前言
字节的AI Lab2020年发表在 EMNLP上的一篇文章《On the Sentence Embeddings from Pre-trained Language Models》,针对语义文本相似任务(STS),论文中提出的基于流式生成模型—BERT-flow,在评测集上得出的结果是比BERT好10个点,比SBERT好4个点。
BERT等语言模型在多数NLP任务中取得优异的表现,但如果直接取BERT输出的句向量作表征,取得的效果甚至还不如Glove词向量。
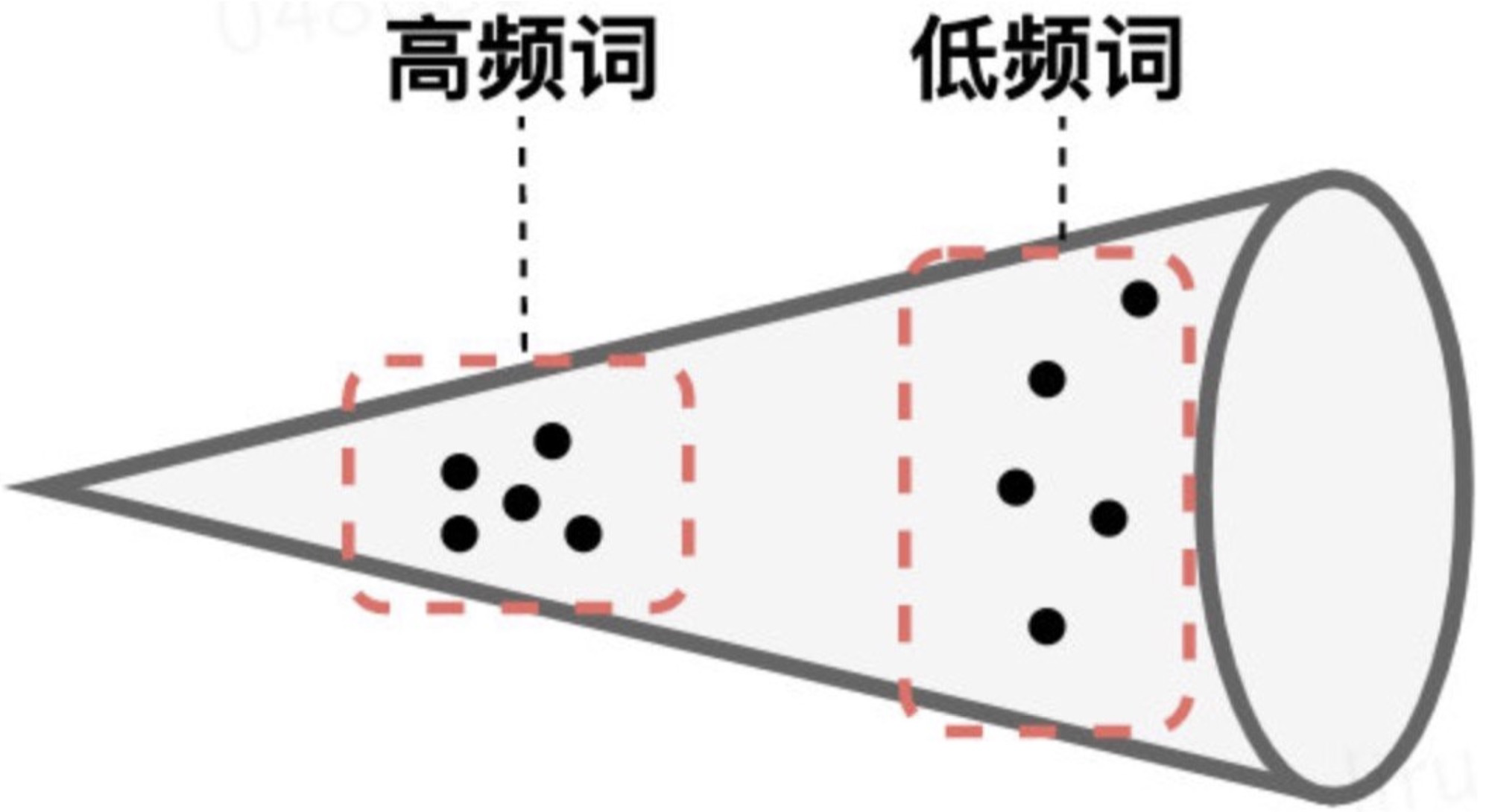
Bert-flow论文中指出,产生该现象的原因是BERT Encoder模型中产生的句子有两个明显的问题:1.句子向量具有各向异性;2.高频词汇分布集中,低频词汇分布分散,整个向量空间类似于锥形结构。
1.BERT句向量相似度存在问题
问题一:嵌入空间各向异性。什么叫各向异性?举个例子,一些电阻原件,正接是良导体,反接是绝缘体或者电阻很大,沿不同方向差异很大。在 BERT 出来的向量中表现为,用不同的方式去衡量它,他表现出不同的语义,差别很大,也就是不能完整的衡量出 BERT 向量中全部语义信息。主要表现是高频词和低频词在空间上的分布不均匀,高频词分布较密集且整体上更靠近原点,低频词分布较稀疏且整体分布离原点相对较远。
具体理解如上图所示。因为低频词的词向量分布较稀疏,因此它们周围存在较多的“空洞”,所谓的“空洞”即几乎不能表征语义或者说在进行语义表征时,该部分空间没有被使用到是语义不明确的(poorly definded)。这样的分布性质会导致上下文语义信息被词频信息误导。
问题二:低频词分布稀疏,高频词分布密集。这种性质的存在,使低频词训练不充分,从而使使用BERT Sentence Embeddings进行语义的表征是有问题的。
BERT计算句向量相似度存在问题的原因:
(1)句向量是对句子中的词的词向量取平均池化得到的,是保凸性运算,而BERT词向量空间存在“空洞”,即BERT句向量空间在某种程度上说是语义不平滑的。BERT词向量空间存在“空洞”,当句向量落到这些“空洞”时,语义的不确定性就影响了相似度。
(2)因为高词频的词和低频词的空间分布特性,导致了相似度计算时,相似度过高或过低的问题。在句子级:如果两个句子都是由高频词组成,那么它们存在共现词时,相似度可能会很高,而如果都是由低频词组成时,得到的相似度则可能会相对较低;在单词级:假设两个词在语义上是等价的,但是它们的词频差异导致了它们空间上的距离偏差,这时词向量的距离就不能很好的表征语义相关度。
2. 余弦相似度的假设
一般来说,我们语义相似度比较或检索,都是给每个句子算出一个句向量来,然后算它们的夹角余弦来比较或者排序。那么,我们有没有思考过这样的一个问题:余弦相似度对所输入的向量提出了什么假设呢?或者说,满足什么条件的向量用余弦相似度做比较效果会更好呢?
两个向量x,y的内积的几何意义就是“各自的模长乘以它们的夹角余弦”,所以余弦相似度就是两个向量的内积并除以各自的模长,对应的坐标计算公式是

然而,上述等式只在“标准正交基”下成立。换句话说,向量的“夹角余弦”本身是具有鲜明的几何意义的,但上式右端只是坐标的运算,坐标依赖于所选取的坐标基,基底不同,内积对应的坐标公式就不一样,从而余弦值的坐标公式也不一样。
因此,假定BERT句向量已经包含了足够的语义(比如可以重构出原句子),那么如果它用上述公式算余弦值来比较句子相似度时表现不好,那么原因可能就是此时的句向量所属的坐标系并非标准正交基。那么,我们怎么知道它具体用了哪种基底呢?原则上没法知道,但是我们可以去猜。猜测的依据是我们在给向量集合选择基底时,会尽量地平均地用好每一个基向量,从统计学的角度看,这就体现为每个分量的使用都是独立的、均匀的,如果这组基是标准正交基,那么对应的向量集应该表现出“各向同性”来。
当然,这不算是什么推导,只是一个启发式引导,它告诉我们如果一个向量的集合满足各向同性,那么我们可以认为它源于标准正交基,此时可以考虑用上式计算相似度;反之,如果它并不满足各向同性,那么可以想办法让它变得更加各向同性一些,然后再用上式算相似度,而BERT-flow正是想到了“flow模型”这个办法。
3.BERT-flow
为了解决BERT句向量分布不平滑问题,可以利用标准化流(Normalizing Flows)将BERT句向量分布变换为一个光滑的、各向同性的标准高斯分布。 标准高斯分布是各向同性的,在传统的词嵌入方法中,研究表明词向量矩阵的前面几个奇异值通常和高频词高度相关,通过将嵌入分布变换到各向同性的分布上,奇异值就可以被压缩。另外,标准高斯分布是凸的,或者说是没有"空洞",因此语义分布更为光滑。
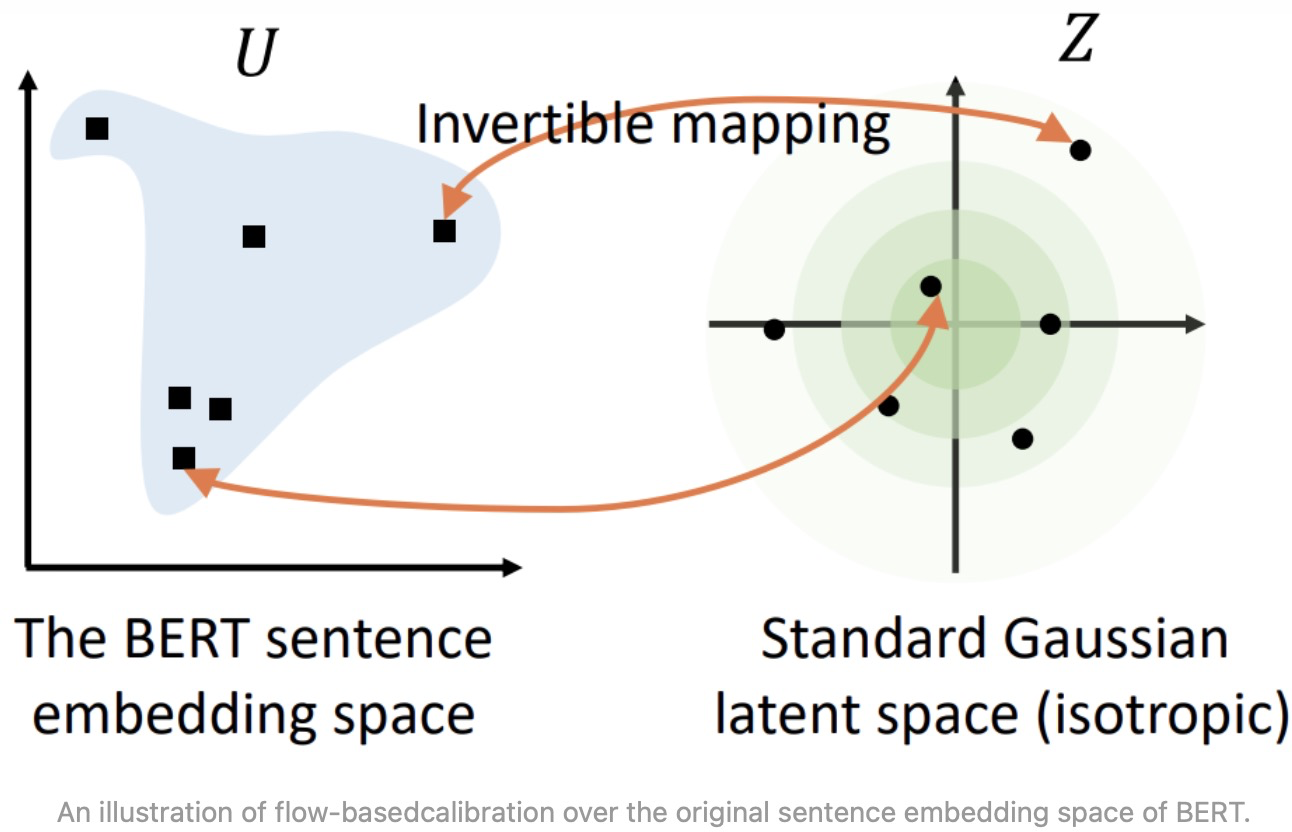

简单理解就是将服从高斯分布的随机变量映射到BERT编码的
,反函数
就能把
映射到高斯分布上,在训练的过程中BERT的参数保持不变,只优化标准化流的参数。优化目标就是最大化从高斯分布中产生BERT表示的概率。通过无监督的方式 maximize 这个优化目标,得到可逆的映射变换 f,这其实就是在 Bert pre-train model 后接了一个 flow 变换的模型,让其继续 pre-train,学出 flow 变换,从而完成向量空间的 transform。
BERT-flow 完整分析了BERT 句子 embedding 里存在的向量各向异性及分布不均匀问题,并列出了完整的实验结果佐证了这一现象。同时提出了一种 flow 变换,将各向异性的 BERT 向量转换到一个标准的高斯分布空间,从而有效的提升了无监督领域的文本表达效果(另外 BERT-flow 还提了个小技巧,采用 BERT 输出的 first-layer+last-layer 平均会更好。
Reference
1.你可能不需要BERT-flow:一个线性变换媲美BERT-flow - 科学空间|Scientific Spaces