HDFS 数据读写流程
HDFS 是 Hadoop 生态里面的数据存储层,它是一个具有容错性的非常可靠的分布式文件系统。HDFS 以主从( Master / Slave )架构的方式工作,Namenode 是 Master 节点上的守护进程,而 Datanode 是 Slave 节点上的守护进程。
本教程将详细介绍 HDFS 数据读写操作工作原理。
Hadoop HDFS 数据写操作
要把文件写入到 HDFS,客户端需要先和 Namenode(master)节点交互,Namenode 给客户端提供 Datanode(slave)节点的具体地址之后,客户端才能把数据写入到 Datanode。那客户端怎么把数据写入到 Datanode 呢?其实,客户端是直接跟 Datanode 通信并写入数据的,Datanode 会创建数据写入管道(pipeline),第一个 Datanode 把数据块复制到另一个 Datanode(第二个 Datanode ),之后第二个 Datanode 再把数据块复制到第三个 Datanode。数据块副本创建完成之后,Datanode 会给前一个发送确认消息。
HDFS 数据写入工作流程
前面介绍的数据写入流程是分布式写入的,客户端把数据并发写到很多 Datanode节点。
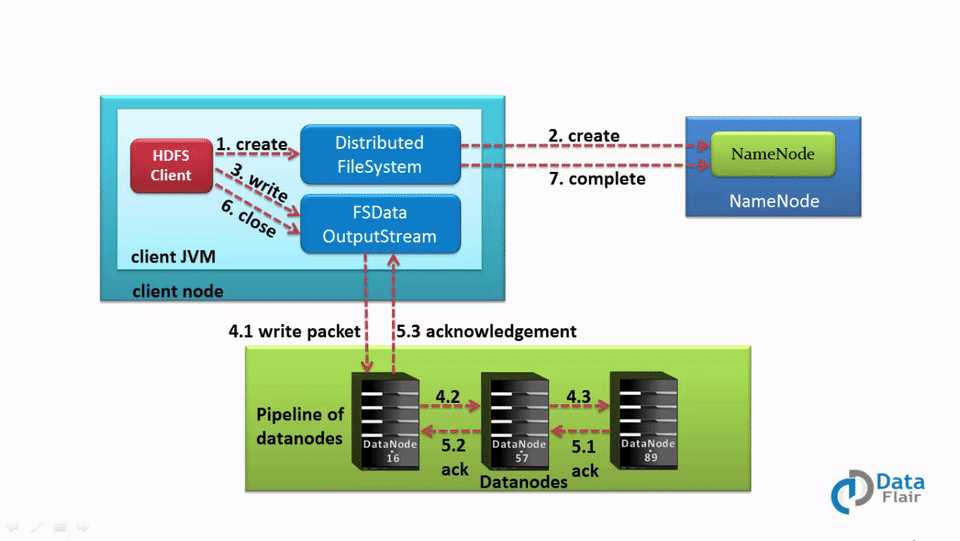
下面一步一步详细介绍数据的写入流程:
1、客户端调用 DistributedFileSystem 的 create() 方法,开始创建新文件。DistributedFileSystem 创建 DFSOutputStream,产生一个 RPC 调用,让 NameNode 在文件系统的命名空间中创建这一新文件。
2、NameNode 接收到用户的写文件的RPC请求后,首先要执行各种检查,如客户是否有相关的创佳权限和该文件是否已存在等,检查通过后才会创建一个新文件,并将操作记录到编辑日志,然后 DistributedFileSystem 会将 DFSOutputStream 对象包装在 FSDataOutStream 实例中,返回客户端;否则文件创建失败并且给客户端抛 IOException 。
3、客户端开始写文件,DFSOutputStream 会将文件分割成 packets 数据包,HDFS 中每个 block 默认情况下是128M,由于每个块比较大,所以在写数据的过程中是把数据块拆分成一个个的数据包( packet )以管道的形式发送的。然后将这些 packets 写到其内部的一个叫做 data queue(数据队列)。data queue 会向 NameNode 节点请求适合存储数据副本的DataNode 节点的列表,然后这些 DataNode 之前生成一个 Pipeline 数据流管道,我们假设副本因子参数为3,那么这个数据流管道中就有三个 DataNode 节点。
4、首先 DFSOutputStream 会将 packets 向 Pipeline 数据流管道中的第一个 DataNod e节点写数据,第一个 DataNode 接收 packets 然后把 packets 写向 Pipeline 中的第二个节点,同理,第二个节点保存接收到的数据然后将数据写向 Pipeline 中的第三个 DataNode 节点。
5、DFSOutputStream 内部同样维护另外一个内部的写数据确认队列——ack queue。当 Pipeline 中的第三个 DataNode 节点将 packets 成功保存后,该节点回向第二个 DataNode 返回一个确认数据写成功的信息,第二个 DataNode 接收到该确认信息后在当前节点数据写成功后也会向 Pipeline 中第一个 DataNode 节点发送一个确认数据写成功的信息,然后第一个节点在收到该信息后如果该节点的数据也写成功后,会将 packets 从 ack queue 中将数据删除。
在写数据的过程中,如果 Pipeline 数据流管道中的一个 DataNode 节点写失败了会发生什问题、需要做哪些内部处理呢?如果这种情况发生,那么就会执行一些操作:
首先,Pipeline 数据流管道会被关闭,ack queue 中的 packets 会被添加到 data queue 的前面以确保不会发生 packets 数据包的丢失。
接着,在正常的 DataNode 节点上的已保存好的 block 的 ID 版本会升级——这样发生故障的 DataNode 节点上的 block 数据会在节点恢复正常后被删除,失效节点也会被从 Pipeline 中删除。
最后,剩下的数据会被写入到 Pipeline 数据流管道中的其他两个节点中。
如果 Pipeline 中的多个节点在写数据是发生失败,那么只要写成功的 block 的数量达到 dfs.replication.min(默认为1) ,那么就任务是写成功的,然后 NameNode 后通过一步的方式将 block 复制到其他节点,直到数据副本达到 dfs.replication 参数配置的个数。
6、完成写操作后,客户端调用 close() 关闭写操作IO流,刷新数据。
7、在数据刷新完后 NameNode 关闭写操作流。到此,整个写操作完成。
文件写入HDFS —— Java 代码示例
下面 HDFS 文件写入的 Java 示例代码
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(conf);
// Check if the file already exists
Path path = new Path("/path/to/file.ext");
if (fileSystem.exists(path)) {
System.out.println("File " + dest + " already exists");
return;
}
// Create a new file and write data to it.
FSDataOutputStream out = fileSystem.create(path);
InputStream in = new BufferedInputStream(new FileInputStream(new File(source)));
byte[] b = new byte[1024];
int numBytes = 0;
while ((numBytes = in.read(b)) > 0) {
out.write(b, 0, numBytes);
}
// Close all the file descripters
in.close();
out.close();
fileSystem.close();
Hadoop HDFS 数据读操作
为了从 HDFS 读取数据,客户端首先得和 Namenode(master节点)交互,因为 Namenode 是 Hadoop集群的中心,它保存着集群的所有元数据。然后 Namenode 会检查客户端是否有相应权限,如果客户端有权限读取数据,那么 Namenode 才会给它返回存储文件的 Datanode ( Slave ) 节点列表。之后客户端将直接从 Datanode 读取相应的数据 block。
HDFS 文件读取流程
下面详细介绍 HDFS 读文件的流程:
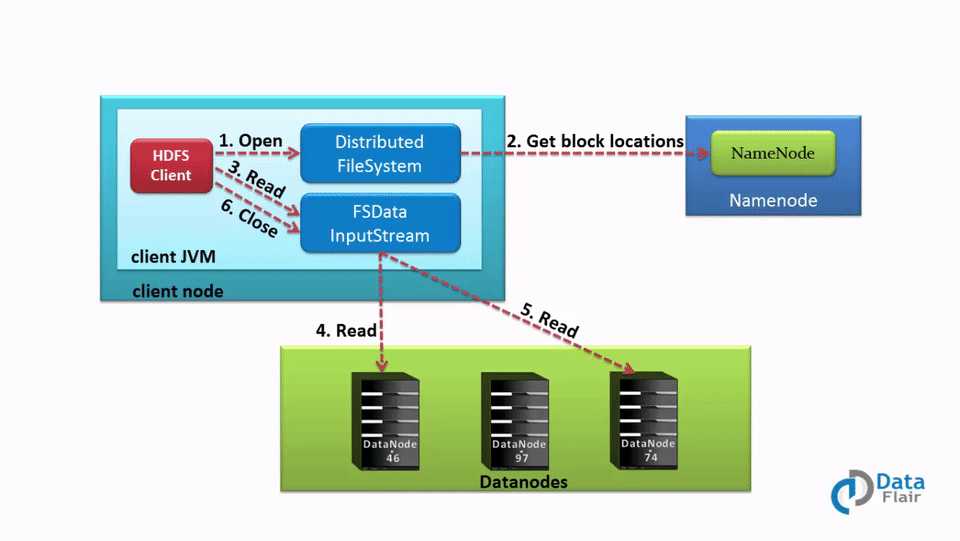
1、客户端调用 FileSystem 对象的 open()函数,打开想要读取的文件。其中FileSystem 是 DistributeFileSystem 的一个实例。
2、DistributedFileSystem 使用 RPC 调用 Namenode 来确定文件中前几个块的位置。对于每个块,Namenode 会返回存储该数据块副本的 Datanode 节点的地址,并根据 Datanode 与客户端的距离排序。
3、DistributedFileSystem 会给客户端返回一个输入流对象 FSDataInputStream,客户端将从该对象读取数据,该对象分装了一个用于管理 Datanode 和 Namenode IO 的对象 —— DSFInputStream。 客户端调用 FSDataInputStream 的 read() 函数。由于 DFSInputStream 已经存储了 Datanode 地址,那么接下来就是连接到距离客户端最近的 Datanode 进行读取数据文件的第一个块。
4、客户端可以重复的在数量流调用 read() 函数,当块读取结束后,DFSInputStream 将关闭和 datanode 的连接,然后再找下一个离客户端最近的存储数据块的 Datanode 。
5、如果 DFSInputStream 在和 Datanode 通信的时候发生故障,它将会从存储该数据块的距离客户端最近的 Datanode 读取数据。而且它会把发生故障的 Datanode 记录下来,在读取下一个数据块的时候,就不会再从这个 Datanode 读取了。DFSInputStream 会对数据做校验和( checksum )验证。如果发现损坏的块,在 DFSInputStream 从其他 Datanode 读取损坏的块的副本之前,把损坏的块告知给 Namenode。
6、客户端读取数据完成后,调用 close() 函数关闭数据流。
HDFS 读文件 Java 代码示例
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(conf);
Path path = new Path("/path/to/file.ext");
if (!fileSystem.exists(path)) {
System.out.println("File does not exists");
return;
}
FSDataInputStream in = fileSystem.open(path);
int numBytes = 0;
while ((numBytes = in.read(b))> 0) {
System.out.prinln((char)numBytes));// code to manipulate the data which is read
}
in.close();
out.close();
fileSystem.close();