从预训练模型中获取Embedding
在NLP领域中,构建大规模的标注数据集非常困难,以至于仅用当前语料无法有效完成特定任务。可以采用迁移学习的方法,即将预训练好的词嵌入作为模型的权重,然后在此基础上的微调。
背景说明
本文基于数据集IMDB进行情感分析,做预测之前需要先对数据集进行预处理,把词转换为词嵌入。这里采用迁移学习的方法来提升模型性能,并使用2014年英文维基百科的预计算词嵌入数据集。**该数据集文件名为glove.6B.zip,大小为822MB,里面包含400000个单词的100维嵌入向量。**把预训练好的词嵌入导入模型的第一层,并冻结该层,然后增加分类层进行分类预测。GloVe词嵌入数据集的下载地址为https://nlp.stanford.edu/projects/glove/

下载IMDB数据集
下载IMDB数据集并保存在本地,这里下载glove.6B.zip完成之后保存到“./aclImdb”。

读取电影评论并根据其评论的正面或负面将其分类为1或0:
def preprocessing(data_dir):
# 提取数据集中所有的评论文本以及对应的标签,neg表示负面标签,用0表示,pos表示正面标签,用1表示
texts, labels = [], []
train_dir = os.path.join(data_dir, 'train')
for label_type in ['neg', 'pos']:
dir_name = os.path.join(train_dir, label_type)
for fname in os.listdir(dir_name):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname), encoding='utf-8')
texts.append(f.read())
f.close()
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
return texts, labels
进行分词
利用TensorFlow 2.0提供的Tokenizer函数进行分词操作,如下所示:
def word_cutting(args, texts, labels):
# 利用Tokenizer函数进行分词操作
tokenizer = Tokenizer(num_words=args.max_words)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print(f'Found {
len(word_index)} unique tokens.')
data = pad_sequences(sequences, maxlen=args.maxlen)
labels = np.asarray(labels)
print(f'Shape of data tensor: {
data.shape}')
print(f'Shape of label tensor: {
labels.shape}')
return word_index, data, labels
将分词后的数据划分为训练集和测试集:
def data_spliting(data, labels, training_samples, validation_samples):
# 将数据划分为训练集和验证集, 首席按打乱数据,因为一开始数据集是排好序的,负面评论在前,正面评论灾后
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
x_train = data[:training_samples]
y_train = labels[:training_samples]
x_val = data[training_samples:training_samples + validation_samples]
y_val = labels[training_samples:training_samples + validation_samples]
return x_train, y_train, x_val, y_val
下载并预处理GloVe词嵌入数据
对glove.6B.100d.txt文件进行解析,构建一个由单词映射为其向量表示的索引,这里根据前面的描述,已经下载好并放到本地目录中。
def glove_embedding(glove_dir):
# 对glove.6B文件进行解析,构建一个由单词映射为其向量表示的索引
embeddings_index = {
}
f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'), encoding='utf-8')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print(f'Found {
len(embeddings_index)} word vectors.')
# 查看字典的样例
for key, value in embeddings_index.items():
print(key, value)
print(value.shape)
break
return embeddings_index
构建模型
采用Keras的序列(Sequential)构建模型
def model_building(max_words, embedding_dim, maxlen):
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
return model
训练模型并可视化结果
训练的时候区分有嵌入和无嵌入两种情况:
def training(args):
texts, labels = preprocessing(args.data_dir)
word_index, data, labels = word_cutting(args, texts, labels)
x_train, y_train, x_val, y_val = data_spliting(data, labels, args.training_samples, args.validation_samples)
embeddings_index = glove_embedding(args.embed_dir)
# 在embeddings_index字典的基础上构建一个矩阵,对单词索引中索引为i的单词来说,该矩阵的元素i就是这个单词对应的词向量
embedding_matrix = np.zeros((args.max_words, args.embedding_dim))
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if i < args.max_words:
if embedding_vector is not None:
# 在嵌入索引(embedding_index)找不到的词,其嵌入向量都设为0
embedding_matrix[i] = embedding_vector
model = model_building(args.max_words, args.embedding_dim, args.maxlen)
# 在模型中加载GloVe词嵌入,并冻结Embedding Layer
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False
# 训练模型
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))
model.save_weights('./pre_trained_glove_model.h5')
visualizating(history)
# 不使用预训练词嵌入的情况
model = model_building(args.max_words, args.embedding_dim, args.maxlen)
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))
visualizating(history)
可视化代码如下:
def visualizating(history):
# 可视化,并查看验证集的准确率acc
acc, val_acc = history.history['acc'], history.history['val_acc']
loss, val_loss = history.history['loss'], history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.figure()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
结果对比
1)在模型中加载GloVe词嵌入的情况,并冻结Embedding Layer:
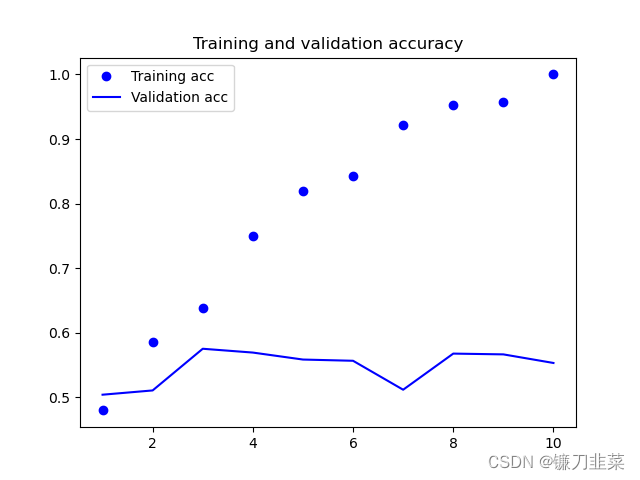
可以看出,训练准确率和验证准确率相差较大,但是这里使用的较少的训练数据。验证准确率接近60%。
2)不使用预训练词嵌入的情况
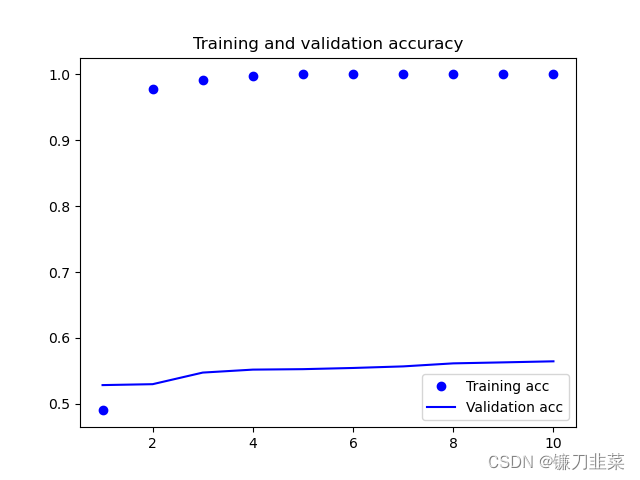
显然,不使用预训练模型的验证准确率只有55%左右。因此可以初步得出结论,使用预训练词嵌入的模型性能优于未使用的模型性能。
其他代码
import argparse
import os
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Flatten, Dense
def main():
parser = argparse.ArgumentParser(description='IMDB Emotional Analysis')
parser.add_argument('--data_dir', type=str, default='./aclImdb', help='the dir path of IMDB dataset')
parser.add_argument('--embed_dir', type=str, default='./glove.6B/', help='the dir path of embeddings')
parser.add_argument('--maxlen', type=int, default=100, help='Keep comments for only the first 100 words')
parser.add_argument('--training_samples', type=int, default=500, help='Train on 200 samples')
parser.add_argument('--validation_samples', type=int, default=10000, help='Verify 10,000 samples')
parser.add_argument('--max_words', type=int, default=10000, help='Consider the most common 10000 words')
parser.add_argument('--embedding_dim', type=int, default=100, help='the dim of word vector')
args = parser.parse_args()
training(args)
if __name__ == '__main__':
main()