不知不觉8周的算法训练营也接近尾声,这期间训练营对自己的影响有三方面
- 一方面是收获了刻意练习,终身成长这些可以产生长远影响的思想,这里推荐三本书 卡罗尔·德韦克的《终身成长》、安德斯·艾利克森和罗伯特·普尔的《刻意练习》以及彼得·布朗等的《认知天性》
- 一方面是在自己对算法与数据结构的态度与认知上,从之前的抗拒和一提到就觉得很难,到接受和乐在其中的转变,从算法与数据结构大概是这样,到有一个脉络清晰的知识结构的转变
- 一方面就是知识本身,下面将数据结构与算法总体回顾下
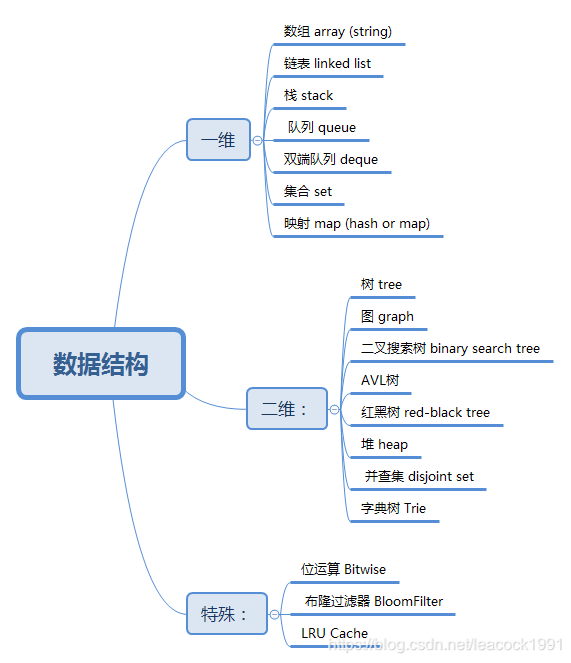
数据结构
一维
- 基础: 数组 array (string),链表 linked list
- 高级: 栈 stack,队列 queue,双端队列 deque,集合 set,映射 map (hash or map),etc
涉及题目:
栈 stack: 括号匹配问题、直方图、接雨水
队列 queue: 滑动窗口
二维
- 基础: 树 tree,图 graph
- 高级: 二叉搜索树 binary search tree (red-black tree,AVL),堆 heap,并查集 disjoint set,字典树 Trie,etc
特殊
- 位运算 Bitwise,布隆过滤器 BloomFilter
- LRU Cache
时间复杂度图
https://www.bigocheatsheet.com/

主定理
https://en.wikipedia.org/wiki/Master_theorem_(analysis_of_algorithms)
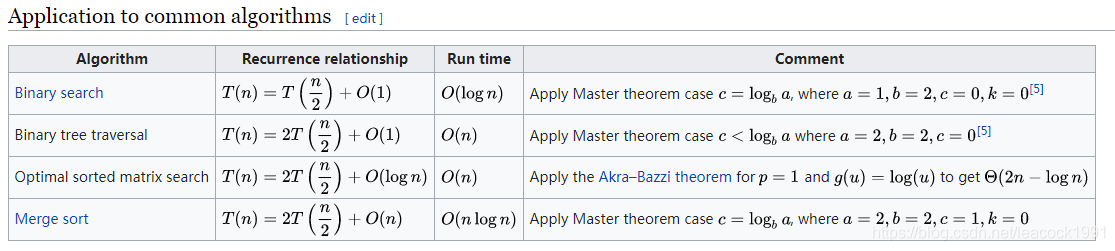
- 一维数组二分查找:每次排除一半,故为O(log n)
- 二叉树的遍历:可以理解成每个节点被访问且仅访问一次,故为O(n)
- 二维矩阵的二分查找:O(n)
- 归并排序:O(n logn)
数据结构思维导图
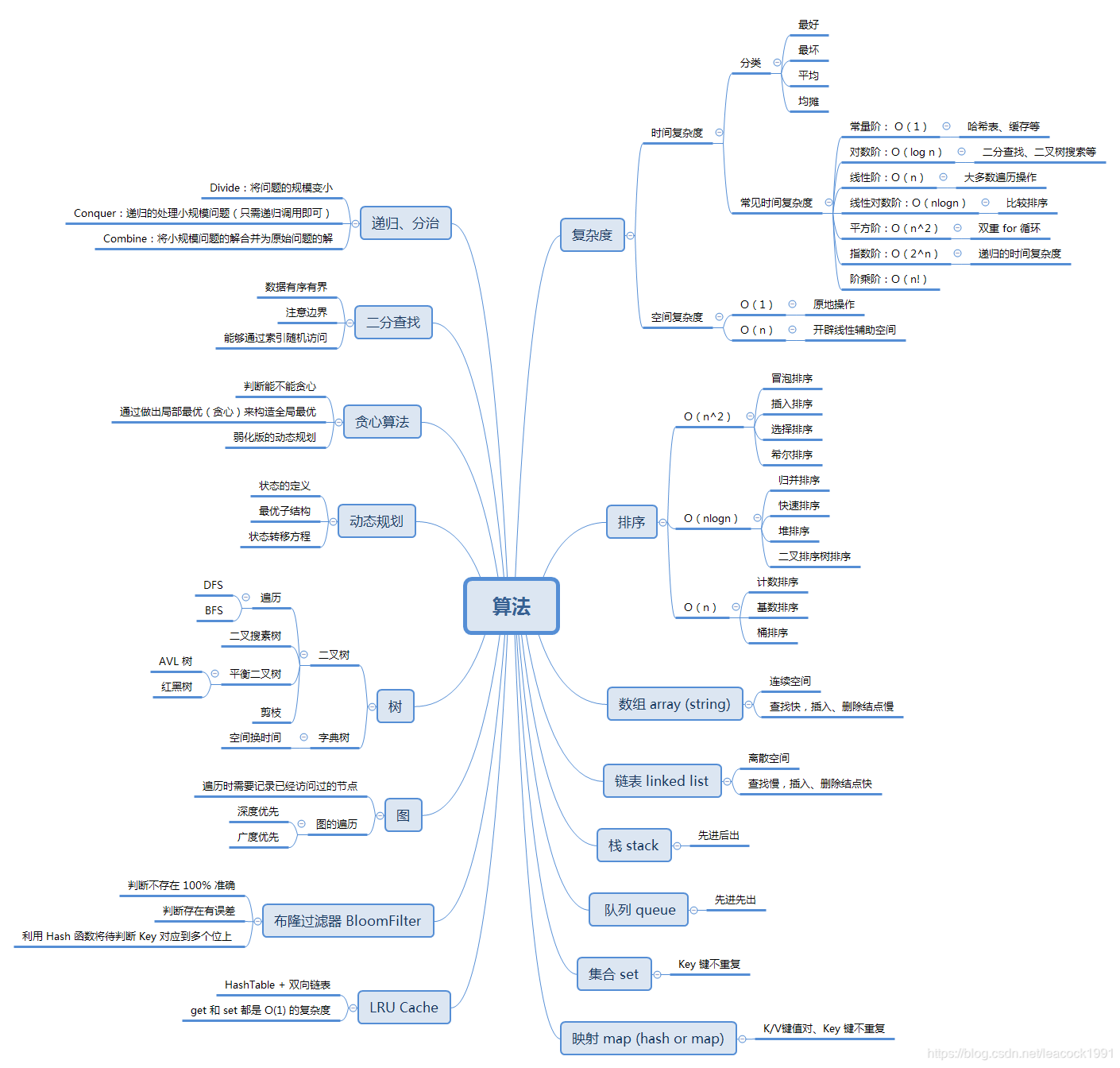
算法
- if-else,switch ——> branch
- for,while loop ——> literation
- 递归 Recursion (Divide & Conquer ,Backtrace)
所有高级算法或数据结构最后都会转换成以上三种
- 搜索 Search:深度优先搜索 Depth first search, 广度优先搜索 Breadth first search,A*,etc
- 动态规划 Dynamic Programming (递归+备忘录 或 迭代+DP方程)
- 二分查找 Binary Search
- 贪心 Greedy
- 数学 Math,几何 Geometry
算法 思维导图
链接:https://pan.baidu.com/s/1FL93CnqsWA0jbHt_ePSpjQ
提取码:ulud
代码模板
这里列举部分模板,其他模板 并查集 Disjoint Set、布隆过滤器、LRU Cache、初级排序、特殊排序等模板可以参看之前总结
递归模板
def recursion(level, param1, param2, ...):
# 递归终止条件
if level > MAX_LEVEL:
process_result
return
# 处理当前层逻辑
process(level, data...)
# 往下一层
self.recursion(level + 1, p1, ...)
# 清理当前层
分治模板
def divide_conquer(problem, param1, param2, ...):
# 递归终止条件
if problem is None:
print_result
return
# 处理当前层逻辑(分解子问题)
data = prepare_data(problem)
subproblems = split_problem(problem, data)
# 往下一层(解决子问题)
subresult1 = self.divide_conquer(subproblems[0], p1, ...)
subresult2 = self.divide_conquer(subproblems[1], p1, ...)
subresult3 = self.divide_conquer(subproblems[2], p1, ...)
…
# 合并子结果(合并结果)
result = process_result(subresult1, subresult2, subresult3, …)
# 清理当前层
归并排序模板
def merge_sort(arr, left, right):
"""
归并排序(Merge Sort)
"""
if right <= left: # 递归终止条件
return
# 先输入序列分成两个长度为n/2的子序列并对这两个子序列分别采用归并排序
mid = (left + right) >> 1 # (left + right) / 2
merge_sort(arr, left, mid) # 注意 mid
merge_sort(arr, mid + 1, right)
# 排序好的子序列合, 重点 merge 函数的实现
merge(arr, left, mid, right)
def merge(arr, left, mid, right):
# left , mid 有序 mid + 1 , right 有序
temp = [0 for _ in range( right - left + 1)] # 中间数组, 需要额外的内存空间
i = left
j = mid + 1
k = 0
while i <= mid and j <= right: # 合并 left , mid 有序数列 和 mid + 1 , right 有序数列
if arr[i] <= arr[j]:
temp[k] = arr[i]
k, i = k + 1, i + 1
else:
temp[k] = arr[j]
k, j = k + 1, j + 1
while i <= mid: # left , mid 有序数列 剩余
temp[k] = arr[i]
k, i = k + 1, i + 1
while j <= right: # mid + 1 , right 有序数列 剩余
temp[k] = arr[j]
k, j = k + 1, j + 1
# 将 排序好的 temp 放入 arr 中
for p in range(len(temp)):
arr[left + p] = temp[p]
快速排序模板
def quick_sort(arr, begin, end):
"""
快速排序(Quick Sort)
"""
if end <= begin: # 递归终止条件
return
# 先找标杆 pivot,将小元素放 pivot左边,大元素放右侧; 重点 partition 函数的实现
pivot = partition(arr, begin, end)
# 然后依次对标杆 pivot 右边和右边的子数组继续快排
quick_sort(arr, begin, pivot-1) # 注意 不包括标杆
quick_sort(arr, pivot + 1,end)
def partition(arr, begin, end):
"""
partition 函数 用于查找 标杆位置并处理排序数组
"""
pivot = end # 选择 end 为标杆
min_index = begin # counter: ⼩于pivot的元素的下标
for i in range(begin, end): # 这里不包含 标杆位置
if arr[i] < arr[pivot]: # i 位置数据 小于 a[pivot]
arr[min_index], arr[i] = arr[i], arr[min_index] # 交换 arr[min_index], arr[i] 数据位置
min_index += 1 # 递增
# 循环结束 min_index 就为 标杆应该所在位置
arr[min_index], arr[pivot] = arr[pivot], arr[min_index]
return min_index
DFS 模板
递归实现:
#递归前处理
visited = set() # 节点是否被访问
def dfs(node,visited):
# 递归终止条件
if node in visited: # 是否被访问
return
# 递归到下一层前处理(当前层处理)
visited.add(node)
# 其它处理
# 递归到下一层
for next_node in node.children():
if not next_node in visited:
dfs(next_node, visited)
# 递归下层次返回后处理
迭代实现:
dfs=栈,压栈,出栈
def dfs(node,visited):
if tree.root is None:
return []
# 迭代前处理
visited, stack = [], [tree.root] # 辅助栈 压栈
# 迭代终止条件
while stack:
# 迭代
node = stack.pop() # 出栈
visited.add(node) # 标记访问
rocess (node) # 当前节点处理
nodes = generate_related_nodes(node) # 生成相关节点
stack.push(nodes) # 压栈
# 迭代后处理
BFS 模板
迭代实现:
bfs=队列,入队列,出队列
def bfs(graph, start, end):
# 迭代前处理
queue = [] # 辅助队列
queue.append([start]) # 入队列
visited.add(node) # 标记访问
# 迭代终止条件
while queue:
# 迭代
node = queue.pop(0) # 出队列
visited.add(node) # 标记访问
rocess (node) # 当前节点处理
nodes = generate_related_nodes(node) # 生成相关节点
queue.push(nodes) # 入队列
# 迭代后处理
二分查找代码模板
left, right = 0, len(array) - 1
while left <= right:
# mid = (left + right) / 2
mid = low + (high-low)/2
if array[mid] == target:
# 找到目标
break or return result
elif array[mid] < target:
left = mid + 1
else:
right = mid - 1
Trie树模板
class Trie:
def __init__(self):
self.root = {} # 根节点
self.endofword = "#" # 标识是否是一个完整的单词
def insert(self, word: str) -> None:
# 插入操作
node = self.root # 根节点
for char in word: # 遍历单词 word 中每个字符
node = node.setdefault(char,{}) # 字典形式依次将字符保存到树的每一层中
# dict.setdefault(key, default=None) 如果 key 在 字典中,返回对应的值。
# 如果不在字典中,则插入 key 及设置的默认值 default,并返回 default ,default 默认值为 None。
node[self.endofword] = self.endofword # 完整单词标识
def search(self, word: str) -> bool:
# 查找操作
node = self.root
for char in word: # 遍历单词 word 中每个字符
if char not in node: # 未找到
return False
node = node.get(char) # 找到进入下一结点
return self.endofword in node # 是否为完整的单词
def startsWith(self, prefix: str) -> bool:
# 字典树中是否有以 prefix 为前缀的单词
node = self.root
for char in prefix: # 遍历 前缀 prefix
if char not in node:
return False
node = node.get(char)
return True
学习要点
基本功是区别业余和职业选手的根本。深厚功底来自于 — 过遍数
最大的误区:只做一遍
五毒神掌
刻意练习 - 练习缺陷弱点地方、不舒服、枯燥
反馈 - 看题解、看国际版的高票回答
切题四件套
- Clarification
- Possible Solutions
- compare (time/space)
- optimal (加强)
- Coding(多写)
- Test cases
五毒神掌
第一遍
五分钟:读题 + 思考
直接看解法:多看几种,比较解法优劣
背诵、默写好的解法
第二遍
马上自己写 ——> Leetcode提交
多种解法比较、体会 ——> 优化!
第三遍
过了一天后,再重复做题
不同解法的熟练程度——>专项练习
第四遍
过了一周后:反复回来练习相同的题目
第五遍
面试前一周恢复性训练
经典习题
爬楼梯: https://leetcode-cn.com/problems/climbing-stairs/
硬币兑换: https://leetcode-cn.com/problems/coin-change/
有效括号: https://leetcode-cn.com/problems/valid-parentheses/
括号生成: https://leetcode-cn.com/problems/generate-parentheses/
柱状图中最大的矩形: https://leetcode-cn.com/problems/largest-rectangle-in-histogram/
滑动窗口最大值: https://leetcode-cn.com/problems/sliding-window-maximum/
二叉树遍历:
- 二叉树的层次遍历:https://leetcode-cn.com/problems/binary-tree-level-order-traversal/
- 二叉树的前序遍历: https://leetcode-cn.com/problems/binary-tree-preorder-traversal/
- 二叉树的中序遍历: https://leetcode-cn.com/problems/binary-tree-inorder-traversal/
- 二叉树的后序遍历: https://leetcode-cn.com/problems/binary-tree-postorder-traversal/
验证二叉搜索树: https://leetcode-cn.com/problems/validate-binary-search-tree/submissions/
股票买卖:
打家劫舍:
编辑距离: https://leetcode-cn.com/problems/edit-distance/
最长上升子序列: https://leetcode-cn.com/problems/longest-increasing-subsequence/
最长公共子序列: https://leetcode-cn.com/problems/longest-common-subsequence/
字母异位词分组: https://leetcode-cn.com/problems/group-anagrams/
回文串:
通配符匹配: https://leetcode-cn.com/problems/wildcard-matching/
高级数据结构(Trie、 BloomFilter、 LRU cache、 etc)
