关于大数据学习的最好的网站就是官网http://www.apache.org/
参考资料:http://www.apache.org/
免责声明:很多资料都是网上一步步搜集到的,感谢各位前辈默默无闻的奉献与付出,资料过多,不一一感谢,如果侵权,请及时联系作者本人或者投诉至平台,我会第一时间删除,纯分享。
HDFS的写入流程:
先看图片 摘抄至这个哥们的博客https://blog.csdn.net/whdxjbw/article/details/81072207
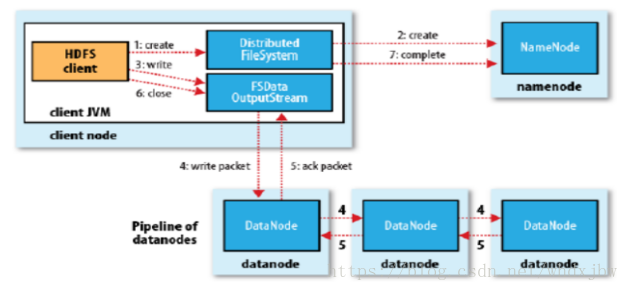
1/ 对于一开始的hdfs ,Client 向Namenode 发起访问请求,当Namenode收到请求时校验改请求是否有访问权限等,若无访问权限则直接返回报错,若有访问权限,此时,namenode返回数据存放的在哪一个datanode 节点上,(分块放置策略,默认每个块的大小为128M,该参数与硬件有关,一般不需要修改,默认即可),对于图上 1 2 流程
2/ 在返回的数据中 对于3 流程 FSDataOutputStream 这个流 会将块 根据副本放置策略(https://blog.csdn.net/weixin_38638777/article/details/103412076)分别以块块放置在3个节点上 对于流程 4
3/ 当全部写入完成后,最后一个块会返回一个ACK (响应包/码) 表示写入完成,依次向前一个块报告(第三个向第二个块报告写入完成,第二个块向第一个块报告写入完成 依次 )当第一个块返回ACK信号时,表示该块放置完成,继续放置其他块(当写写入的文件大于128m时,会进行分块处理,每128M 为一块)
4/ 当数据完成写入在各节点时,关闭outputstream 流同时向namenode 报告写入完成信号
HDFS的读流程:

读相对于写,简单一些
读详细步骤:
- client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
- 就近挑选一台datanode服务器,请求建立输入流 。
- DataNode向输入流中中写数据,以packet为单位来校验。
- 关闭输入流