接下来要介绍的是基于贪心算法的图搜索算法Dja, 和 A*
什么是贪心算法?意思就是我们总是向离终点最近的搜索方向去搜索:
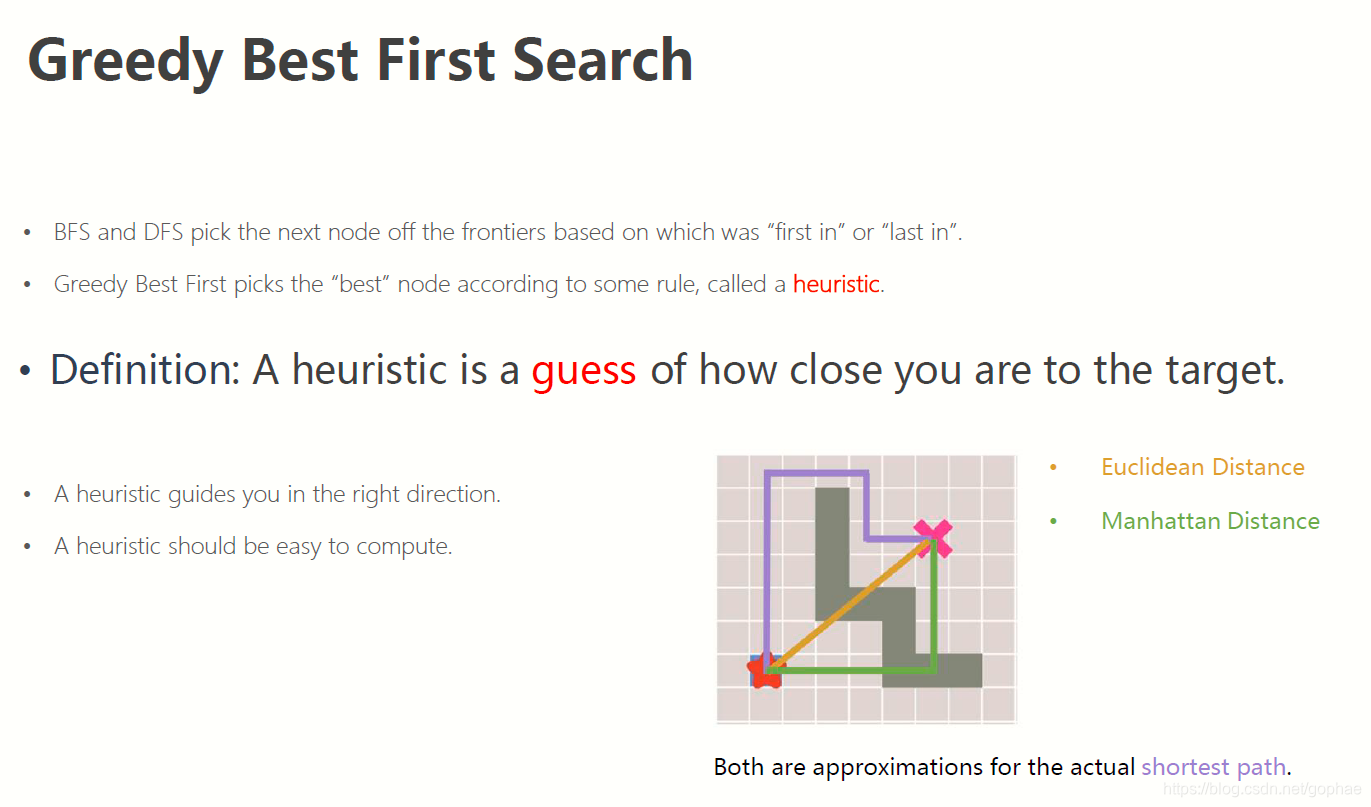
Dja 算法的原理就是通过对搜索点构造cost function, 搜索方向总是朝向cost function 最低的方向。而这个cost function 直接就是从起点到当前点的代价总和:


举个简单的例子:
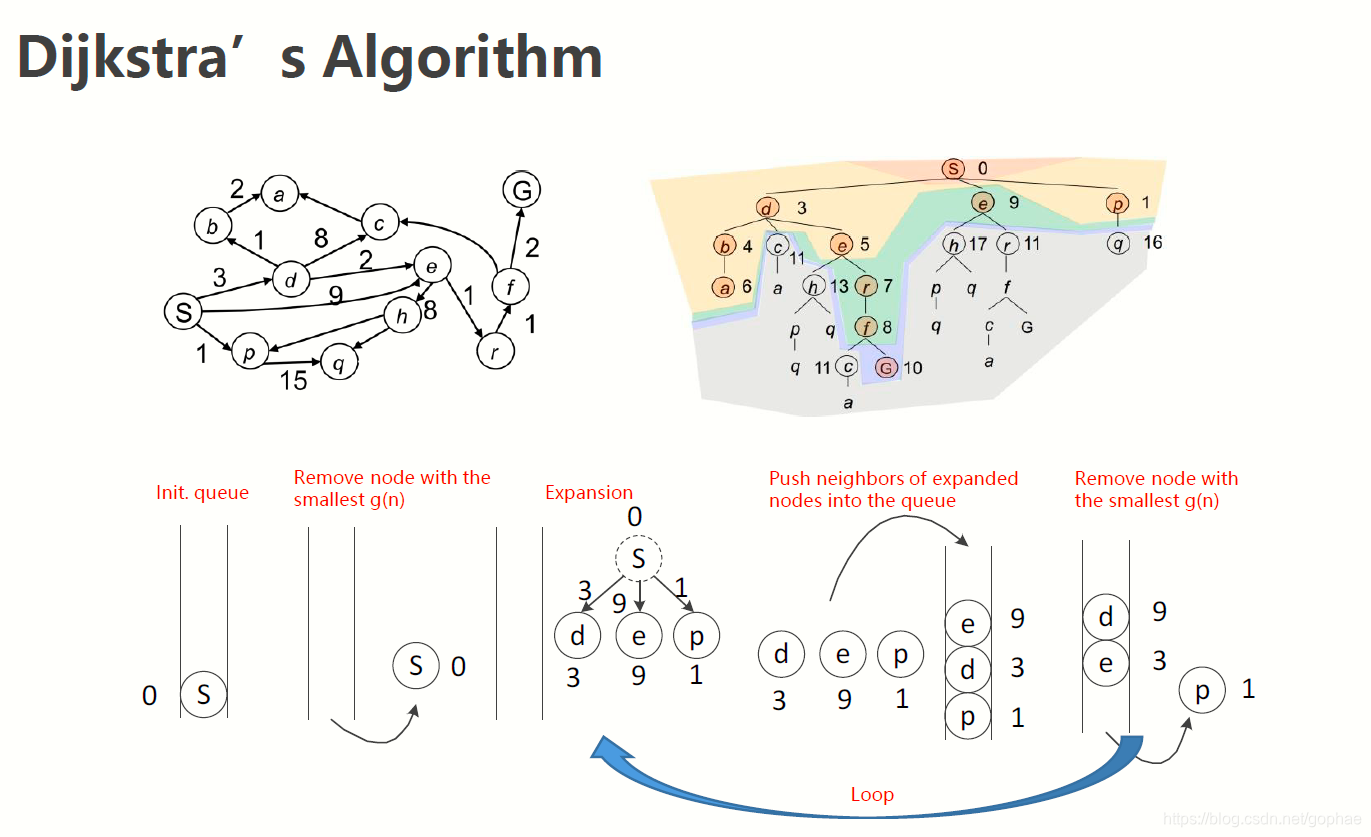
如图,起点是S, 从S 往后拓展,有 dep三个点,代价函数最低的是P, 把P拿出来,对P进行拓展,子节点就是q, 一起类推,不断地进行循环,一直到找到终点为止。
但是Dja的问题还是效率问题。
对于A来说,这个算法就是带了启发函数的Dja:我们的cost function 不再是g, 而是外加了一个启发项h, 表示当前的节点与终点的远近。

与Dja相比,唯一的区别就是cost function 的计算不同:

还是举一个简单的例子:
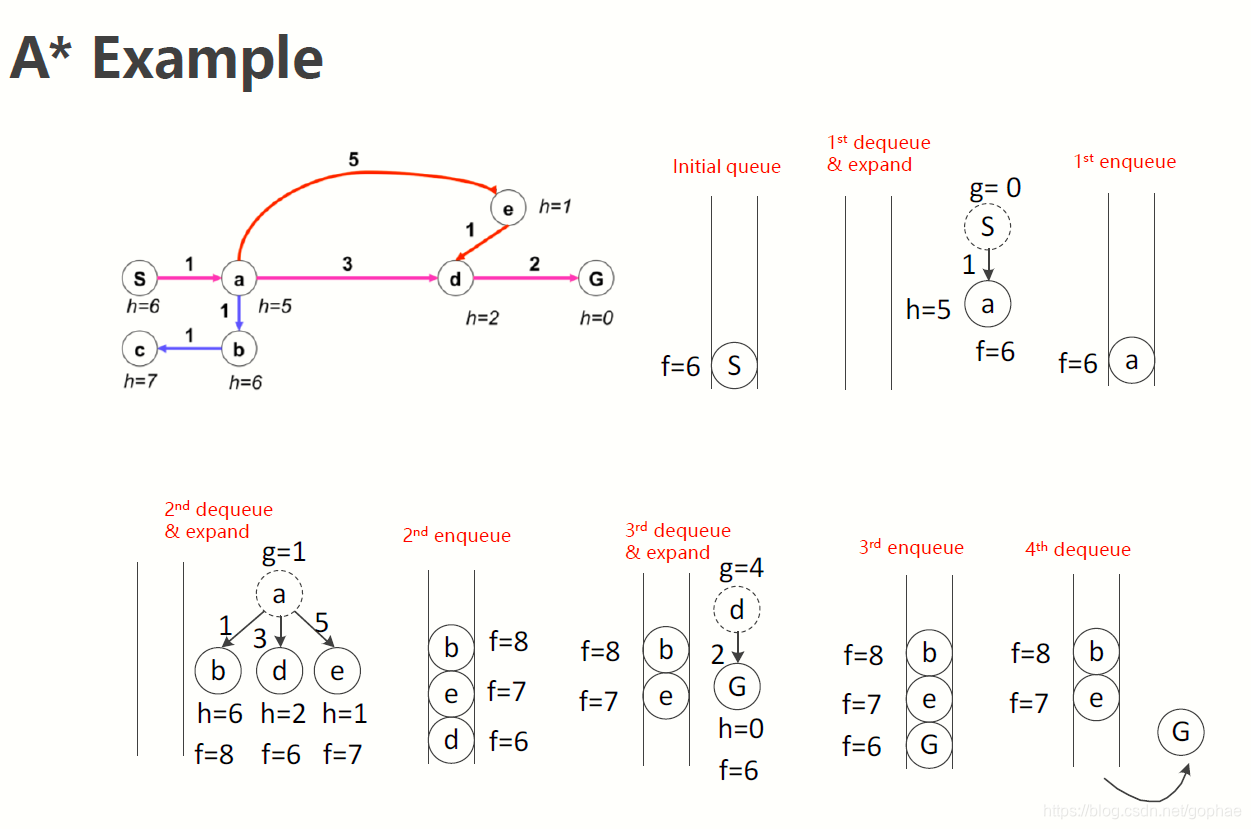
我们从起点a开始,进行拓展,获得三个子节点,bed, 计算cost function, 这是g and h 的总和,最低的是d, 接下来对d进行拓展,子节点是G, 正好就是终点,最后对这一分支进行回溯,将路线回溯到起点,就是我们的最优路径了。
但是需要注意的是,A算法不一定能够保证路径的全局最优性。
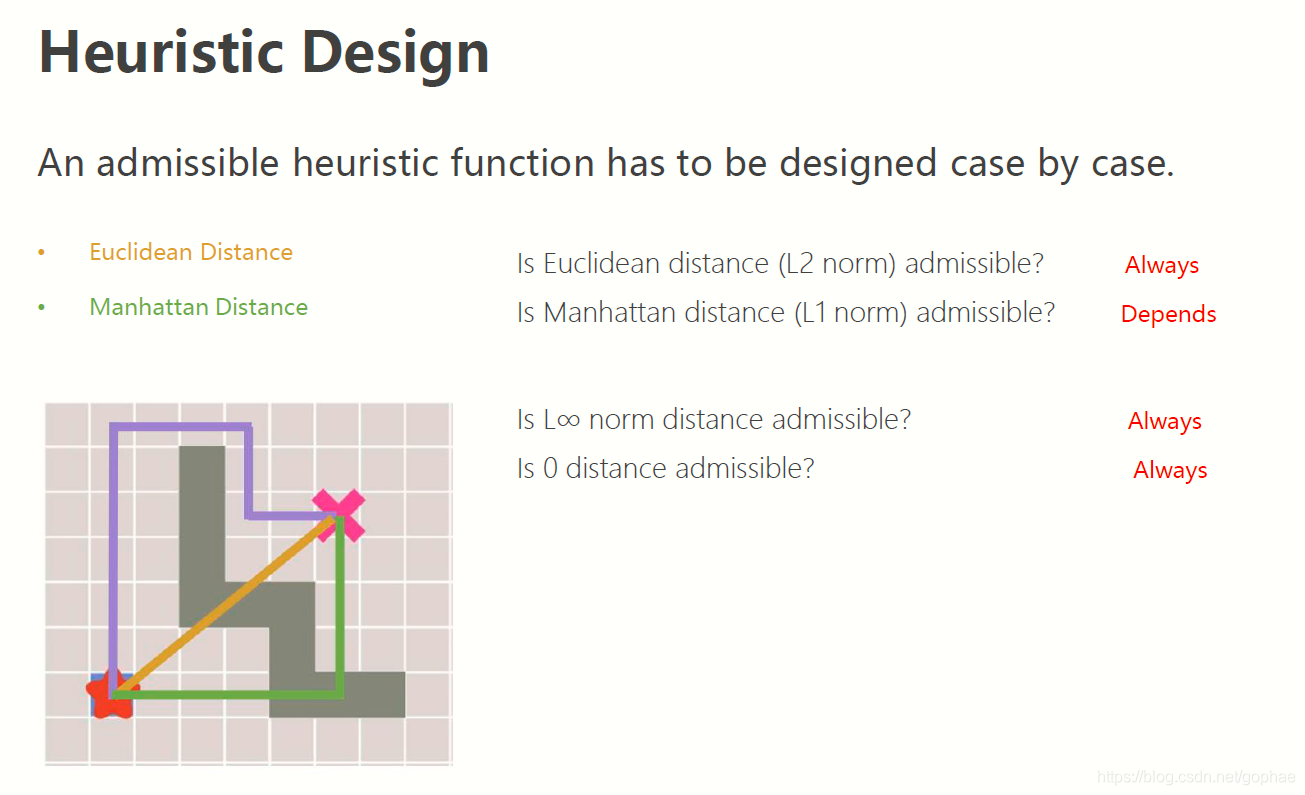
我们说到,启发函数的这个远近是可以任意设定的,只要保证 h<=h*, 意思是,这个设定的距离要小于等于两点之间的真实距离,所以L2 norm 是肯定可以保证的,而L1 norm 则不一定能保证。

L infinite norm是肯定可以保证的,0 也是可以保证的,极端情况下,这个H = 0, A* 就变成了Dja.
对于两种算法的效率对比, 直接从搜索空间上就可以看出区别:
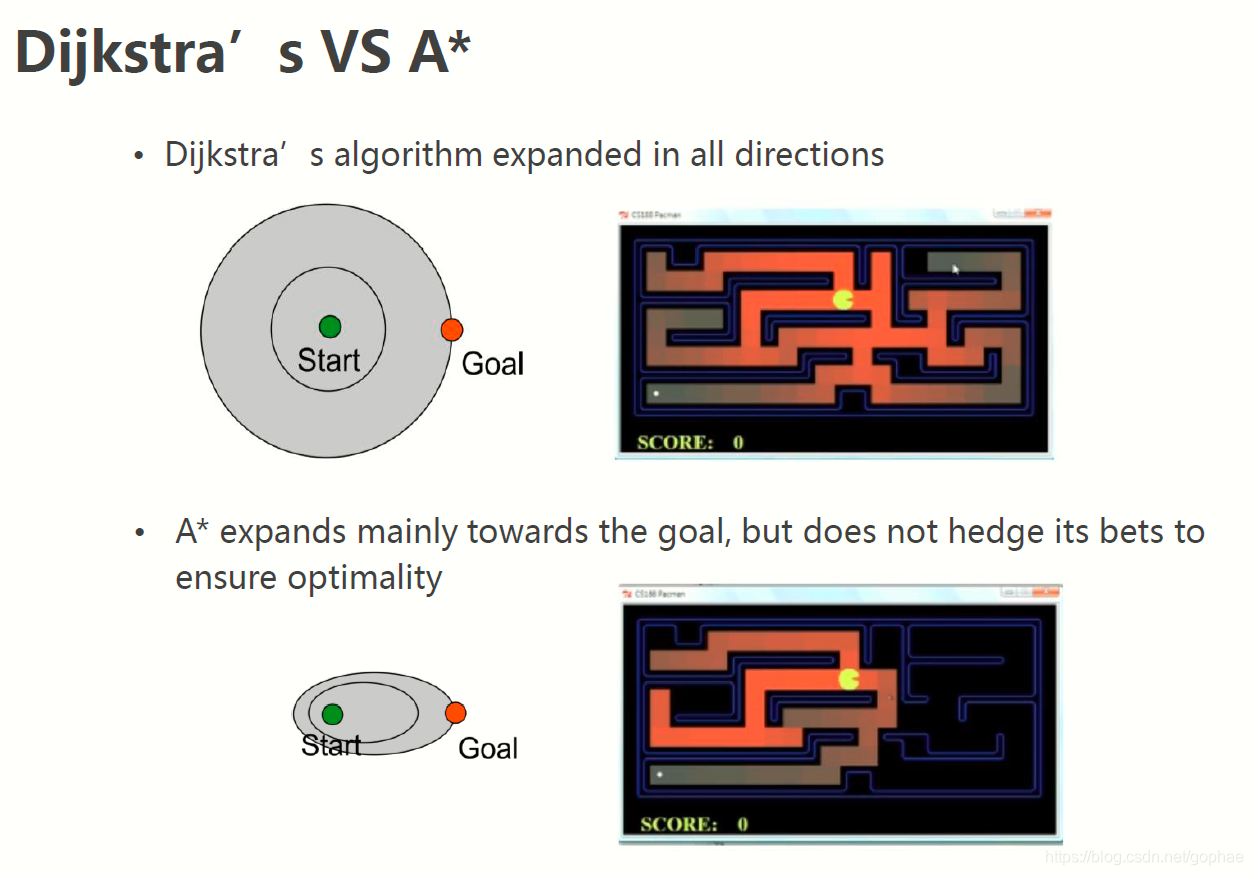
很显然,在二维超平面上,A* 算法的下界条件数是高于Dja的,因此收敛效率也更高,这也是对最优解出Hessian 矩阵的条件数的几何解释。
最后还有个一个问题, 如何跳出局部最优解,这个问题可以通过引入松弛因子 epsilon来解决:
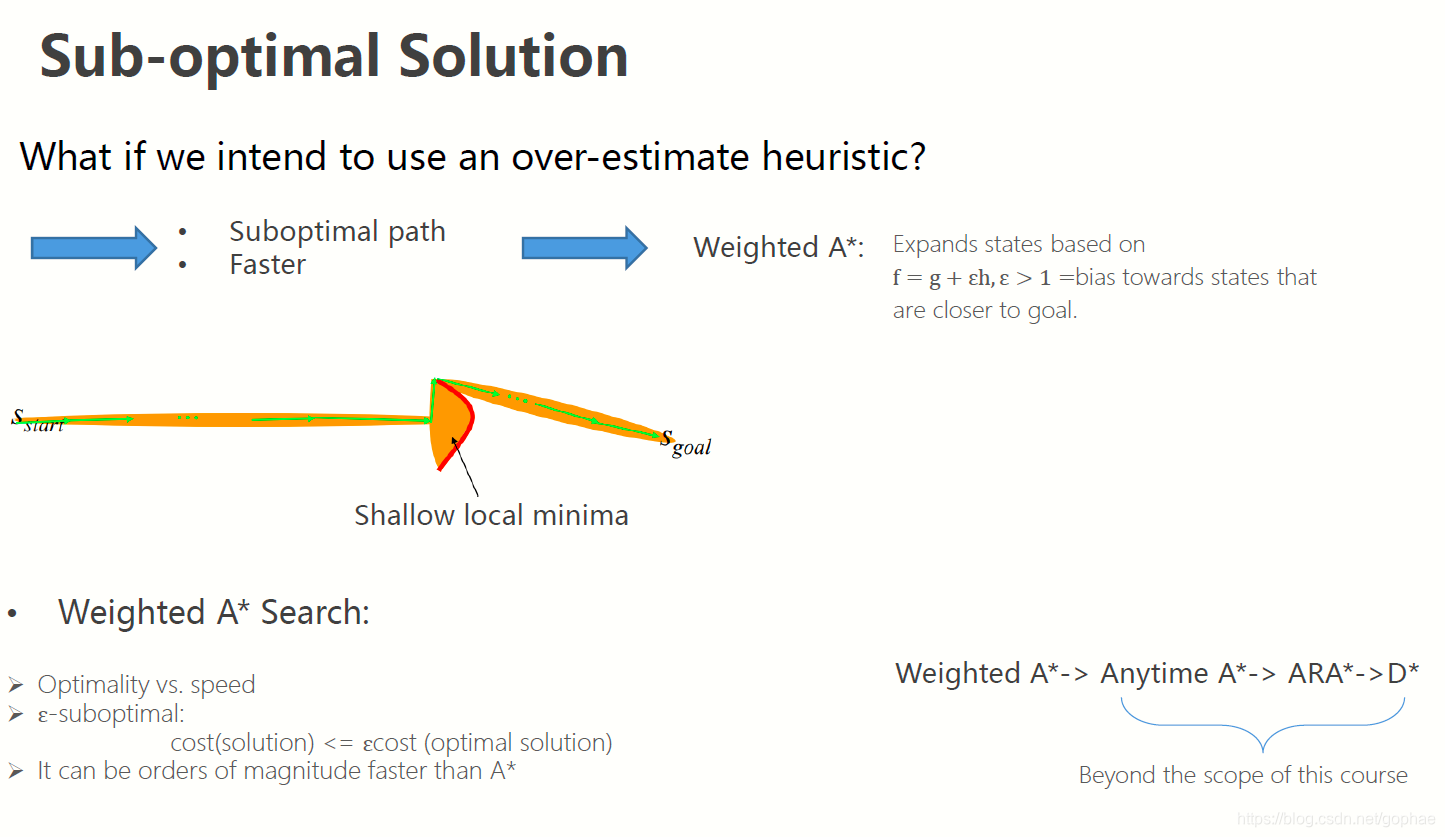
我们对h进行一个处理,来缩小或者放大启发函数对总的cost function 的影响。epsilon越大,则算法就越贪心,越有可能陷入局部最优解。
