1. 定义
A算法,A(A-Star)算法是一种静态路网中求解最短路径最有效的直接搜索方法,也是解决许多搜索问题的有效算法。算法中的距离估算值与实际值越接近,最终搜索速度越快。
1.1 定义解析
- A*算法是一个“搜索算法”,实质上是广度优先搜索算法(BFS)的优化。从起点开始,首先遍历起点周围邻近的点,然后再遍历已经遍历过的点邻近的点,逐步的向外扩散,直到找到终点。
- A*算法的作用是“求解最短路径” ,如在一张有障碍物的图上移动到目标点,以及八数码问题(从一个状态到另一个状态的最短途径)
- A*算法的思路类似图的Dijkstra算法,采用贪心的策略,即“若A到C的最短路径经过B,则A到B的那一段必须取最短” ,找出起点到每个可能到达的点的最短路径并记录。
- A算法与Dijkstra算法的不同之处在于,A算法是一个“启发式”算法,它已经有了一些我们告诉它的先验知识,如“朝着终点的方向走更可能走到”。它不仅关注已走过的路径,还会对未走过的点或状态进行预测。因此A算法相交与Dijkstra而言调整了进行BFS的顺序,少搜索了哪些“不太可能经过的点”,更快地找到目标点的最短路径。另外一点,由于H选取的不同,A算法找到的路径可能并不是最短的,但是牺牲准确率带来的是效率的提升。
1.2 Dijkstra算法与最佳优先搜索
1.2.1 Dijkstra算法(距离起始点的信息)
Dijkstra算法从物体所在的初始点开始,访问图中的结点。它迭代检查待检查结点集中的结点,并把和该结点最靠近的尚未检查的结点加入待检查结点集。该结点集从初始结点向外扩展,直到到达目标结点。Dijkstra算法保证能找到一条从初始点到目标点的最短路径,只要所有的边都有一个非负的代价值。(我说“最短路径”是因为经常会出现许多差不多短的路径。)在下图中,粉红色的结点是初始结点,蓝色的是目标点,而类菱形的有色区域(注:原文是teal areas)则是Dijkstra算法扫描过的区域。颜色最淡的区域是那些离初始点最远的,因而形成探测过程(exploration)的边境(frontier):

1.2.2 最佳优先搜索(距离终点的信息)
最佳优先搜索(BFS)算法按照类似的流程运行,不同的是它能够评估(称为启发式的)任意结点到目标点的代价。与选择离初始结点最近的结点不同的是,它选择离目标最近的结点。BFS不能保证找到一条最短路径。然而,它比Dijkstra算法快的多,因为它用了一个启发式函数(heuristic function)快速地导向目标结点。例如,如果目标位于出发点的南方,BFS将趋向于导向南方的路径。在下面的图中,越黄的结点代表越高的启发式值(移动到目标的代价高),而越黑的结点代表越低的启发式值(移动到目标的代价低)。这表明了与Dijkstra 算法相比,BFS运行得更快。

1.2.3 以上两种算法的缺点:
然而,这两个例子都仅仅是最简单的情况——地图中没有障碍物,最短路径是直线的。现在我们来考虑前边描述的凹型障碍物。Dijkstra算法运行得较慢,但确实能保证找到一条最短路径:

另一方面,BFS运行得较快,但是它找到的路径明显不是一条好的路径:
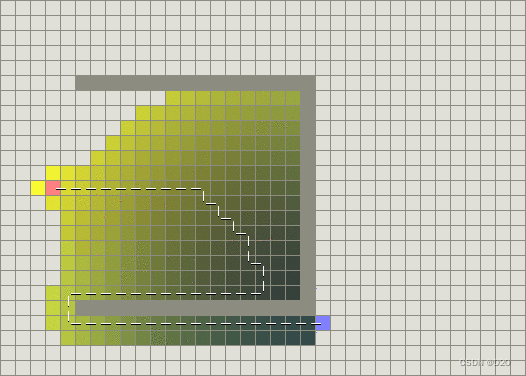
问题在于BFS是基于贪心策略的,它试图向目标移动尽管这不是正确的路径。由于它仅仅考虑到达目标的代价,而忽略了当前已花费的代价,于是尽管路径变得很长,它仍然继续走下去。
1.2.4 结合两者优势的A*算法
结合两者的优点不是更好吗?1968年发明的A算法就是把启发式方法(heuristic approaches)如BFS,和常规方法如Dijsktra算法结合在一起的算法。有点不同的是,类似BFS的启发式方法经常给出一个近似解而不是保证最佳解。然而,尽管A基于无法保证最佳解的启发式方法,A却能保证找到一条最短路径。
和其它的图搜索算法一样,A潜在地搜索图中一个很大的区域。和Dijkstra一样,A能用于搜索最短路径。和BFS一样,A能用启发式函数(注:原文为heuristic)引导它自己。在简单的情况中,它和BFS一样快。

在凹型障碍物的例子中,A找到一条和Dijkstra算法一样好的路径:

成功的秘决在于,它把Dijkstra算法(靠近初始点的结点)和BFS算法(靠近目标点的结点)的信息块结合起来。在讨论A的标准术语中,g(n)表示从初始结点到任意结点n的代价,h(n)表示从结点n到目标点的启发式评估代价(heuristic estimated cost)。在上图中,yellow(h)表示远离目标的结点而teal(g)表示远离初始点的结点。当从初始点向目标点移动时,A*权衡这两者。每次进行主循环时,它检查f(n)最小的结点n,其中f(n) = g(n) + h(n)。
2. 关键内容——启发函数
计算出组成路径的方格的关键是下面这个等式(启发函数):
F = G + H F=G+H F=G+H
2.1 G 与 H 的含义
这里,
-
G = 从起点 A 移动到指定方格的移动代价,沿着到达该方格而生成的路径。
-
H = 从指定的方格移动到终点 B 的估算成本。这个通常被称为试探法,有点让人混淆。为什么这么叫呢,因为这是个猜测。直到我们找到了路径我们才会知道真正的距离,因为途中有各种各样的东西 ( 比如墙壁,水等 ) 。
-
G来源于已知点信息,H来源于对未知点信息的估计,F为选择下一个将遍历节点的依据。
2.2 H的特征
此外,H还有一个特征:
- h(n)=0: 在极端情况下,当启发函数h(n)始终为0,则将由g(n)决定节点的优先级,此时算法就退化成了Dijkstra算法。
- h(n)很小: 如果h(n)始终小于等于节点n到终点的代价,则A*算法保证一定能够找到最短路径。但是当h(n)的值越小,算法将遍历越多的节点,也就导致算法越慢。
- h(n)等于实际cost: 如果h(n)完全等于节点n到终点的代价,则A*算法将找到最佳路径,并且速度很快。可惜的是,并非所有场景下都能做到这一点。因为在没有达到终点之前,我们很难确切算出距离终点还有多远。
- h(n)大于实际cost:如果h(n)的值比节点n到终点的代价要大,则A*算法不能保证找到最短路径,不过此时会很快。
- h(n)非常大:在另外一个极端情况下,如果h(n)相较于g(n)大很多,则此时只有h(n)产生效果,这也就变成了最佳优先搜索。
由上面这些信息我们可以知道,通过调节启发函数我们可以控制算法的速度和精确度。因为在一些情况,我们可能未必需要最短路径,而是希望能够尽快找到一个路径即可。这也是A*算法比较灵活的地方。
2.3 网格地图中估算 H 的启发式方法
对于网格形式的图,有以下这些启发函数可以使用:
- 如果图形中只允许朝上下左右四个方向移动,则可以使用曼哈顿距离(Manhattan distance)。计算从当前万格横可或纵回移动到达目标所经过的方格数。
- 如果图形中允许朝八个方向移动,则可以使用对角距离。横纵移动和对角移动都是合法的。为提高效率,常取整数作系数10,14.
- 如果图形中允许朝任何方向移动,则可以使用欧几里得距离(Euclidean distance)。两点直线距离。
- 其他方法见论文
3. 算法流程
3.1 开始搜索(Starting the Search)
一旦我们把搜寻区域简化为一组可以量化的节点后,就像上面做的一样,我们下一步要做的便是查找最短路径。在 A* 中,我们从起点开始,检查其相邻的方格,然后向四周扩展,直至找到目标。
我们这样开始我们的寻路旅途:
-
从起点 A 开始,并把它就加入到一个由方格组成的 open list( 开放列表 ) 中。这个 open list 有点像是一个购物单。当然现在 open list 里只有一项,它就是起点 A ,后面会慢慢加入更多的项。 Open list 里的格子都是下一步可以到达的(当然可能是退回某点后下一步到达),在最终最短路径中,open list中的格子可能会是沿途经过的,也有可能不经过。基本上 open list 是一个待检查的方格列表。
-
查看与起点 A 相邻的方格 ( 忽略其中墙壁所占领的方格,河流所占领的方格及其他非法地形占领的方格 ) ,把其中可走的 (walkable) 或可到达的 (reachable) 方格也加入到 open list 中。把起点 A 设置为这些方格的父亲 (parent node 或 parent square) 。当我们在追踪路径时,这些父节点的内容是很重要的。因为它记录了从起点到该点的最短路径上经过的最后一个节点。
-
把 A 从 open list 中移除,加入到 close list( 封闭列表 ) 中, close list 中的每个方格都是现在不需要再关注的。
-
下一步,我们需要从 open list 中选一个方格,重复23步骤。但是到底选择哪个方格好呢?具有最小 F 值的那个。
所以,我们的路径是这么产生的:反复遍历 open list ,选择 F 值最小的方格,产生新的可供选择的方格,直到找到终点方格。这个过程稍后在“继续搜索”详细描述。我们还是先看看怎么去计算上面的等式。
3.1.1 计算启发函数
如上所述, G 是从起点A移动到指定方格的移动代价。H是从指定方格移动到终点的估计代价。
- G的计算思路类似图的Dijkstra算法,采用贪心的策略,即“若A到C的最短路径经过B,则A到B的那一段必须取最短”,找出起点到每个可能到达的点的最短路径并记录。既然我们是沿着到达指定方格的路径来计算 G 值,那么计算出该方格的 G 值的方法就是找出其父亲的 G 值,然后按父亲是直线方向还是斜线方向加上 10 或 14 。
- 有很多方法可以估算 H 值。这里我们使用 Manhattan 方法,计算从当前方格横向或纵向移动到达目标所经过的方格数,忽略对角移动,然后把总数乘以 10 。重要的是,计算 H 是,要忽略路径中的障碍物。这是对剩余距离的估算值,而不是实际值,因此才称为试探法。
3.1.2 openlist 与closelist
如果不考虑具体实现代码,A*算法是相当简单的。有两个集合,OPEN集和CLOSED集。
- 其中OPEN集保存待考查的结点。开始时,OPEN集只包含一个元素:初始结点。
- CLOSED集保存已考查过的结点。开始时,CLOSED集是空的。
- 如果绘成图,OPEN集就是被访问区域的边境(frontier)而CLOSED集则是被访问区域的内部(interior)。
- 每个结点同时保存其父结点的指针因此我们可以知道它是如何被找到的。
在主循环中重复地从OPEN集中取出最好的结点n(f值最小的结点)并检查之。如果n是目标结点,则我们的任务完成了。否则,结点n被从OPEN集中删除并加入CLOSED集。然后检查它的邻居n’。如果邻居n’在CLOSED集中,那么它是已经被检查过的,所以我们不需要考虑它*;如果n’在OPEN集中,那么它是以后肯定会被检查的,所以我们现在不考虑它*。否则,把它加入OPEN集,把它的父结点设为n。到达n’的路径的代价g(n’) ,设定为g(n) + movementcost(n, n’) 。
(*)这里我忽略了一个小细节。你确实需要检查结点的g值是否更小了,如果是的话,需要重新打开(re-open)它。
3.1.3 open集和close集用何种数据结构实现
3.2 继续搜索(Continuing the Search)
为了继续搜索,我们从 open list 中选择 F 值最小的 ( 方格 ) 节点,然后对所选择的方格作如下操作:
-
把它从 open list 里取出,放到 close list 中。
-
检查所有与它相邻的方格,忽略其中在 close list 中或是不可走 (unwalkable) 的方格 ( 比如墙,水,或是其他非法地形 ) ,如果方格不在open lsit 中,则把它们加入到 open list 中。
把我们选定的方格设置为这些新加入的方格的父亲。 -
如果某个相邻的方格已经在 open list 中,则检查这条路径是否更优,也就是说经由当前方格 ( 我们选中的方格 ) 到达那个方格是否具有更小的 G 值。如果没有,不做任何操作。

4. A*算法的变种
4.1 beam search
4.2 迭代深化
4.3 动态衡量
4.4 带宽搜索
4.5 双向搜索
4.6 动态A与终身计划A
5. 算法实现实例
参考资料
解析非常全面的译文,可以重点看
解析+八数码python代码
迷宫寻路python代码
详解+Java代码
A算法与A*算法区别
A*算法解决8数码问题python实现
Dijkstra算法和A*算法总结
最短路经算法简介(Dijkstra算法,A算法,D算法)
A算法 和 IDA算法
无人驾驶汽车系统入门(十六)——最短路径搜索之A*算法