前言
flow模型本身很弱,BERT-flow里边使用的flow模型更弱,所以flow模型不大可能在BERT-flow中发挥至关重要的作用。反过来想,那就是也许我们可以找到更简单直接的方法达到BERT-flow的效果。
BERT-whitening则认为,flow模型中涉及到的逆变换和雅可比行列式计算实际需要满足变换简单、易计算的特点。因此每一层的非线性变换能力就“很弱”,为了保证充分的拟合能力,模型就必须堆得非常深。但实际上BERT-flow所使用的模型计算量并大。因此,作者提出可以使用一种简单的线性变换(相当于白化操作)来浅层地对BERT的向量进行转换,能到达和BERT-flow接近甚至超越的效果。
1.向量的内积
计算文本相似度时,首先将文本表示为句向量,然后计算两个句向量之间的余弦相似度,通过相似度的大小判断这两个文本是否相似。
那么这里就有一个问题,余弦相似度为什么就能计算两个向量的相似性呢?想要弄清楚这个问题,就需要我们对于向量的内积有一个充分的理解。
在线性代数中,我们知道,对于向量 A 和 B 来说,它们的内积形式是这样的
![]()
从上面的公式我们可以看出,向量内积的运算是将两个向量映射为实数。接下来,我们从几何的角度来进行分析,假设 A 和 B 为二维向量来进行分析,则:
![]()
经过变换后我们就可以得到:
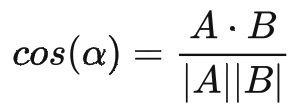
其几何图如下:
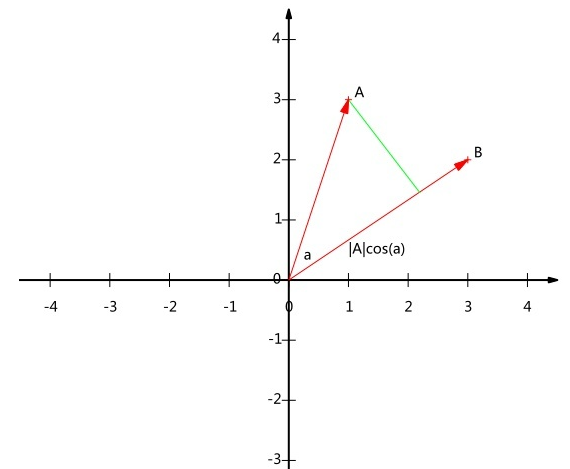
可以看到,向量 A 与 B 的乘积为 A 到 B 投影的长度乘以 B 的模。 假设 |B|=1 ,则公式变为:
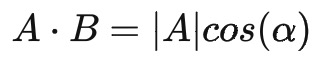
也就是说,向量 A 与 B 的乘积可以看作 A 向 B 所在直线投影的标量大小。如果把 A 和 B 这两个向量扩展至 d 维,可以得到:
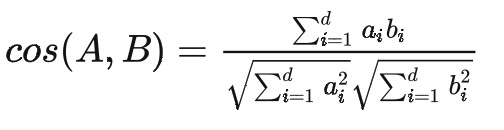
![]()
上述等号只在“标准正交基”下成立。换句话说,向量的“夹角余弦”本身是具有鲜明的几何意义的,但上式右端只是坐标的运算,坐标依赖于所选取的坐标基,基底不同,内积对应的坐标公式就不一样,从而余弦值的坐标公式也不一样。
2.标准正交基
对于两个向量 A 和 B 来说,如果A⋅B=0,那么,我们称这两个向量正交(零向量与任何向量正交)。 我们知道,在n维的欧式空间中,由n个向量组成的正交向量组称为正交基;由单位向量组成的正交基称为标准正交基。
对于一个向量A来说,其中不同维度的值表示的就是在该维上的投影,是一个标量。所以,我们可以大致的得出一个结论:要准确描述向量,首先要确定一组基,然后给出在基所在的各个维度上的投影值,就可以了。为了方便求坐标,我们希望这组基向量模长为 1。因为向量的内积运算,当模长为 1 时,内积可以直接表示投影。然后还需要这组基是线性无关的,我们一般用正交基,非正交的基也是可以的,不过正交基有较好的性质。
Bert模型输出的 [CLS] 向量为什么在文本语义计算任务中无法取得好的效果呢,那么原因可能就是此时的句向量所属的坐标系并非标准正交基。而且如果基的数量少于向量本身的维数,则可以达到降维的效果。但是我们还没回答一个最关键的问题:如何选择基才是最优的。或者说,如果我们有一组 N 维向量,现在要将其降到 K 维(K 小于 N),那么我们应该如何选择 K 个基才能最大程度保留原有的信息?
一种直观的看法是:希望投影后的投影值尽可能分散,因为如果重叠就会有样本消失。当然这个也可以从熵的角度进行理解,熵越大所含信息越多。所以,这里我们希望的是投影后的数值尽可能的分散,那么,该如何让投影值分散呢?而在数学中,可以用方差来表示数值的分散程度。
3.方差与协方差

当协方差为 0 时,表示两个变量完全线性不相关。为了让协方差为 0,我们选择第二个基时只能在与第一个基正交的方向上进行选择,因此最终选择的两个方向一定是正交的。
到这里,我们就可以得到一个优化目标:将一组 N 维向量降为 K 维,其目标是选择 K 个单位正交基,使得原始数据变换到这组基上后,各变量两两间协方差为 0,而变量方差则尽可能大(在正交的约束下,取最大的 K 个方差)。
对于向量 A 和 B 来说,我们按照行组成一个向量矩阵 X 为
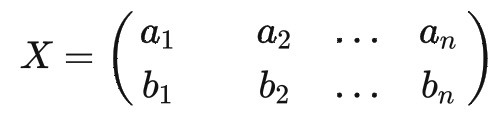
然后根据协方差的计算公式,可得
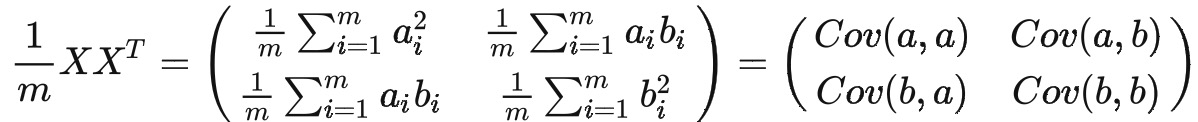
我们可以看到这个矩阵对角线上的分别是两个变量的方差,而其它元素是 a 和 b 的协方差。两者被统一到了一个矩阵里。 我们很容易被推广到一般情况:
设我们有 m 个 n 维数据记录,将其排列成矩阵 ,设
,则 C 是一个对称矩阵,其对角线分别对应各个变量的方差,而第 i 行 j 列和 j 行 i 列元素相同,表示 i 和 j 两个变量的协方差。
由此可知,我们需要将除对角线外的其它元素化为 0,并且在对角线上将元素按大小从上到下排列(变量方差尽可能大),这里就是将协方差转为一个单位矩阵,也就是矩阵的对角化。
设原始数据矩阵 X 对应的协方差矩阵为 C,而 P 是一组基按行组成的矩阵,设 Y=PX,则 Y 为 X 对 P 做基变换后的数据。设 Y 的协方差矩阵为 D,我们推导一下 D 与 C 的关系:
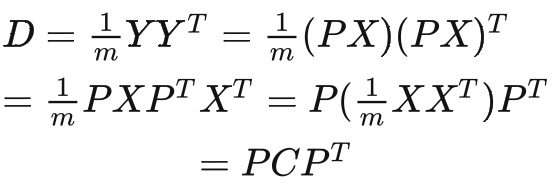
这样我们就看清楚了,我们要找的 P 是能让原始协方差矩阵对角化的 P。换句话说,优化目标变成了寻找一个矩阵 P,满足是一个对角矩阵,并且对角元素按从大到小依次排列,那么 P 的前 K 行就是要寻找的基,用 P 的前 K 行组成的矩阵乘以 X 就使得 X 从 N 维降到了 K 维并满足上述优化条件。
4.whitening
回到Bert本身的输出,根据上述的协方差矩阵,作者假设有一组句子向量,也可以写为行向量 ,然后对其进行如下线性变换。
![]()
使得的均值为0、协方差矩阵为单位阵。为了让均值为0,可以设置
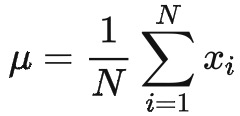
下面求解 W ,将原始数据的协方差记为
![]()
根据公式, ![]() 可以得到
可以得到![]() ,所以,我们的实际目标是
,所以,我们的实际目标是 ![]() ,然后,可得
,然后,可得
![]()
我们知道 Σ 是一个正定对称矩阵,正定对称矩阵都具有如下形式的SVD分解
![]()
其中 U 是一个正交矩阵, Λ 是一个正对角矩阵,则可以让 ![]() ,则可以得到
,则可以得到
![]()
关于PCA和SVD的差异分析,首先是PCA,PCA可以把一个方阵分解为特征值和特征向量。但是对于任意形状的矩阵都可以进行SVD分解。
5.实验对比
首先是与Bert-flow进行对比:

可以看到,简单的BERT-whitening确实能取得跟BERT-flow媲美的结果。除了STS-B之外,笔者的同事在中文业务数据内做了类似的比较,结果都表明BERT-flow带来的提升跟BERT-whitening是相近的,这表明,flow模型的引入可能没那么必要了,因为flow模型的层并非常见的层,它需要专门的实现,并且训练起来也有一定的工作量,而BERT-whitening的实现很简单,就一个线性变换,可以轻松套到任意的句向量模型中。
相信如果是一步步看下来的读者肯定知道了,前面的一系列介绍,其实就是PCA降维的操作。作者表示在降维的时候结果更好。

从上表可以看出,我们将base版本的768维只保留前256维,那么效果还有所提升,并且由于降维了,向量检索速度肯定也能大大加快;类似地,将large版的1024维只保留前384维,那么降维的同时也提升了效果。这个结果表明,无监督训练出来的句向量其实是“通用型”的,对于特定领域内的应用,里边有很多特征是冗余的,剔除这些冗余特征,往往能达到提速又提效的效果。
6.代码实现
import numpy as np
data = np.random.rand(5,768)
print('data.shape = ')
print(data.shape,data)
def compute_kernel_bias(vecs):
"""计算kernel和bias
vecs.shape = [num_samples, embedding_size],
最后的变换:y = (x + bias).dot(kernel)
"""
mu = vecs.mean(axis=0, keepdims=True)
cov = np.cov(vecs.T)
u, s, vh = np.linalg.svd(cov)
W = np.dot(u, np.diag(1 / np.sqrt(s)))
return W, -mu
def transform_and_normalize(vecs, kernel=None, bias=None):
"""应用变换,然后标准化
"""
if not (kernel is None or bias is None):
vecs = (vecs + bias).dot(kernel)
return vecs / (vecs**2).sum(axis=1, keepdims=True)**0.5
kernel,bias = compute_kernel_bias(data)
kernel = kernel[:,:256]
print('kernel.shape = ')
print(kernel.shape)
print('bias.shape = ')
print(bias.shape)
data = transform_and_normalize(data, kernel, bias)
print('data.shape = ')
print(data.shape,data)
Reference
2.Bert-whitening 向量降维及使用_bert得到的句向量经过降维后全部堆在了一起_loong_XL的博客-CSDN博客