关于过拟合和欠拟合
其他
2020-01-23 12:30:20
阅读次数: 0
铺垫
- 首先考虑一下,机器学习模型的本质是什么?它的本质其实就是一个函数,其作用是实现从一个样本 x 到样本的目标值 y 的映射,即 f(x)=y。
- 那么这个函数,是不是在空间中可以通过绘图绘制出来?我们不去真正的画某一个模型的几何图形,我们只假设某一个算法模型在不断的通过样本锻炼的过程中,在几何里形成了下图的三个阶段。
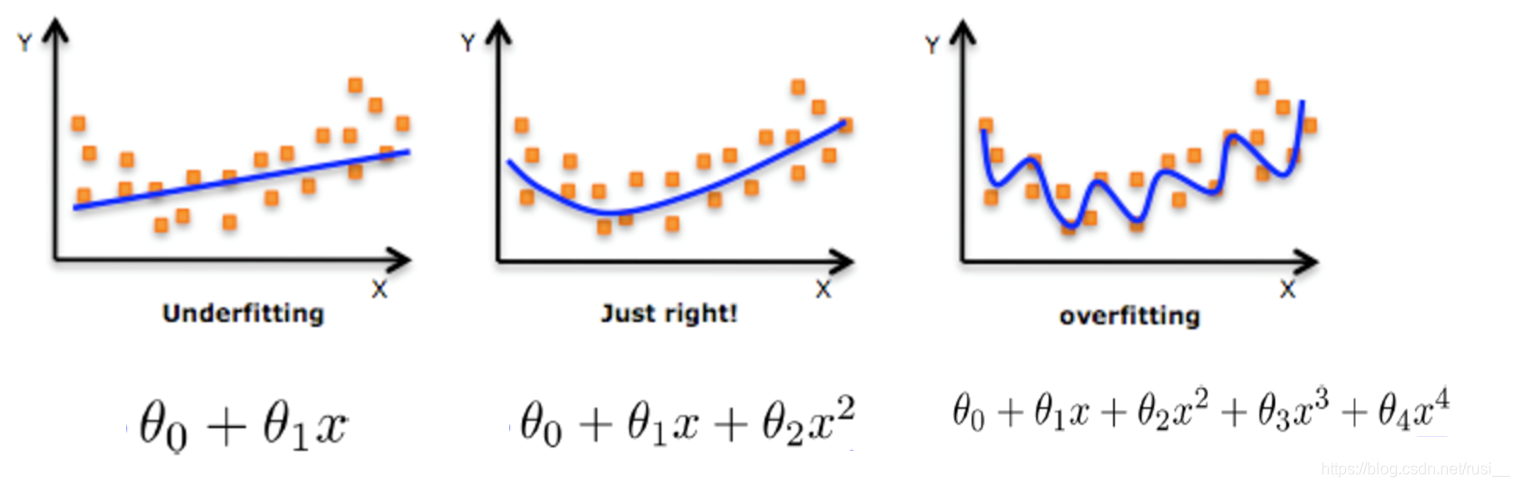
- 假设每个点是样本的目标值,那么?哪个图?或者说哪个阶段锻炼出来的算法模型能更好的反映数据?显而易见是第二个。
- 由此引出过拟合和欠拟合的概念。
- 在详细了解过拟合和欠拟合之前有必要了解一下拟合的概念:形象的说,拟合就是把平面上一系列的点,用一条光滑的曲线连接起来。因为这条曲线有无数种可能,从而有各种拟合方法。
过拟合:
- 那么过拟合就是把这个“曲线”画的过分了,也就是第三个图。
- 机器学习上过拟合的体现:一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在训练数据外的数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型训练过度,模型复杂)
- 具体表现:训练集交叉验证时,发现模型效果很好,一用测试集测试 时,模型效果反差较大时。
- 原因:原始特征过多,存在嘈杂特征,
- 解决方法(特征选择):
- 回归问题:1、消除关联性大的特征(不太好弄),2、正则化(常用)。
- 较为通俗的说一下正则化:正则化又称权重衰减,它可以通过 不断的尝试来调整特征权重项
θ 的值,使得搞次项的值减小到趋向于0,进而缓和“高次项特征”对算法模型的影响。详细了解:参考:正则化详解
- 分类问题:PCA主成分分析、低方差降维、决策树思想:剔除信息增益小的特征、随机森林思想:使答案具有普遍性、交叉验证…说是说不完的,短时间也也想不全,
- 补充解决过拟合的话,可以参考:过拟合解决方案
欠拟合:
- 欠拟合就是这个“线”画的太敷衍,也就是第一个图。
- 机器学习上欠拟合的体现:一个假设在训练数据上不能获得更好的拟合, 而且在训练数据外的数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型训练简单,模型简单)。
- 具体表现: 无论是训练集交叉验证,还是测试集测试时,效果都很差的时候。
- 原因: 数据特征过少。
- 解决方法:获取数据或构造特征以增加特征数量。
补充
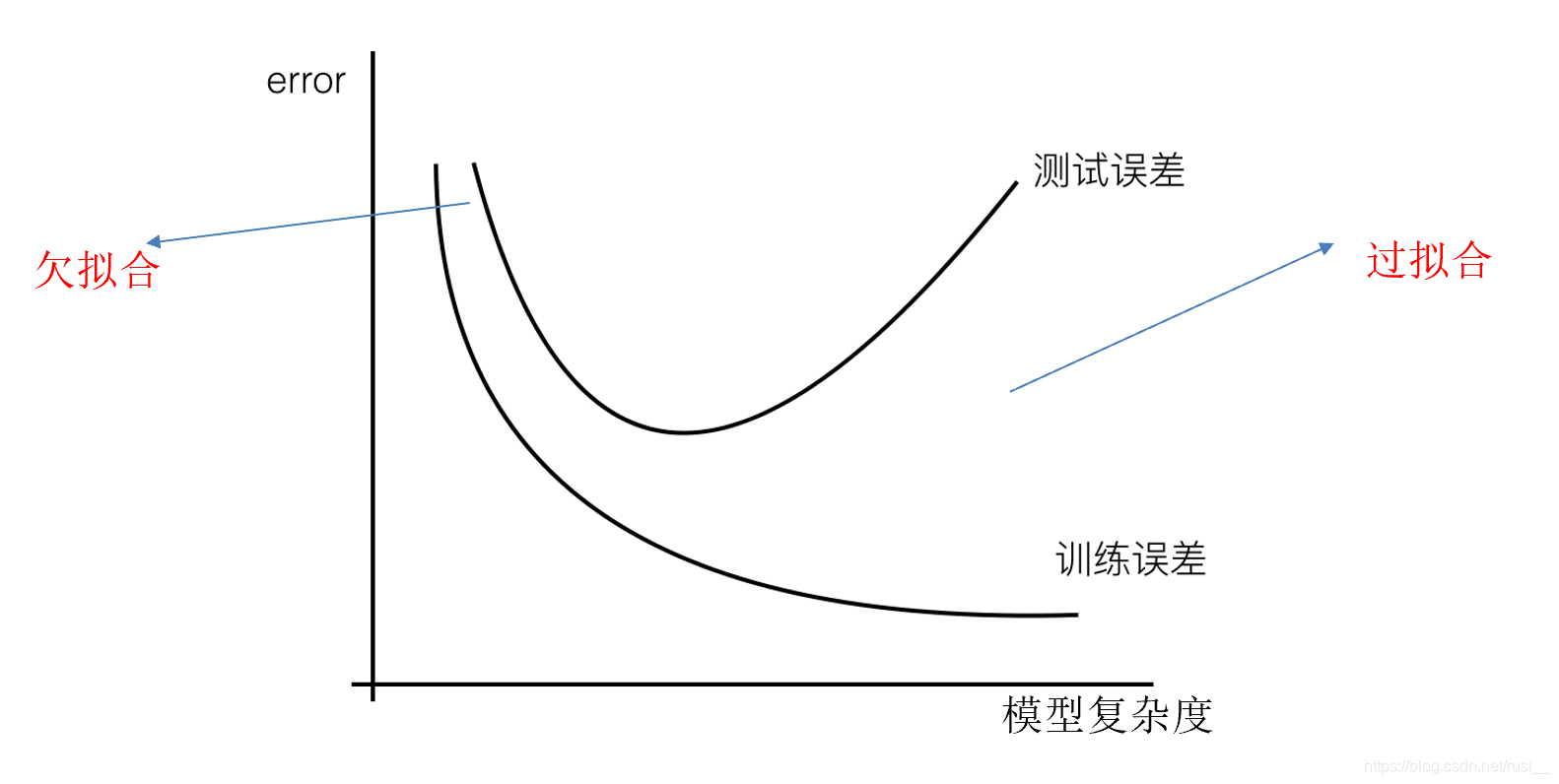
- 最后,我们通过一个图来看一下欠拟合阶段和过拟合阶段在算法模型中的影响吧。
发布了55 篇原创文章 ·
获赞 3 ·
访问量 2717
转载自blog.csdn.net/rusi__/article/details/103931397
