一、基本概念
1、block
hdfs文件系统存储文件的基本单位(副本也是使用块为计量单位存放的)
hadoop2.x是默认128M
2、packet
它是client端向DataNode,或DataNode的PipLine之间传数据的基本单位,默认64KB
3、chunk
它是client向DataNode,或DataNode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512)
在client端向DataNode传数据的时候,HDFSOutputStream会有一个chunk buff,写满一个chunk后,会计算校验和并写入当前的chunk。之后再把带有校验和的chunk写入packet,当一个packet写满后,packet会进入dataQueue队列,其他的DataNode就是从这个dataQueue获取client端上传的数据并存储的。同时一个DataNode成功存储一个packet后之后会返回一个ack packet,放入ack Queue中。
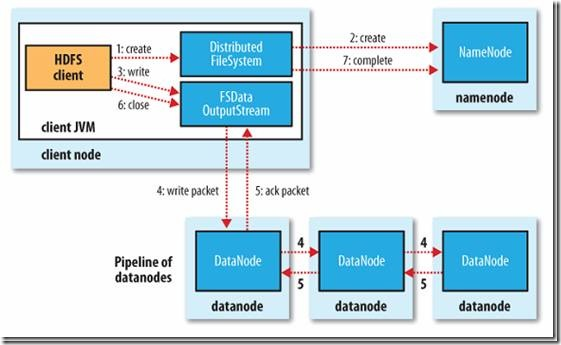
二、HDFS写数据流程
https://www.cnblogs.com/zengfa/p/9323346.html
https://blog.csdn.net/HeatDeath/article/details/79012258
1、客户端通过Distributed FileSystem模块向namenode请求上传文件,namenode检查目标文件是否存在,父目录是否存在,是否有权限等。如果校验通过创建名为file.copying的临时文件,并将操作记录到编辑日志
2、客户端开始写文件:DFSOutputStream会将文件分割成packets数据包,然后将这些packets写到其内部的一个叫做data queue(数据队列)。data queue会向NameNode节点请求适合存储数据副本的DataNode节点的列表,然后这些DataNode之前生成一个Pipeline数据流管道,我们假设副本集参数被设置为3,那么这个数据流管道中就有三个DataNode节点。
3、DFSOutputStream会将packets向Pipeline数据流管道中的第一个DataNode节点写数据,第一个DataNode接收packets然后把packets写向Pipeline中的第二个节点,同理,第二个节点保存接收到的数据然后将数据写向Pipeline中的第三个DataNode节点。
4、DFSOutputStream内部同样维护另外一个内部的写数据确认队列——ack queue。当Pipeline中的第三个DataNode节点将packets成功保存后,该节点回向第二个DataNode返回一个确认数据写成功的信息,第二个DataNode接收到该确认信息后在当前节点数据写成功后也会向Pipeline中第一个DataNode节点发送一个确认数据写成功的信息,然后第一个节点在收到该信息后如果该节点的数据也写成功后,会将packets从ack queue中将数据删除。
5、完成写操作后,客户端调用close()关闭写操作,刷新数据;
6、在数据刷新完后NameNode后关闭写操作流。到此,整个写操作完成。
注意:(1)DataNode完成接收block块后,block的metadata(MD5校验用)通过一个心跳将信息汇报给NameNode
(2)在写数据的过程中,如果Pipeline数据流管道中的一个DataNode节点写失败了会发生什问题、需要做哪些内部处理呢?
1)Pipeline数据流管道会被关闭,ack queue中的packets会被添加到data queue的前面以确保不会发生packets数据包的丢失;
2)在还在正常运行datanode上的当前block上做一个标志,这样当宕掉的datanode重新启动以后namenode就会知道该datanode上哪个block是刚才宕机残留下的局部损坏block,从而把他删除掉。
3)已经宕掉的datanode从管道线中被移除,未写完的block的其他数据继续呗写入到其他两个还在正常运行的datanode中,namenode知道这个block还处在under-replicated状态(即备份数不足的状态)下,然后它会安排一个新的replica从而达到要求的备份数,后续的block写入方法同前面正常时候一样
4)剩下的数据会被写入到Pipeline数据流管道中的其他两个节点中。
如果Pipeline中的多个节点在写数据是发生失败,那么只要写成功的block的数量达到dfs.replication.min(默认为1),那么就任务是写成功的,然后NameNode后通过异步的方式将block复制到其他节点,最后事数据副本达到dfs.replication参数配置的个数。
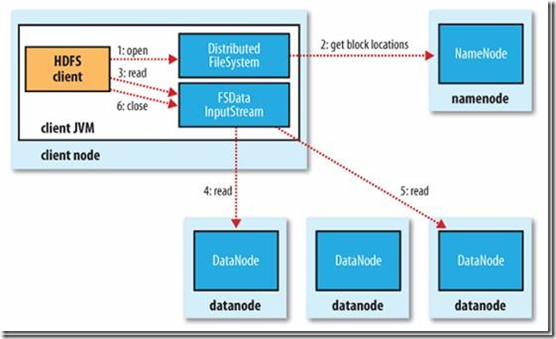
三、读数据流程
1、client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
2、就近挑选一台datanode服务器,请求建立输入流 。
3、DataNode向输入流中中写数据,以packet为单位来校验。
4、关闭输入流