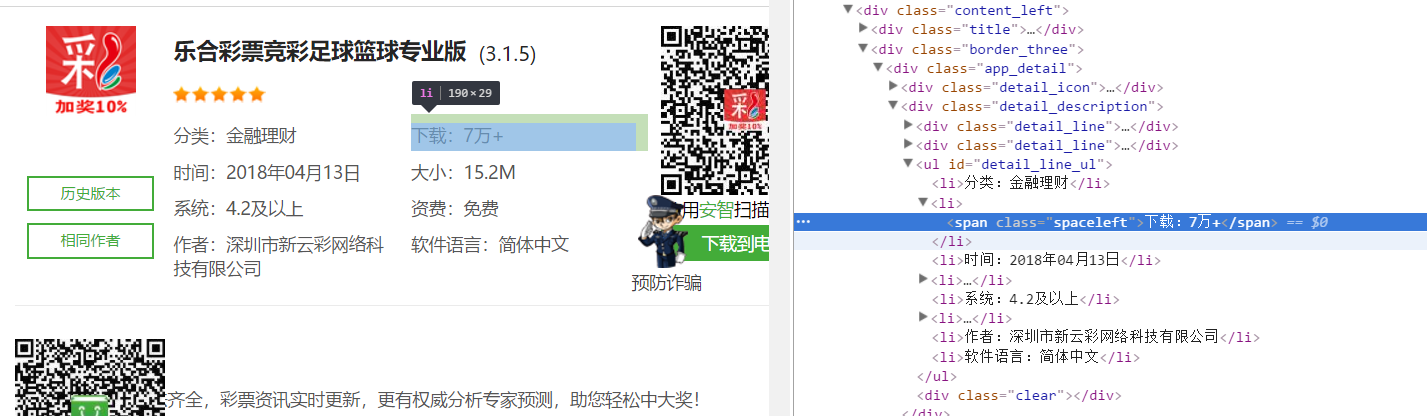
下载使用js获取
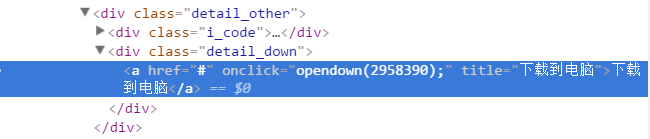
opendown函数,直接模拟请求即可获取下载链接
function opendown(id){
$.get("/ajaxdl_app.php?s="+id, function(result){
if(result == 0)
{
$("#codedown").zxxbox({title: "安智网"});
$('#down_from').attr('action', '/checkdown.php?s=' + id + '&n=1');
$("#checkcod")[0].src="/checkcode/check_seccode.php?rand="+Math.random();
}else{
window.location.href="/dl_app.php?s="+id+"&n=5";
}
});
}
源码
import requests
from bs4 import BeautifulSoup
import json
import time
# 获取 网页源码
def getPage(url):
html = requests.get(url).text
return html
# 获取所有分类信息,并找到所有分类的url
def getCat():
url = 'http://www.anzhi.com/widgetcatetag_1.html'
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
cats = soup.select('a')
cat_list = [i['href'] for i in cats if 'tsort' in i['href']]
newCat = [f"http://www.anzhi.com/widgettsort_{i[i.find('_') + 1:i.find('_h')]}.html" for i in cat_list]
return newCat
# 把所有分类页面内的app全部返回
def getSoftItems(url):
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
links = soup.select('a.recommend_name,center')
items = ['http://www.anzhi.com' + i['href'] for i in links]
return items
# 返回 所有分类下的软件链接详情页面
def getAllLinks():
cats = getCat()
all_links = []
for i in cats:
all_links += getSoftItems(i)
return all_links
# 根据 软件详情url 获得 对应的信息 json 文件
def getSoftJson(url):
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
title = soup.select('div.detail_line > h3')[0].text
infos = soup.select('#detail_line_ul > li')
soft_id = soup.select('div.detail_down > a')[0]['onclick'][9:-2]
js = {}
js['name'] = title
js['cat'] = infos[0].text.split(':')[-1]
js['download_cnt'] = infos[1].text.split(':')[-1]
js['time'] = infos[2].text.split(':')[-1]
js['size'] = infos[3].text.split(':')[-1]
js['sys'] = infos[4].text.split(':')[-1]
js['download'] = f"http://www.anzhi.com/dl_app.php?s={soft_id}&n=5"
print(js)
time.sleep(0.1)
return js
# getSoftJson('http://www.anzhi.com/pkg/365b_com.tc168.cpkb.html')
links = getAllLinks()
print(links)
all_json = []
try:
for i in links:
all_json.append(getSoftJson(i))
except Exception as e:
print(e)
#
with open('all_app.json', encoding='utf8', mode='w+') as f:
json.dump(all_json, f)
json文件