自己使用的环境版本:
Windows10+
Ubuntu18.04 LTS +
VMware14 Pro+
Hadoop2.6.5+
Spark-2.3.0+
JAVA1.8+
scala2.11+
MobaXterm(远程连接工具)
包含,Ubuntu服务器创建、远程工具连接配置、Ubuntu服务器配置、Java环境配置、scala环境配置
Hadoop文件配置、Hadoop格式化、启动。
Spark安装文件配置,启动等。
①第一步:先安装好了vmware14pro之后安装Ubuntu18.04 LTS,将第一个命名为hadoop1之后的hadoop2,和hadoop3都是采取虚拟机克隆的形式进行创建(选中已经创建的虚拟机右键-》管理中-》克隆),需要注意的是克隆是创建完整克隆
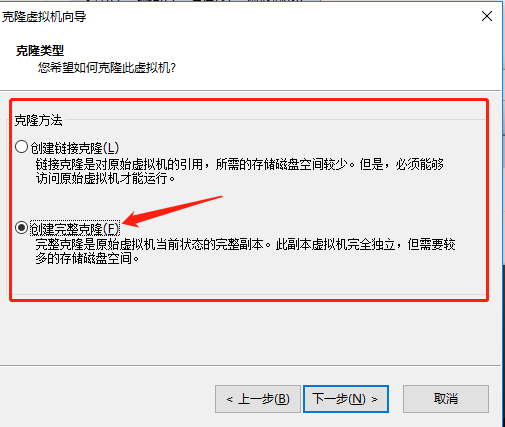
建立好的虚拟机如下
通过ifconfig命令查看服务器ip地址
IP 192.168.5.130 默认主机名ubuntu
IP 192.168.5.132 默认主机名ubuntu
IP 192.168.5.133 默认主机名ubuntu
下一步会修改主机名hostname如何查看每一个系统的ip地址具体请点击看:Ubuntu18.04查看本机IP (查看)
②Ubuntu服务器版在VMware中操作不方便需要自己下载安装一个MobaXterm自己搜索下载
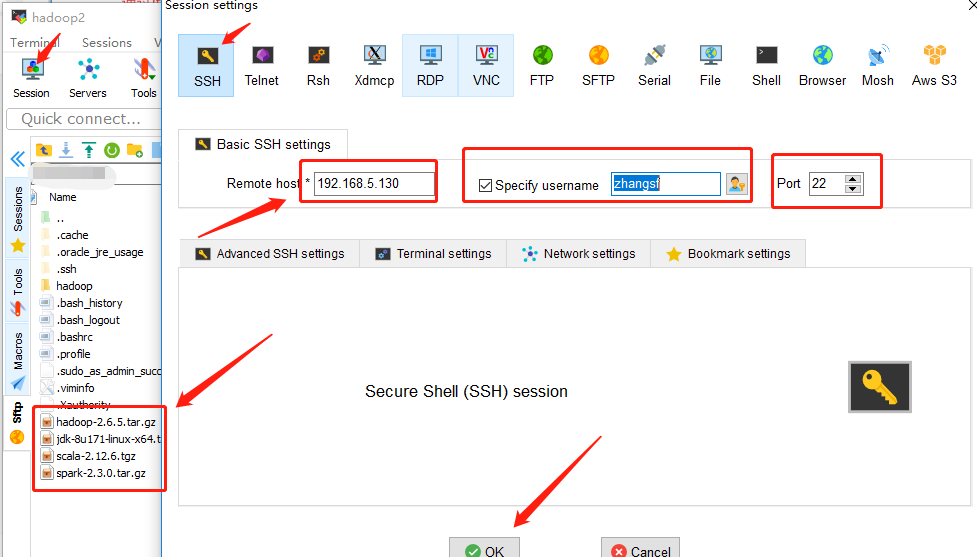
在点击ok连接上之后后续就可以直接在MobaXterm上操作
同样三个虚拟机建立连接
③更换为清华源,具体方法:Ubuntu 18.04换 清华源
④安装vim编辑器,默认自带vi编辑器
sudo apt install vim⑤修改Ubuntu服务器hostname主机名,主机名和ip是一一对应的。
#在192.168.5.130
zhangsf@ubuntu:~$ sudo vim /etc/hostname进入编辑模式 写入 hadoop1 然后重启就会发现成为:同样对第二个和第二个做同样的操作,不过一个对应为192.168.5.132 hadoop2,一个对应192.168.5.133 hadoop3
⑥增加hosts文件中ip和主机名对应字段
在Hadoop1,2,3中
zhangsf@hadoop1:~$ sudo vim /etc/hosts192.168.5.130 hadoop1
192.168.5.132 hadoop2
192.168.5.133 hadoop3⑦更改系统时区(将时间同步更改为北京时间)
zhangsf@hadoop1:~$ date
Wed Oct 26 02:42:08 PDT 2016zhangsf@hadoop1:~$ sudo tzselect根据提示选择选择不同的数字AsiaChinaBeijing Timeyes最后将Asia/Shanghai shell scripts 复制到/etc/localtime
zhangsf@hadoop1:~$ sudo cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtimezhangsf@hadoop1:~$ date
Mon Jun 11 16:36:53 CST 2018
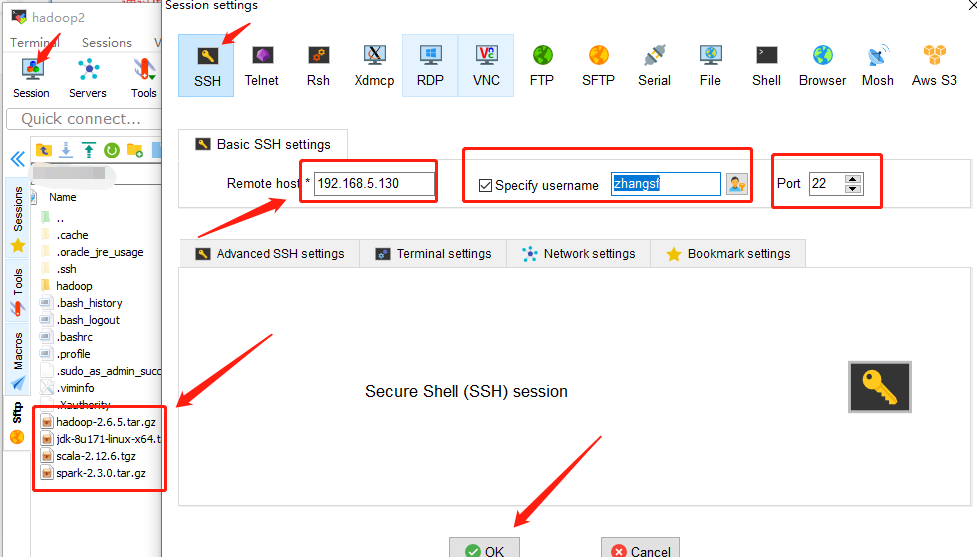
将所需安装的安装文件拖拽至MobaXterm中对应的系统下面的文件下就可以如图左下侧
⑧解压缩并将jdk放置/opt路径下
zhangsf@hadoop1:~$ tar -zxf jdk-8u111-linux-x64.tar.gz
zhangsf@hadoop1:~$ sudo mv jdk1.8.0_111 /opt/
[sudo] password for hadoop1:
zhangsf@hadoop1:~$⑨配置环境变量
编写环境变量脚本并使其生效
zhangsf@hadoop1:~$ sudo vim /etc/profile.d/jdk1.8.sh输入内容:export JAVA_HOME=/opt/jdk1.8.0_111
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH⑩验证jdk成功安装
zhangsf@hadoop1:~$ java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)对其他机器同样操作
也可通过scp命令
#注意后面带 : 默认是/home/zhangsf路径下
zhangsf@hadoop1:~$ scp jdk-8u111-linux-x64.tar.gz hadoop2:集群无秘钥登录在hadoop1,hadoop2,hadoop3中执行
sudo apt install sshsudo apt install rsynczhangsf@hadoop1:~$ ssh-keygen -t rsa //一路回车就好
在 Hadoop1(master角色) 执行,将~/.ssh/下的id_rsa.pub公私作为认证发放到hadoop1,hadoop2,hadoop3的~/.ssh/下
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop1
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop2
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop32然后在 Hadoop1 上登录其他Linux服务器不需要输入密码即成功。
#不需要输入密码
ssh hadoop2
hadoop完全分布式集群文件配置和启动
在hadoop1上配置完成后将Hadoop包直接远程复制scp到其他Linux主机即可。
Linux主机Hadoop集群完全分布式分配
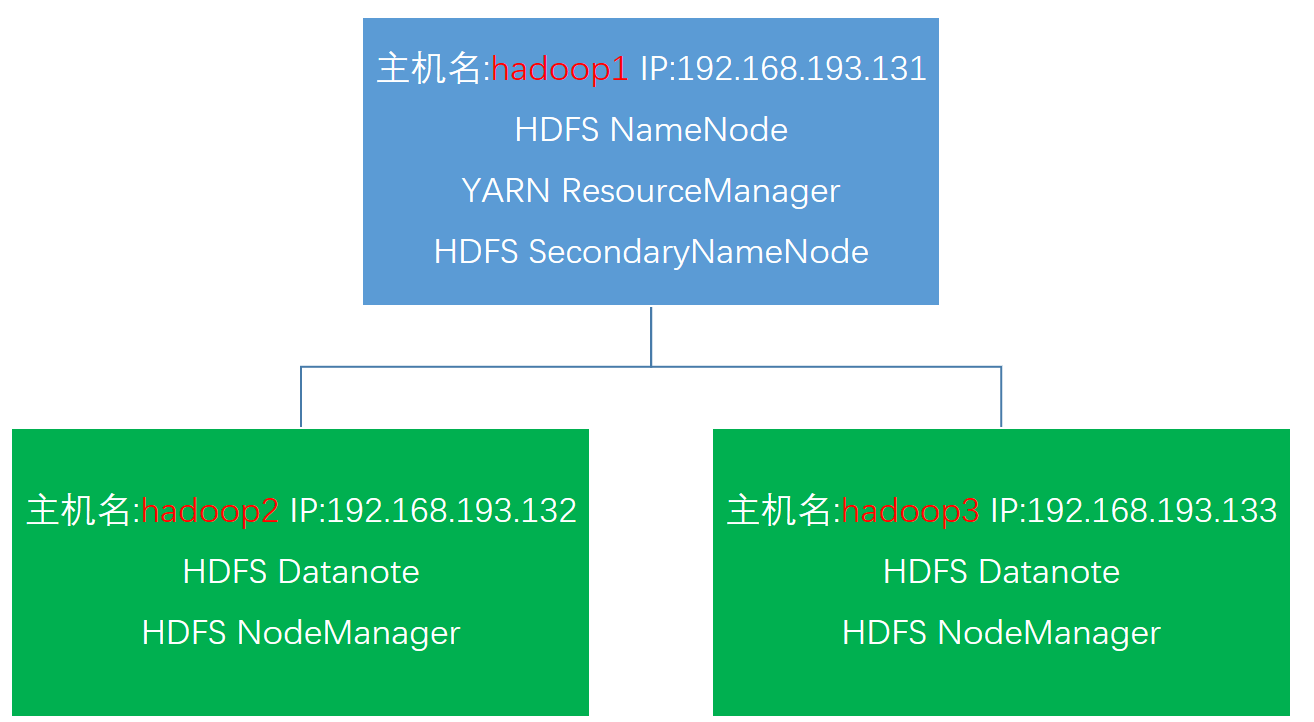
Hadoop主要文件配置
在Hadoop1,2,3中配置Hadoop环境变量
zhangsf@hadoop1:~$ sudo vim /etc/profile.d/hadoop2.6.5.shexport HADOOP_HOME="/opt/hadoop-2.7.3"
export PATH="$HADOOP_HOME/bin:$PATH"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop配置 hadoop-env.sh 增加如下内容
export JAVA_HOME=/opt/jdk1.8.0_111配置slaves文件,增加slave主机名
hadoop2
hadoop3配置 core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<!-- Size of read/write buffer used in SequenceFiles. -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 指定hadoop临时目录,自行创建 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/zhangsf/hadoop/tmp</value>
</property>
</configuration>配置 hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop1:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/zhangsf/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/zhangsf/hadoop/hdfs/data</value>
</property>
</configuration>配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- Configurations for ResourceManager -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1:8088</value>
</property>
</configuration>配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>复制Hadoop配置好的包到其他Linux主机
zhangsf@hadoop1:~$ scp -r hadoop-2.6.5 hadoop2:格式化节点
zhangsf@hadoop1:/opt/hadoop-2.6.5$ hdfs namenode -formathadoop集群全部启动
在Hadoop1上执行
zhangsf@hadoop1:/opt/hadoop-2.6.5/sbin$ ./start-all.sh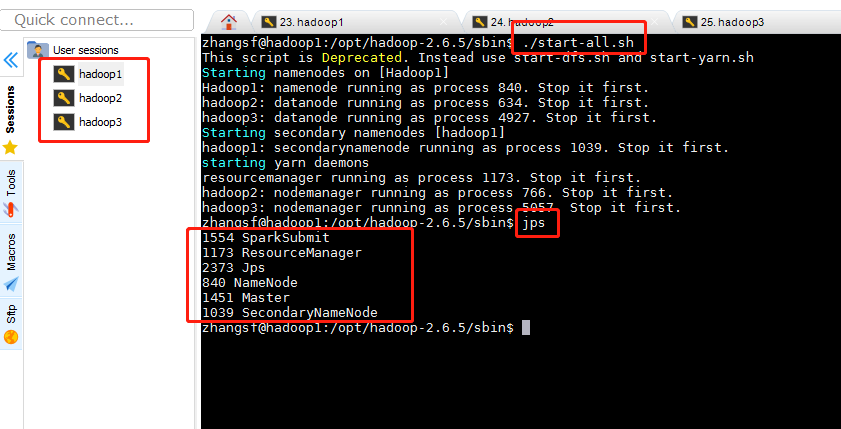
其他主机上
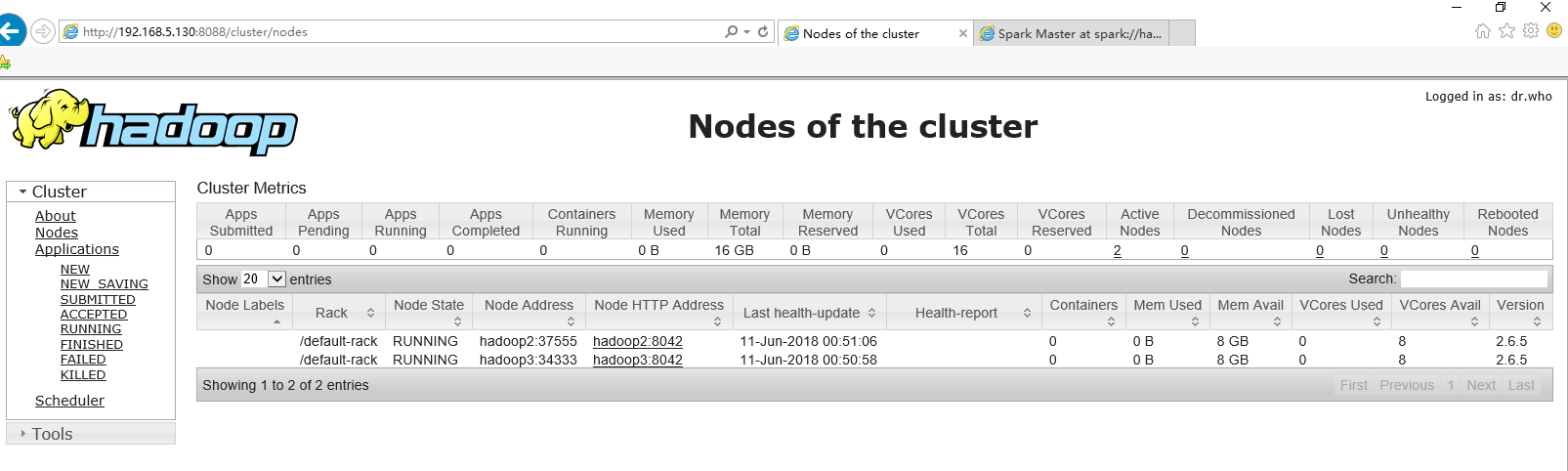
在主机上查看,直接在浏览器中输入hadoop1 集群地址
- 安装scala
下载并安装scala
为了方便,在hadoop1主机上先安装,把目录打开到/opt目录下,与我的Java目录相一致。
wget https://downloads.lightbend.com/scala/2.11.7/scala-2.11.7.tgz下载之后解压
tar -zxvf scala-2.11.7.tgzrm -rf scala-2.11.7.tgz在此需要打开/etc/profile文件进行配置
在文件的最后插入
export SCALA_HOME=/usr/scala-2.11.7
export PATH=$PATH:$SCALA_HOME/bin插入了之后要使得命令生效,需要的是:
source /etc/profile检测安装是否成功scala -version
同样通过scp将文件拷贝到其他主机上
Spark安装之前的准备
文件的解压与改名
tar -zxvf spark-2.3.0-bin-hadoop2.6.tgzrm -rf spark-2.3.0-bin-hadoop2.6.tgz为了我后面方便配置spark,在这里我把文件夹的名字给改了
mv spark-2.3.0-bin-hadoop2.7 spark-2.3.0配置环境变量
vi /etc/profile.d/spark-2.3.0.sh写入
export SPARK_HOME=/opt/spark-2.3.0
export PATH=$PATH:$SPARK_HOME/bin配置Spark环境
打开spark-2.3.0文件夹
cd spark-2.3.0此处需要配置的文件为两个 spark-env.sh和slaves
修改spark-env.sh文件
vi conf/spark-env.sh在最尾巴加入
export JAVA_HOME=/usr/java/jdk1.8.0_141
export SCALA_HOME=/usr/scala-2.11.7
export HADOOP_HOME=/opt/hadoop-2.6.5
export HADOOP_CONF_DIR=/opt/hadoop-2.6.5/etc/hadoop
export SPARK_MASTER_IP=hadoop1
export SPARK_WORKER_MEMORY=2g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1或者直接
export SCALA_HOME=${SCALA_HOME}
export JAVA_HOME=${JAVA_HOME}
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=500m
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
变量说明
- JAVA_HOME:Java安装目录- SCALA_HOME:Scala安装目录
- HADOOP_HOME:hadoop安装目录
- HADOOP_CONF_DIR:hadoop集群的配置文件的目录
- SPARK_MASTER_IP:spark集群的Master节点的ip地址
- SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
- SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
- SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
修改slaves文件
vi conf/slaves在最后面修成为
hadoop2
hadoop3同步hadoop2和hadoop3的配置
启动Spark集群
因为我们只需要使用
hadoop的HDFS文件系统,所以我们并不用把hadoop全部功能都启动。只需要启动hadoop的hdfs
启动Spark
因为
hadoop/sbin以及spark/sbin均配置到了系统的环境中,它们同一个文件夹下存在同样的start-all.sh文件。最好是打开spark-2.3.0,在文件夹下面打开该文件。
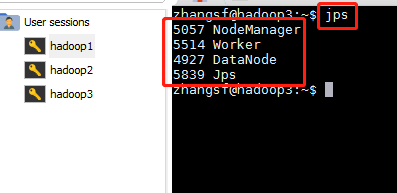
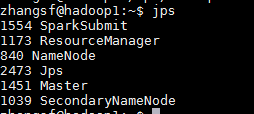
./sbin/start-all.sh查看hadoop的jps,和hadoop2的jps、hadoop3的jps

成功打开Spark集群之后可以进入Spark的WebUI界面,可以通过
hadoop1:8080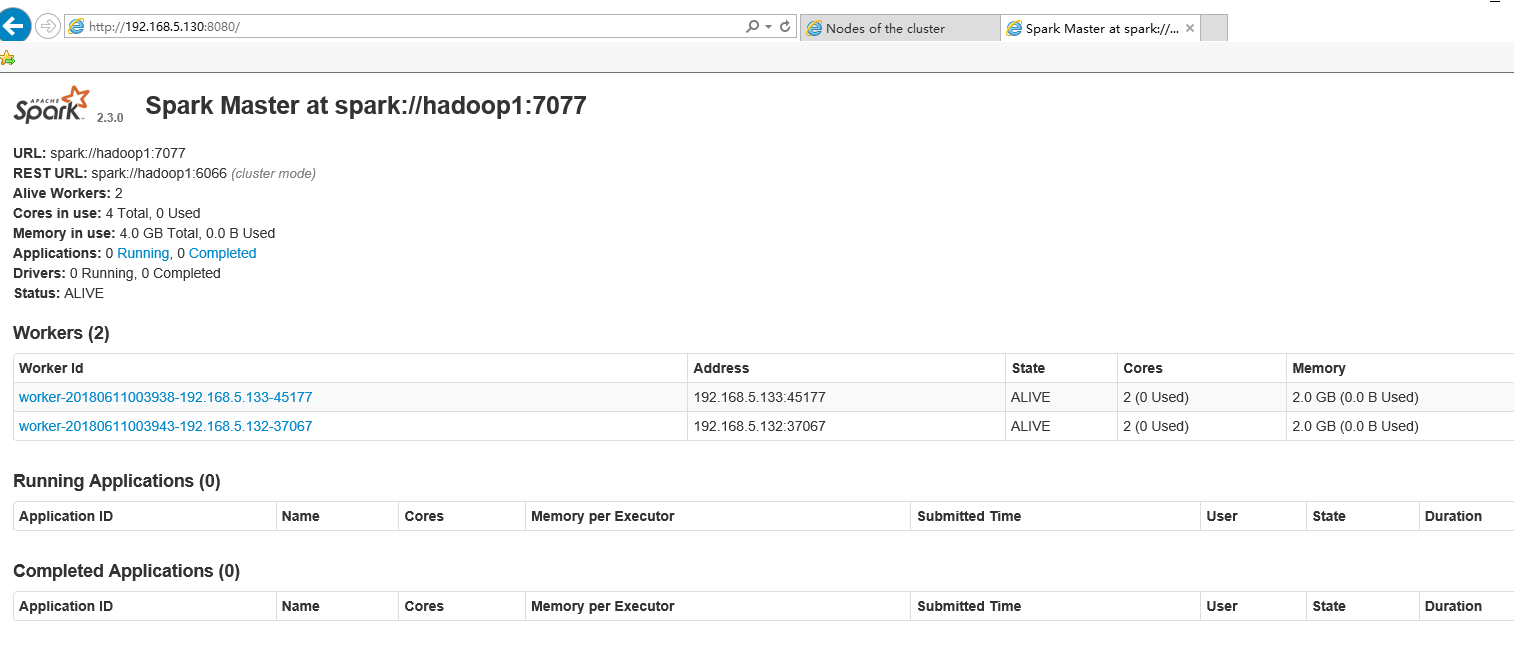
打开Spark-shell
使用
spark-shell同时,因为shell在运行,我们也可以通过
hadoop1:4040访问WebUI查看当前执行的任务