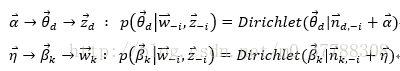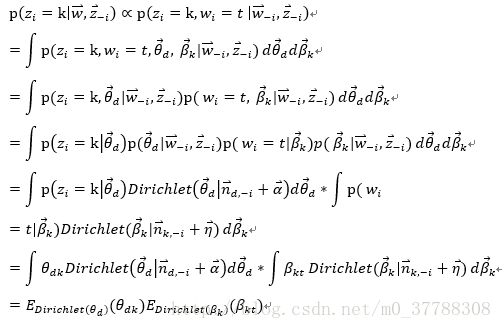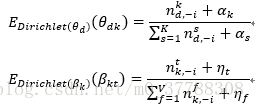一、 MCMC抽样
也许读者会觉得诧异,为什么在一本介绍主题模型的书中却看到了抽样的知识?作者是不是偏题了?
答案当然是没有。
相信你应该听说过有一门课程叫做统计学,在这门课程中,抽样占据着举足轻重的地位。当统计学的研究者们想要了解一个总体的某些参数时,他们的方案是,先去抽样获得样本,通过样本参数去估计总体参数。比如,想知道某财经高校学生们(总体)的平均月消费水平(总体参数),做法是:a.先抽样一部分样本,如从每个学院抽取20个人去调查他们的月消费水平,假设有20个学院,那么就获得了400个人(样本)的月消费水平;b.算出这400个样本的平均月消费水平(样本参数);c.可以认为该财经高校学生们的平均月消费水平估计为这400个样本的平均月消费水平。
本篇的MCMC抽样与LDA主题模型的关系类比统计学里的抽样。在LDA主题模型的参数求解中,我们会使用MCMC抽样去做。
MCMC四个字母的含义
第一个MC ,是Monte Carlo(蒙特卡洛)的首字母缩写。本篇的蒙特卡洛指一种随机模拟方法,以概率和统计理论方法为基础的一种计算方法,是使用随机数(或更常见的伪随机数)来解决很多计算问题的方法。采样过程通常通过计算机来来实现。
蒙特卡洛此名由乌拉姆提出,事实上蒙特卡洛是摩纳哥公国的一座城市,是著名的赌场,世人称之为“赌博之国”。众人皆知,赌博总是和统计密切关联的,所以这个命名风趣而贴切、不仅有意思而且有意义。
第二个MC:Markov Chain(马尔科夫链)。这是MCMC抽样中很重要的一个思想,将会在后篇细讲。
(一)逆变换采样
刚刚有提到,蒙特卡洛指一种随机模拟方法,通常通过计算机来实现。然而,从本质上来说,计算机只能实现对均匀分布的采样。在此基础上对更为复杂的分布进行采样,应该怎么做呢?这就需要用到逆变换采样:
温故两个定义
对于随机变量 X,如下定义的函数 F:
F(x)=PX≤x,−∞<x<∞
称为X 的
累积分布函数。对于连续型随机变量 X 的累积分布函数 F(x),如果存在一个定义在实数轴上的非负函数 f(x),使得对于任意实数 x,有下式成立:
F(x)=∫f(t)dt
则称 f(x) 为 X 的
概率密度函数。显然,当概率密度函数存在的时候,累积分布函数是概率密度函数的积分。概率等于区间乘概率密度。
步骤
欲对密度函数
f(x)
采样,并得到m 个观察值,则重复下面的步骤 m 次:
1、从Uniform(0,1)中随机生成一个值,用 u 表示。
2、计算反函数
F(−1)(u)
的值 x,则x 就是从
f(x)
中得出的一个采样点。
举例:
想对一个复杂概率密度函数
f(x)
抽样,其概率密度形式如下:
F(x)=⎧⎩⎨⎪⎪8x,if0≤x<0.2583−83x,if0.25≤x<1 0,otherwise
1、求
f(x)
的累计分布函数
F(x)
:
F(x)=⎧⎩⎨⎪⎪⎪⎪⎪⎪0,ifx<04x2,if0≤x<0.2583x−43x2−13,if0.25≤x<1 1,ifx>1
2、求
F(x)
的反函数:
F(−1)(u)
F(x)=⎧⎩⎨u√2,if0≤u<0.251−3(1−u)√2,if0.25≤x<1
重复m次逆变换采样以下步骤:从Uniform(0,1)中随机生成一个值,用 u 表示。计算反函数
F(−1)(u)
的值 x,则x 就是从
f(x)
中得出的一个采样点。最终将采样点图像(蓝色)与实际密度函数(红色)比较,得图如下:
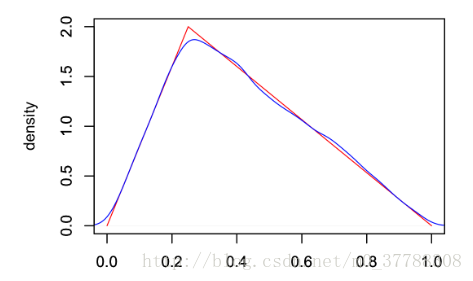 可以看到两条线几乎重合,这表明逆变换采样可以很好的模拟出某些复杂分布。 **存在问题:** 逆变换采样有求解累积分布函数和反函数这两个过程,而有些分布的概率分布函数可能很难通过对概率密度p(x)的积分得到,再或者概率分布函数的反函数也很不容易求。这个时候应该怎么办呢?此时提出了拒绝采样的解决方案。
(二)拒绝采样
欲对逆变换采样不再适用的密度函数
p(x)
采样,如果能找到另外一个概率密度为
q(x)
的函数,它相对容易采样。如采用逆变换采样方法可以很容易对
q(x)
进行采样,甚至
q(x)
就是计算机可以直接模拟的均匀分布。此时我们可直接对
q(x)
采样,然后按照一定的方法拒绝某些样本,达到接近
p(x)
分布的目的。
步骤
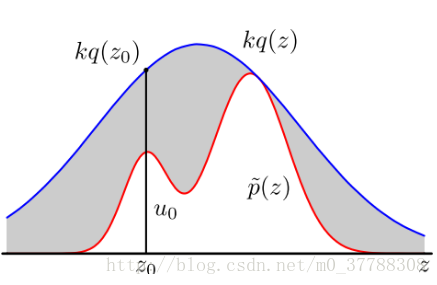 当我们将
q(x)
与一个常数 K 相乘之后,可以实现下图所示之关系,即 K⋅q(x)将p(x)完全“罩住”:p(x) ≤Kq(x)。重复以下步骤抽样: •x 轴方向:从q(x)分布抽样得到
Z0
。 •y 轴方向:从均匀分布
(0,Kq(Z0))
中抽样得到
u0
。 •如果刚好落到灰色区域,否则接受这次抽样:
u0
>
p(Z0)
, 拒绝该样本。 •重复以上过程。
举例:利用拒绝采样计算
π
值
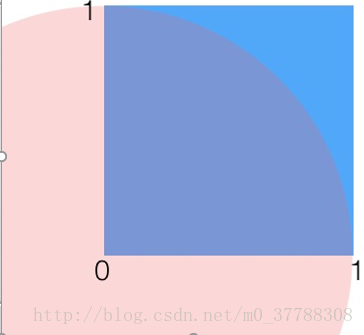 如图所示,阴影区域有一个边长为1的正方形,正方形里有一个半径为1的1/4圆。则有:S(1/4圆)= 1/4*π*R^2= 1/4π;S(正方形)=1。现在对这个正方形随机取点,某点到原点的距离小于1,则说明它在1/4圆内。可以认为,落在圆内的次数/取点总次数=1/4圆的面积/正方形的面积。即:
π=4∗s(正方形)∗落在圆内的次数取点总次数
随着采样点的增多,最后的结果π会越精准。 这里也就是用到了拒绝采样的思想。要计算
π
值,即寻求对圆这个复杂分布抽样,圆不好搞定,于是我们选择了一个相对容易的正方形分布,在对正方形随机取点的时候,如果某点到原点的距离小于1,则说明它在1/4圆内,接受这个样本,否则拒绝它。 而抽样的时候; 基于以上思想我们可以利用计算机建模。
(三)马尔科夫链
马尔科夫链就是第二个MC:Markov Chain。定义为:根据概率分布,可以从一个状态转移到另一个状态,但是状态转移之间服从马氏性的一种分布。
解释一下定义中提到的两个名词:
马氏性:状态转移的概率只依赖与他的前一状态。数学表达为:
P(Xn+1=k|Xn=kn,Xn−1=kn−1,…,X1=k1)=P(Xn+1=k|Xn=kn)
状态转移:状态的改变叫做转移(状态可以向自身转移),与不同的状态改变相关的概率叫做转移概率。
q(i,j)=q(j|i)=q(i→j):
表示状态 i转移到状态j的概率。
如在天气事件中,由前天的下雨转移到昨天的多云,昨天的多云转变到今天的艳阳天。这里所说的下雨、多云、艳阳天都是一种状态。从下雨转移到多云,称之为状态转移。而今天的艳阳天只与昨天的多云有关,与前天的天气没有半点关系,这就是所谓马氏性。
案例
社会学家经常把人按其经济状况分成三类:下、中、上层;我们用1,2,3分别代表这三个阶层(对应于马氏链中环境下的三个状态)。如果一个人的收入属于下层类别,则他的孩属于下层收入的概率是0.665,属于中层的概率是0.28,属于上层的概率是0.07。这里汇总了阶层收入变化的转移概率如下图所示:
 状态转移的概率只依赖与他的前一状态,也就是考察父代为第i层则子代为第j层的概率。 由此得出转移概率矩阵:
⎡⎣⎢0.650.150.120.280.670.360.070.180.52⎤⎦⎥
给定当前这一代人处于下、中、上层的概率分布向量是:
π0=(π0(1),π0(2),π0(3))
,那么他们的子女的分布比例将是
π1=π0P
,孙子代的分布比例将是
π2=π1P=π0P2
,以此类推,第n代的分布比例将是
πn=π0Pn
. 显然,第n+1代中处于第j个阶层的概率为:
π(Xn+1=j)=∑i=0nπ(Xn=i).P(Xn+1=j|Xn=i)
给定初始概率
π0=(0.21,0.68,0.11)
,即第0代的时候各阶层占比是(0.21,0.68,0.11)。显然由此公式我们可以分别计算第一代的第1、2、3阶层的占比,第二代的第1、2、3阶层的占比,….。
如:计算第一代的第1阶层的占比为:
0.21∗.65+0.68∗0.15+0.11∗0.12=0.2517≈0.252
以此类推,各代各阶层的占比如下:
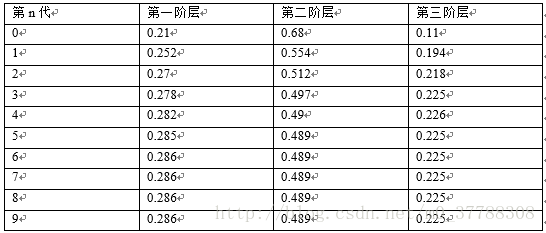 可以看到,从第5代开始,各阶层的分布就稳定不变了。这个是偶然的吗?如若不是,那是初始概率决定的还是转移概率矩阵决定的呢?接下来验证一下。 换一个初始概率
π0=(0.75,0.15,0.1)
,迭代结果如下:
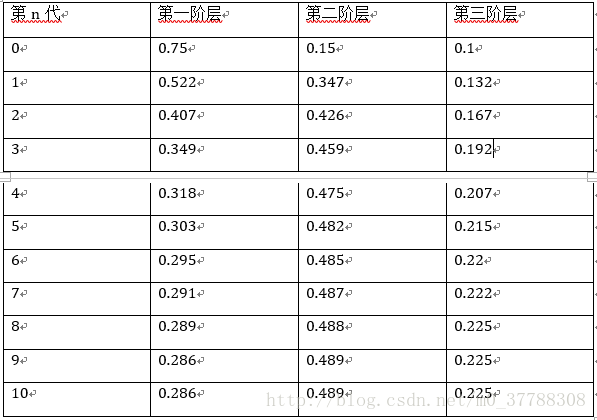 我们发现,到第9代的时候,分布又收敛了,而且收敛的分布都是
π=(0.286,0.489,0.225)
,也就是说收敛的分布与初始概率无关。 这里还有一个神奇的地方:我们计算一下转移矩阵P的n次幂,发现:
P20=P21=⋯=P100=Pn=⎡⎣⎢0.2860.2860.2860.4890.4890.4890.2250.2250.225⎤⎦⎥
也就是说,当n足够大的时候,
Pn
矩阵每一行都收敛到
π=(0.286,0.489,0.225)
这个概率分布。于是关于马氏链我们有定理如下:
定理一:(马氏链的平稳分布)
如果一个非周期马氏链具有概率转移矩阵 P,且它的任何两个状态都是连通的,则
limn→∞Pnij
存在且与 i 无关(也即矩阵 P^n 的每一行元素都相同),记
limn→∞Pnij=π(j)
,我们有:
(1)
limn→∞Pn=⎡⎣⎢π(1)...π(1).........π(n)...π(n)⎤⎦⎥
(2)
π(j)=∑∞0π(i)Pij也即π=πP。
(3)π 是方程 π=πP 的唯一非负解。
其中,
π=[π(1),π(2),⋯,π(j),⋯],∑∞0π(i)=1
(符合概率上对分布的要求),π 称为马氏链的平稳分布。
定理二(细致平稳条件)
如果非周期马氏链的转移矩阵
P和分布π(x)满足:π(i)Pij=π(j)Pji,则π(x)是马氏链的平稳分布,上式被称为细致平稳条件。
以上两个定理极其重要,是MCMC理论不可缺少的理论基础。
(四)从马尔科夫链到抽样
对于给定的概率分布
π(x)
,我们希望有快捷的方式生成它对应的样本。由于马氏链能收敛到平稳分布,于是一个很漂亮的想法是:如果我们能够构造一个转移矩阵为 P的马氏链,使得该马氏链的平稳分布恰好是
π(x)
,那么我们从任何一个初始状态出发沿着马氏链转移,得到一个转移序列
x1,x2,…,xn,x(n+1),…,
如果马氏链在第 n 步已经收敛了,于是
x1,x2,…,xn,x(n+1),…
自然是分布
π(x)
的样本。
马氏链的收敛性质主要有转移矩阵 P决定,所以基于马氏链做采样(比如MCMC)
的关键问题是如何构造转移矩阵,使得其对应的平稳分布恰是我们需要的分布
π(x)
。
MCMC采样
根据细致平稳理论,只要我们找到了可以使概率分布
π(x)
满足细致平稳分布的矩阵P即可。这给了我们寻找从平稳分布π, 找到对应的马尔科夫链状态转移矩P的新思路。
假设我们已经有一个转移矩阵为Q的马氏链。
q(i,j)
表示状态 i转移到状态j的概率.通常情况下,细致平稳条件不成立,即:
p(i)q(i,j)≠p(j)q(j,i)
对上式改造使细致平稳条件成立:引入一个α(i,j)和α(j,i) ,并让等式两端取等:
p(i)q(i,j)α(i,j)=p(j)q(j,i)α(j,i)
问题是什么样的α(i,j)和α(j,i)可以使等式成立呢?按照对称性,可以取:
α(i,j)=p(j)q(j,i)
α(j,i)=p(i)q(i,j)
所以我们改造后的马氏链
Q′
如下。并且
Q′
恰好满足细致平稳条件,所以马氏链
Q′
的平稳分布就是
P(x)
。
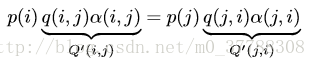 **步骤** (1)初始化马氏链初始状态
X0=x0
(2)对
t=0,1,2,3,…
循环一下过程进行采样: 第
t
时刻马氏链状态为
Xt=xt
,采样
y∼q(x|x(t))
; 从均匀分布采样
u∼Uniform[0,1];
如果
u<α(xt,y)=p(y)q(xt│y),
则接受
xt→y,
即
xt+1)→y
;否则不接受概率转移,即
Xt+1=xt。
(五)Metropolis-Hastings采样
以上过程不论是离散或是连续分布,都适用。
以上的MCMC采样算法已经能正常采样了,但是马氏链Q在转移的过程中的接受率α(i,j)可能偏小,这样我们会拒绝大量的跳转,这使得收敛到平稳分布的速度太慢。有没有办法提升接受率呢?
我们回到MCMC采样的细致平稳条件:
p(i)q(i,j)α(i,j)=p(j)q(j,i)α(j,i)
我们采样效率低的原因是
α(i,j)α(i,j)
太小了,比如为
α(j,i)为0.1,而α(j,i)
为0.2。即:
p(i)q(i,j)∗0.1=p(j)q(j,i)∗0.2
这时我们可以看到,如果两边同时扩大五倍,接受率提高到了0.5,但是细致平稳条件却仍然是满足的,即:
p(i)q(i,j)∗0.5=p(j)q(j,i)∗0.2
这样我们的接受率可以做如下改进,即:
α(i,j)=min{p(j)q(j│i)p(i)p(i│j),1}
此时便得到了常见的
Metropolis−Hastings
采样算法。
步骤
(1)初始化马氏链初始状态
X0=x0
(2)对
t=0,1,2,3,…
循环一下过程进行采样:
第t时刻马氏链状态为
Xt=xt
,采样
y∼q(x|x(t))
;
从均匀分布采样
u∼Uniform[0,1];
如果
u<α(xt,y)=min{p(j)q(j│i)p(i)p(i│j),1}
,则接受
xt→y
,即
xt+1→y
;否则不接受概率转移,即
Xt+1=xt。
以上M-H算法只针对低维的情况,对于高维情况,我们采用Gibbs采样。
(六)Gibbs采样
对于高维情况,我们采用Gibbs采样。
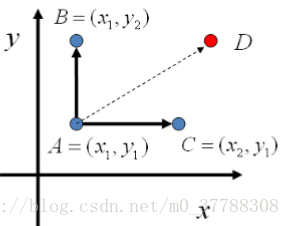
以二维为例,假设
p(x,y)
是一个二维联合数据分布,考察x坐标相同的两个点
A(x1,y1)和B(x1,y2)
,容易发现下面两式成立:
p(x1,y1)p(y2│x1)=p(x1)p(y1│x1)p(y2|x1)
p(x1,y2)p(y1│x1)=p(x1)p(y2│x1)p(y1|x1)
所以得到:
p(x1,y1)p(y2│x1)=p(x1,y2)p(y1│x1)
即:
p(A)p(y2│x1)=p(B)p(y1│x1)
观察上式再观察细致平稳条件的公式,我们发现在
x=x1
这条直线上,如果用条件概率分布
p(y|x1)
作为马尔科夫链的状态转移概率,则任意两个点之间的转移满足细致平稳条件!
同样
,y=y1
这条直线上,取两点
A(x1,y1),C(x2,y1)
也有如下等式:
基于上面的发现,我们可以构造平面上两点之间的转移概率矩阵Q:
Q(A→B)=p(yB│x1)ifxA=xB=x1
Q(A→C)=p(xc│x1)ifyA=yc=y1
Q(A→D)=0otherwise
有了上面这个状态转移矩阵,我们很容易验证平面上的两点X,Y,满足细致平稳条件。
p(X)Q(X→Y)=p(Y)Q(Y→X)
于是这个二维空间上的马氏链收敛到平稳分布
p(x,y).
于是可以得到二维Gibbs采样的步骤:
随机初始化
X0=x0,Y0=y0
对
t=0,1,2,‘‘‘‘
循环采样:
y(t+1)∼p(y|xt);
x(t+1)∼p(x|y(t+1));
以上采样,马氏链的转移只是轮换的沿着坐标轴x轴和y轴做转移,于是得到样本
(x0,y0),(x0,y1),(x1,y1),(x1,y2),(x2,y2),…,
马氏链收敛以后得到的样本就是P(x,y)的样本了。但其实坐标轴轮换不是强制要求的最一般的情形可以是,在t时刻,可以在x轴和y轴之间随机的选一个坐标轴,然后按条件概率转移,马氏链一样可以收敛。轮换两个坐标轴只是一种简便形式。
以上二维推广到高维的情形,即
x1变到多维x1
,推导过程不变,细致平稳条件依然成立:
p(x1,y1)p(y2│x1)=p(x1,y2)p(y1│x1)
此时转移矩阵Q由条件分布
p(y│x1)
定义。
Gibbs采样步骤
(1)随机初始化{x_i:i=1,…,n}
(2)对t=0,1,2,….循环采样:
x1(t+1)∼p(x1|xt)2,x(t)3,…,x(t)n)
x(t+1)2∼p(x2|x(t+1)1,x(t)3,…,x(t)n)
⋅⋅⋅
x(t+1)j∼p(xj|x(t+1)2,...,x(t+1)j−1,x(t)j,…,x(t)n)
⋅⋅⋅
x(t+1)n∼p(xn|x(t+1)1,x(t+1)2,…,x(t+1)n−1)
二、主题模型与MCMC采样
回顾一下主题模型步骤:
0、 首先随机地给每个词分配一个主题,之后按以下1、2步骤更新主题;
求某一个词
wi
对应主题特征z_i的条件概率分布
p(zi=k|w⃗ ,z⃗ −i)
。其中,
z⃗ −i
代表去掉下标为i的词后的主题分布。
条件概率分布
p(zi=k|w⃗ ,z⃗ −i)
,我们就可以进行Gibbs采样,最终在Gibbs采样收敛后得到第i个词的主题。
采样得到了所有词的主题,那么通过统计所有词的主题计数,就可以得到各个主题的词分布。
接着统计各个文档对应词的主题计数,就可以得到各个文档的主题分布。
在上一节介绍LDA主题模型的时候得到了生成整个语料库的联合分布概率。我们知道,在概率论中,如果得到了联合分布,则能很轻易地得到条件分布、边缘分布。那么今天我们就由联合分布
去求条件分布
p(zi=k|w⃗ ,z⃗ −i)
求解条件分布
p(zi=k|w⃗ ,z⃗ −i)
对于下标i,由于它对应的词wi是可以观察到的,所以,
p(zi=k|w⃗ ,z⃗ −i)∝p(zi=k,wi=t|w⃗ −i,z⃗ −i)
,对于
zi=k,wi=t,
它只涉及到第d篇文档和第k个主题两个Dirichlet-multi共轭,即:
于是有:
再由Dirichlet期望公式可得:
有了这个公式,我们就可以用Gibbs采样去采样所有词的主题,当Gibbs采样收敛后,即得到所有词的采样主题。采样得到了所有词的主题,那么通过统计所有词的主题计数,就可以得到各个主题的词分布。接着统计各个文档对应词的主题计数,就可以得到各个文档的主题分布。
应用于LDA的Gibbs采样算法流程:
1)选择合适的主题数K, 选择合适的超参数向量α,η
2) 对应语料库中每一篇文档的每一个词,随机的赋予一个主题编号z
3) 重新扫描语料库,对于每一个词,利用Gibbs采样公式更新它的topic编号,并更新语料库中该词的编号。
4) 重复第2步的基于坐标轴轮换的Gibbs采样,直到Gibbs采样收敛。
5) 统计语料库中的各个文档各个词的主题,得到文档主题分布θ_d,统计语料库中各个主题词的分布,得到LDA的主题与词的分布β_k。
参考文献:
博客:http://blog.csdn.net/u010159842/article/details/48637095
https://www.cnblogs.com/pinard/p/6867828.html
http://blog.csdn.net/baimafujinji/article/details/51407703
《LDA数学八卦》