Embedding
NLP领域通常用语言模型来做预训练,得到单词的Embedding向量,用于其他NLP下游任务的输入。
语言模型
什么是语言模型?就是某种语言中,一个句子
S出现的概率:
P(S)
自然语言的基本构成元素是词,那么语句
S的概率可以表示为:
P(S)=P(w1,w2,...,wn)
=P(w1)P(w2∣w1)...P(wn∣w1,w2,...,wn−1)
采用对数形式,则转化为:
L=LogP(S)=i=1∑nlogP(wi∣w1,..wi−1)
NNLM
论文《A Neural Probabilistic Language Model》中提出了用神经网络建模语言模型的方法,模型结构如下:
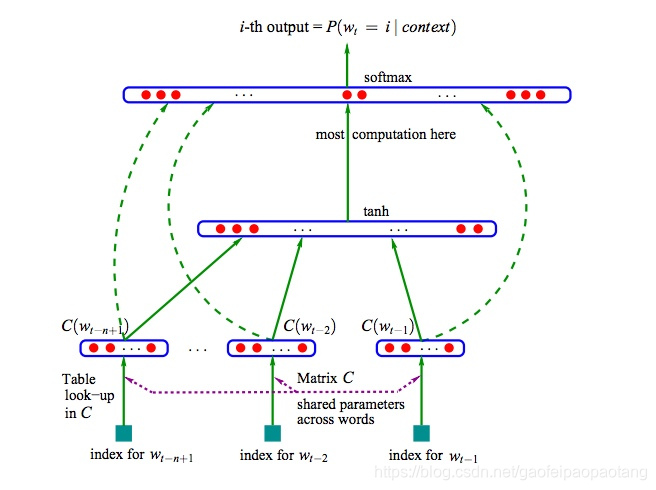
- 为了降低复杂度,模型做了个简化,取最近的
n的单词建模下一个单词的出现的概率:
P(wi∣w1,...,wi−1)≈P(wi∣wi−n+1,...,wi−1)
P(wi∣wi−n+1,...,wi−1)=sofmax(y)
y=b+Wx+Utanh(d+Hx)
x=(C(wi−1),...C(wi−n+1))
ELMo
NAACL2018最佳论文《Deep contextualized word representations》则采用双向语言模型做预训练,同时采用了一种RNN的网络结构LSTM。LSTM网络结果在前面的文章里有单独分析过,这里不再展开。
扫描二维码关注公众号,回复:
8832157 查看本文章

双向语言模型就是采用前置词预测当前词与后置词预测当前词结合的方式训练模型,最大化两个方向的似然函数之和:
k=1∑N(logp(wk∣w1,...,wk−1;Θx,Θ
LSTM,Θs)+logp(wk∣wk+1,...,wN;Θx,Θ
LSTM,Θs))
其中
Θx表示embedding层参数,
Θs表述Softmax输出层参数,
Θ
LSTM,Θ
LSTM表示双向LSTM网络的参数。
其他
-
论文《Improving Language Understanding by Generative Pre-Training》则回到单向语言模型,并将LSTM替换为Transformer。Transformer也在前面的文章里分析过,不再展开。
-
论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》则在GPT的基础上,又回到了双向语言模型。
