转自:https://blog.csdn.net/gamer_gyt/article/details/51991893
写在前边的话:
最近找了一个云计算开发的工作,本以为来了会直接做一些敲代码,处理数据的活,没想到师父给了我一个课题“基于质量数据的大数据分析”,那么问题来了首先要做的就是搭建这样一个平台,毫无疑问,底层采用hadoop集群,在此之上,进行一些其他组件的安装和二次开发
hadoop伪分布部署参考:点击打开链接
hadoop单机版部署参考:点击打开链接
zookeeper,hive,hbase的分布式部署参考:点击链接
Spark,Sqoop,Mahout的分布式部署参考:点击链接
hadoop高可用部署:点击连接
一:安装VM 12.x
下载地址:链接:http://pan.baidu.com/s/1c2KA3gW密码:3r67
二:安装CentOS6.5
这里采用3台机器,其对应的IP和主机分别如下(他们的用户名都是master)
| 主机名 | ip | 对应的角色 |
| master1 | 192.168.48.130 | NameNode |
| slave1 | 192.168.48.131 | Datanode1 |
| slave2 | 192.168.48.132 | Datanode2 |
这里我们可以采用安装一台虚拟机,然后进行克隆的方法,克隆出五台机器,然后修改对应的ip地址和用户名,VM安装虚拟机有三种网络连接方式,分别是桥接,NAT,仅主机模式,这里采用默认设置,即使用NAT,NAT模式下实用的是Vmnet8
修改IP地址:
1:查看本机ip
我的电脑ip地址为:192.168.69.30
Vmnet8的ipv4地址为:192.168.48.1
2:确定虚拟机IP地址范围和网关地址,下图红线标示
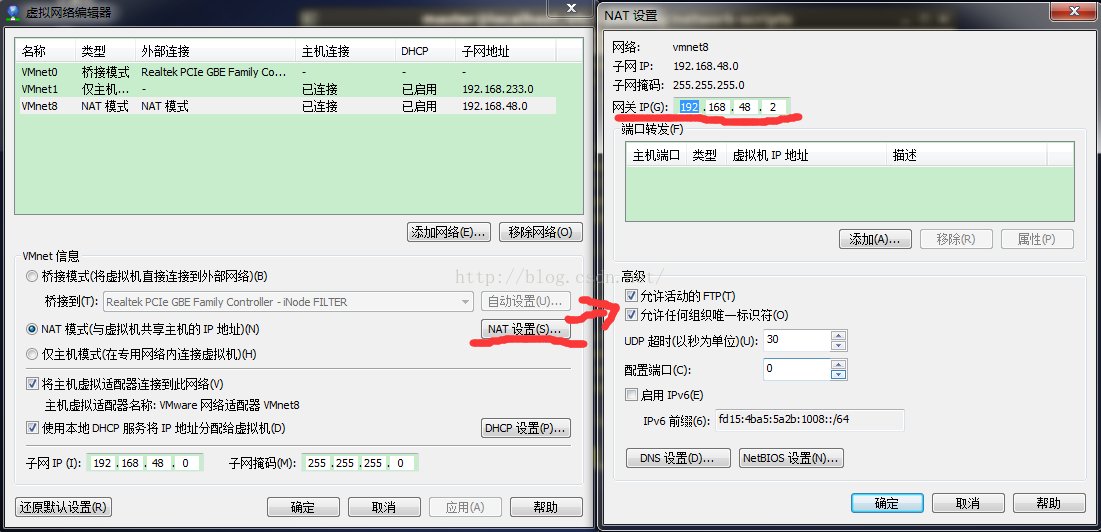
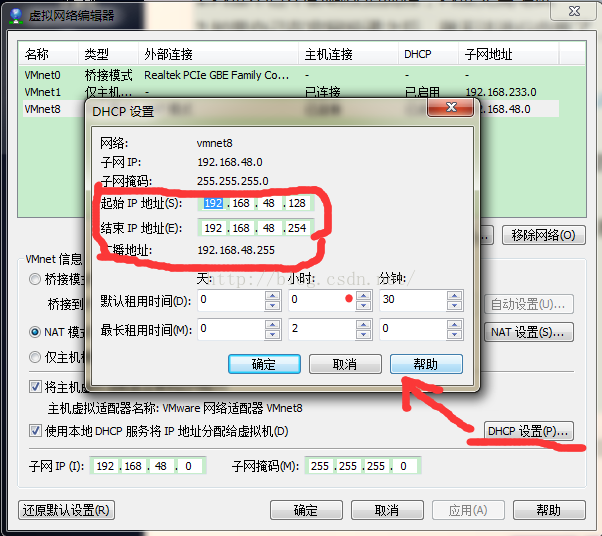
3:打开虚拟机终端
输入:sudo vim /etc/sysconfig/network-scripts/ifcfg-eth0
修改后的信息如下,需要修改的地方有红线标示出来了:
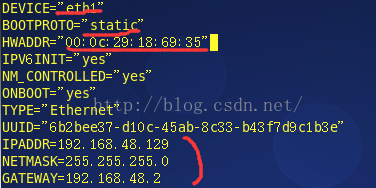
eth0--->eth1
dhcp--->static
HWADDR MAC地址修改为本虚拟机的mac地址,mac地址查看 ip addr,选择eth1那个
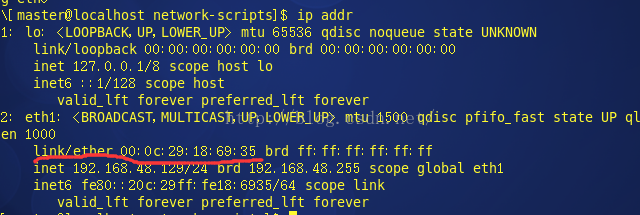
之后便可以使用ifconfig查看ip了
修改主机名和对应IP:
1:编辑hosts文件
sudo vim /etc/hosts
清空内容,添加 192.168.48.129 master (这里不要清空hosts文件,具体看评论)
2:便捷network文件
sudo vim /etc/sysconfig/network
修改HOSTNAME为master
重启生效
三:安装hadoop集群
0:每台机器上关闭防火墙和selinux
永久关闭防火墙:chkconfig --level 35 iptables off
永久关闭selinux:
vim /etc/selinux/config
找到SELINUX 行修改成为:SELINUX=disabled:
1:每台机器上安装java环境( jdk-7u51-linux-x64.tar)
解压到指定目录,这里我选择的是/opt
tar -zxvf jdk-7u51-linux-x64.tar /opt
修改文件夹名字为java
mv /opt/jdk1.7.0_51 /opt/java
配置环境变量,打开/etc/profile文件,加入java的路径
vim /etc/profile (如果没有权限可以前边加入sudo)
文件前边写上:
export JAVA_HOME=/opt/java
export CLASSPATH=.:%JAVA_HOME%/lib/dt.jar:%JAVA_HOME%/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
2:配置每台机器的主机名
清空每台机器上的/etc/hosts文件内容,添加如下:
192.168.48.130 master1
192.168.48.131 slave1
192.168.48.132 slave2
执行完之后source/etc/hosts
同时修改每台机器上的/etc/sysconfig/network 中hostname对应的用户名(此步骤一定要注意,否则容易找不到主机名)
3:给master用户增加sudo权限
1)切换到root用户,su 输入密码
2)给sudoers增加写权限:chmod u+w /etc/sudoers
3)编译sudoers文件:vim /etc/sudoers在root ALL=(ALL) ALL下方增加 master ALL=(ALL)NOPASSWD:ALL
4)去掉sudoers文件的写权限:chmod u-w /etc/sudoers
4:每台机器都切换到master用户下
su master
5:配置SSH免密码登录
进入~/.ssh目录
每台机器执行:ssh-keygen -t rsa,一路回车
生成两个文件,一个私钥,一个公钥,在master1中执行:cp id_rsa.pub authorized_keys
a:本机无密钥登录
修改authorized_keys权限:chmod 644 authorized_keys
此时重启ssh服务:sudo service sshd restart
ssh master1
yes!!!
b:master与其他节点无密钥登录
从master中把authorized_keys分发到各个结点上(会提示输入密码,输入thinkgamer即可):
scp /home/master/.ssh/authorized_keys slave1:/home/master/.ssh
scp /home/master/.ssh/authorized_keys slave2:/home/master/.ssh
然后在各个节点对authorized_keys执行(一定要执行该步,否则会报错):chmod 644 authorized_keys
测试如下(第一次ssh时会提示输入yes/no,输入yes即可):
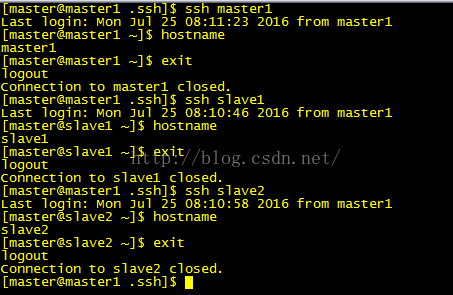
6:解压hadoop到指定目录(我这里使用的是/opt/目录)
tar -zxvf hadoop-2.7.0.tar.gz /opt/hadoop-2.7.0
重命名文件:mv /opt/hadoop-2.7.0 /opt/hadoop
7:修改配置文件
hadoop-env.sh:
- export JAVA_HOME=/opt/java
core-site.xml:
- <configuration>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://master1:9000</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/opt/hadoop/tmp</value>
- </property>
- </configuration>
hdfs-site.xml:
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>2</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>file:/opt/hadoop/dfs/name</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>file:/opt/hadoop/dfs/data</value>
- </property>
- </configuration>
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>Master:10020</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>Master:19888</value>
- </property>
- </configuration>
- <configuration>
- <!-- Site specific YARN configuration properties -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
- <value>org.apache.hadoop.mapred.ShuffleHandler</value>
- </property>
- <property>
- <name>yarn.resourcemanager.address</name>
- <value>master1:8032</value>
- </property>
- <property>
- <name>yarn.resourcemanager.scheduler.address</name>
- <value>master1:8030</value>
- </property>
- <property>
- <name>yarn.resourcemanager.resource-tracker.address</name>
- <value>master1:8031</value>
- </property>
- <property>
- <name>yarn.resourcemanager.admin.address</name>
- <value>master1:8033</value>
- </property>
- <property>
- <name>yarn.resourcemanager.webapp.address</name>
- <value>master1:8088</value>
- </property>
- </configuration>
8:编辑slaves文件
清空加入从节点的名字
slave1
slave2
9:将hadoop分发到各个节点(因为权限问题,先将该文件夹分发到各个节点的/home/master目录下,再进入各个节点将文件夹移到/opt下)
scp -r /opt/hadoop slave1:/home/master/hadoop ,进入该节点执行:sudo mv hadoop /opt/
scp -r /opt/hadoop slave2:/home/master/hadoop ,进入该节点执行:sudo mv hadoop /opt/
10:在master节点格式化hdfs
bin/hdfs namenode -format

看见status 0表示安装成功
四:web页面查看
1:http://192.168.48.130:8088/
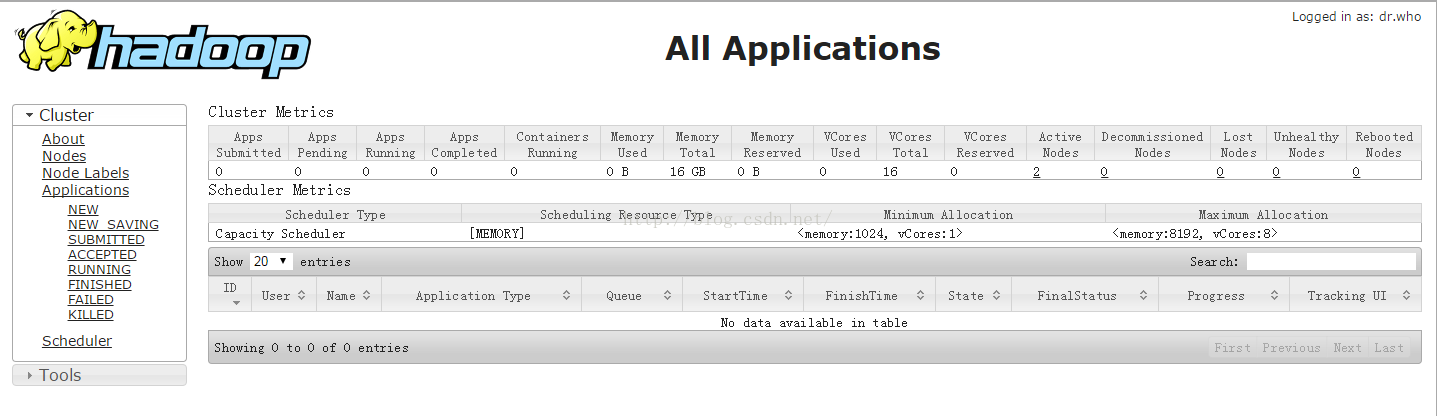
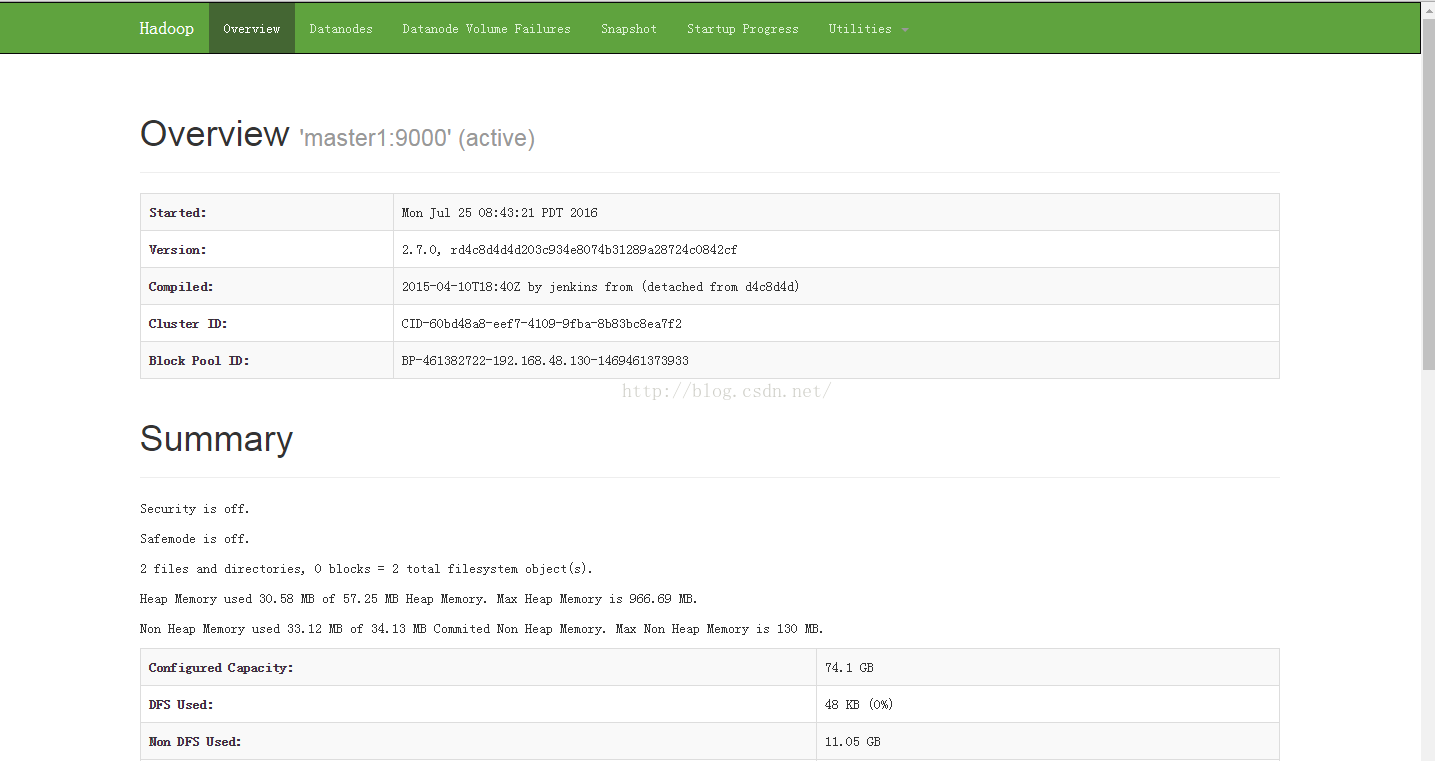
2:http://192.168.48.130:50070/
五:问题记录
1:linux文件夹权限
eg:
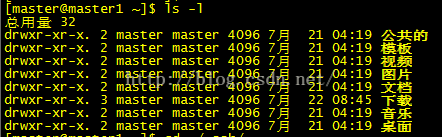
第一列共有十位
第一位,d:表示是一个目录,-:表示一个普通的文件
第2-4位:rwx:分别表示读,写,执行,这里显示为rwx表示文件所有者对该文件拥有读写执行的权利(补充一点,rwx用数字表示为4,2,1)
第5-7位:r-x:表示与该文件所有者的同组用户拥有该文件的读和执行的权限
第8-10位:r-x:表示其他组的用户对该文件拥有读和执行的权利
2:linux基本命令
查看用户所属用户组 id hostname / groups hostname
vim命令: 查找:/xxxx
清空: gg dG
参考: http://www.cnblogs.com/laov/p/3421479.html
http://www.aboutyun.com/thread-7781-1-1.html
http://blog.sina.com.cn/s/blog_821d83720102vkx5.html
http://www.aboutyun.com/thread-10572-1-1.html(HA配置)