K-近邻算法
优点:精度高,对异常值不敏感,无数据输入假定
缺点:计算复杂度搞,空间复杂度高
适用范围:数值型和标称型
工作原理:存在一个样本数据集合(训练样本集),并且样本集中每个数据都有标签,即我们知道样本集中每以数据与所属分类的对应关系。
输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最为相似数据(最近邻)
的分类标签。一般选择样本数据集中前K个最近似的数据,K <= 20。最后选择k个最相似数据中出现次数最多的分类。作为数据的分类。
K-近邻算法的一般流程:
(1):收集数据
(2):准备数据,距离计算所需要的数值,结构化的数据格式
(3):分析数据
(4):训练算法,此步骤不适用于K-近邻算法
(5):测试算法:计算错误率
(6):使用算法:首先需要输入样本数据和结构化数据的输出结果,然后运行K-近邻算法判定输入数据分别属于哪类,最后应用对计算出的分类
执行后续处理。
实施KNN分类算法
对未知类别墅型的数据集中的每个点一次执行以下操作:
1:计算一直类别数据集中的点与当前点之间的距离;
2:按照距离递增次序进行排序;
3:选取当前点距离最小的k个点;
4:确定前k个点所在类别的出现频率;
5:返回前k个点出现频率最高的类别作为当前点的预测分类;
实施kNN分类算法(造分类器)
伪代码:
- 计算已知类别数据集中的每个点一次执行以下操作;
- 按照距离递增次序排序;
- 选取与当前点距离最小的k个点;
- 确定前k个点所在类别的出现频率;
- 返回前k个点出现频率最高的类别作为当前点的预测分类;
分类器代码
创建一个knn.py文件,将分类器代码添加到knn.py中
#简单的创造一个数据集,用来测试分类器
def createDataSet():
#创建一个二维numpy矩阵
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
#为每一行数据添加标签
labels = ['A','A','B','B']
#返回特征值和标签
return group,labels
#构造分类器
#四个参数分别为 用于分类的输入向量inX,输入的训练样本集,标签向量labels(目标向量),以及最近邻居的数目k
def classify(inX,dataSet,labels,k):
#求出行数
dataSetSize = dataSet.shape[0]
#print('行数为:',dataSetSize)
#将inX数组重复n次,将相对距离x和y求出来(即将所求坐标同已知训练集坐标相减,求出相对距离,得到四个坐标向量值)
diffMat = tile(inX,(dataSetSize,1)) - dataSet
#print("得到的相对距离值:\n",diffMat)
#平方, 进行的是欧式距离公式第二步,
sqDiffMat = diffMat**2
#print("欧式距离公式第二步,将每个相对距离平方:\n",sqDiffMat)
#axis = 1代表行向量相加, 0代表普通的求和 ,,进行的是欧式距离第三步,将平方后的相对距离相加
sqDistances = sqDiffMat.sum(axis = 1)
#开方,计算两个向量点xA和xB之间的距离 ,欧式距离公式的最终一部,开方,求出两个向量点的距离
distances = sqDistances**0.5
#print("欧式距离公式最终步,所求坐标与已知数据集中坐标的距离大小:\n",distances)
#排序,返回从小到大排序后数组中每个元素在排序前的下标
sortedDistIndicies = distances.argsort()
#print("从小到大排序后的每个列表元素在排序前数组中的下标:\n",sortedDistIndicies)
classCount = {}
'''确定前k个点所在类别的频率'''
#print("前%d个点所在的类别分别为:" % k)
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
#print(voteIlabel)
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#print("前%d个点所在类别的频率为:\n" % k,classCount)
'''该步为排序 将classCount字典分解为元组列表,使用运算符模块operator的items方法
(python2.X用的为iteritems())按照第二个元素对元组进行排序,此处排序为逆序,按照从大到小的次序排序,
最后返回发生频率最高的元素标签
'''
sortClassCount = sorted(classCount.items(),key = operator.itemgetter(1),reverse = True)
#print(sortClassCount)
''' 输出 >>> [('B', 2), ('A', 1)] '''
'''返回前k个点出现频率最高的类别作为当前点的预测分类 至此,分类完成'''
return sortClassCount[0][0]
至此,分类器完成,运行结果

2.2分类器完成后,开始正式的改进约会网站的配对效果
大致步骤:
- 收集数据:提供文本文件(数据集);
- 准备数据:使用Python解析文本文件;
- 分析数据:使用matplotlib画二维散点图分析数据;
- 训练算法:不适用于knn算法;
- 测试算法:使用部分数据作为测试样本;
- 使用算法:使可以输入一些数据,城区自动判别出类别;
2.2.1从文本中解析数据
数据集下载网址链接:
https://www.manning.com/books/machine-learning-in-action
数据存放在文本文件datingTestSet.txt中,每个样本数据占一行,总共1000行数据,分四列,三列特征值,分别为:
- 每年获得的飞行常客里程数;
- 玩视频游戏所耗时间百分比;
- 每周消费的冰激凌公升数;
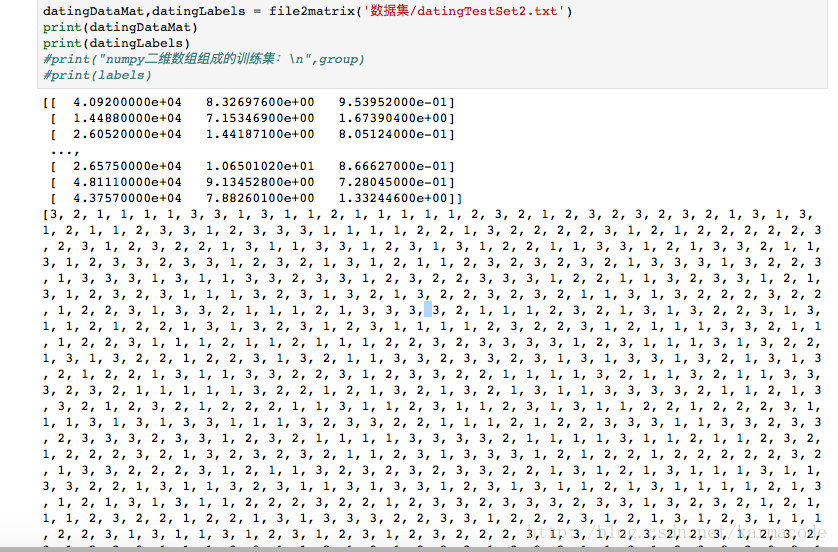
创建file2matrix函数,添加到knn.py中去
#将文本数据转化问numpy解析程序
def file2matrix(filename):
with open(filename) as fp:
arrayOlines = fp.readlines()
numberOfLines = len(arrayOlines)# 得到文件中数据的行数
numberOfLines
returnMat = zeros((numberOfLines,3))#创建出一千行 三列的全为零的numpy矩阵用于存放 特征值
#print(returnMat)
classLabelVector = []#用于存放目标变量即 标签
index = 0
for line in arrayOlines:
line = line.strip()#将数据集中所有的回车符截取掉
listFromLine = line.split('\t')#根据每行数据中一个tap键(\t)分成一个列表 每个列表四个元素
#print(listFromLine)
returnMat[index,:] = listFromLine[0:3]#在每个列表中选取前三个元素存放到之前创建的特征矩阵中
if listFromLine[-1] == "largeDoses":
classLabelVector.append(3)#将列表中的最后一列标签(目标变量)添加到新的列表中
if listFromLine[-1] == "smallDoses":
classLabelVector.append(2)
if listFromLine[-1] == "didntLike":
classLabelVector.append(1)
#classLabelVector.append(int(listFromLine[-1]))#将列表中的最后一列标签(目标变量)添加到新的列表中
index += 1
return returnMat,classLabelVector
将文本转化为numpy数据时,数据集中最后一列的标签是字符串,需要将其变化为1,2,3类,书上的直接int能处理标签问题,但是我怎么试都不行,干脆手动暴力分类了,不过这样也能凑合着使。
转换结果:
处理完成之后就可以利用matplotlib三点图分析数据了
2.2.2 分析数据:使用matplotlib创建散点图
#2.2.2分析数据
#画出玩游戏和消费冰激凌的三点图
import knn
from numpy import array
import matplotlib
import matplotlib.pyplot as plt
import operator
matplotlib.rcParams['font.family'] = 'SimHei'
filepath = '数据集/datingTestSet2.txt'
datingDataMat,datingLabels = knn.file2matrix(filepath)
fig = plt.figure()
ax = fig.add_subplot(111)
#利用datingLabels存储的类标签属性,在散点图上绘制了色彩不等,。尺寸不同的点
ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels))
plt.title('玩游戏和消费冰激凌的散点图')
plt.xlabel(u'玩视频游戏所耗时间百分比')
plt.ylabel(u'每周所消费冰激凌公升数')
plt.show()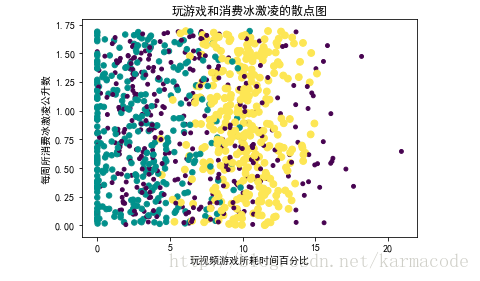
加入后面两个参数可以分成不同颜色散点,可以更好理解数据
最后这样还是不行,虽然散点颜色分类了,但是还是不知道哪种颜色代码哪种特征,于是我就手动添加注释;
下面是采用矩阵的第一和第二列属性 可以获得更好的展示结果。
#2.2.2分析数据
#画出玩游戏和飞行常客里程数的散点图
'''
黄色代表 极具魅力
紫色代表 不喜欢
蓝色代表 魅力一般
'''
import knn
from numpy import array
import matplotlib
import matplotlib.pyplot as plt
import operator
matplotlib.rcParams['font.family'] = 'SimHei'
filepath = '数据集/datingTestSet2.txt'
datingDataMat,datingLabels = knn.file2matrix(filepath)
fig = plt.figure()
ax = fig.add_subplot(111)#创建一行一列为p1的子图
#利用datingLabels存储的类标签属性,在散点图上绘制了色彩不等,。尺寸不同的点
ax.scatter(datingDataMat[:,0],datingDataMat[:,1],15.0*array(datingLabels),15.0*array(datingLabels))
plt.title('玩游戏和每年的飞行常客里程数的散点图')
#添加注释
plt.scatter(0,20,color = 'yellow')
plt.scatter(0,18,color = 'blue')
plt.scatter(0,16,color = 'purple')
plt.text(2000,15.5,"极具魅力\n\n魅力一般\n\n不喜欢")
plt.xlabel(u'每年获取的飞行常客里程数')
plt.ylabel(u'玩视频游戏所耗的时间比')
plt.show()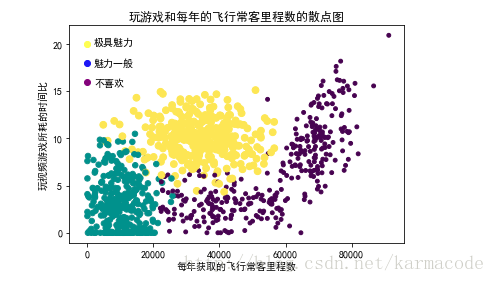
2.2.3准备数据,归一化数值
个人感觉此处的归一化数值完全是为了在开始的时候使用的那个分类器, 不过官方一点的解释是
当数据的样本特征权重不一样,就会导致某一个特征权重的差距太大影响到整体的距离,因此要使用归一化来将这种不同取值范围的特征值归一化,将取值范围处理为0到1,或者-1到1之间;使用如下公式可以讲任意取值范围的特征值转化为0到1区间内的值:
公式
newValue = (oldValue - min)/(max-min) min 和max分别是数据集中的最小特征值和最大特征值
#归一化特征值
def autoNorm(dataset):
#从列中分别取最大值和最小值
minVals = dataset.min(0)
maxVals = dataset.max(0)
#每一列的最大值和最小值之差
ranges = maxVals - minVals
normDataSet = zeros(shape(dataset))
m = dataset.shape[0]
print(ranges)
print(m)
normDataSet = dataset-tile(minVals,(m,1))
normDataSet = normDataSet/tile(ranges,(m,1))
return normDataSet,ranges,minVals
autoNorm(datingDataMat)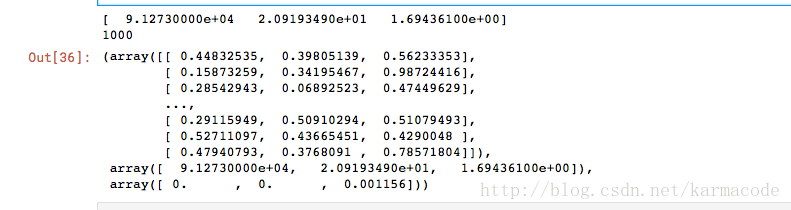
2.2.4测试算法:验证之前写的分类器的错误率;
错误率 = 分类器给出的错误结果次数/测试数据的总数
import knn
#分类器针对约会网站的测试代码
# 测试前面写的分类器的错误率
def datingClassTest():
hoRatio = 0.50
datingDataMat,datingLabels = knn.file2matrix('数据集/datingTestSet2.txt')
normMat,ranges,minvals = knn.autoNorm(datingDataMat)
#print(datingDataMat) #数据集中前三列的特征值
#print(datingLabels) #数据集中的最后一列的目标变量 标签
#print(normMat) #归一化的后的特征值,为了便于将数据添加到分类器中分类
#print(ranges) #归一化后没列特征值的最大与最小值之差
#print(minvals) #归一化后的每列特征值得最小值
m = normMat.shape[0] #总共多少条数据
#只是为了测试分类器的错误率,因此选择总数据的百分之十进行测试 1000条数据添加100条测试
numTestVecs = int(m*hoRatio)
errorCount = 0.0 #分类器给出的错误结果数量
for i in range(numTestVecs):
classifierResult = knn.classify(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
#print("分类器给出的结果是:",classifierResult,"真正的结果是:",datingLabels[i])
if(classifierResult != datingLabels[i]):
errorCount = errorCount + 1.0
print(errorCount)
print("分类器的错误率是%f"%(errorCount/float(numTestVecs)))
datingClassTest()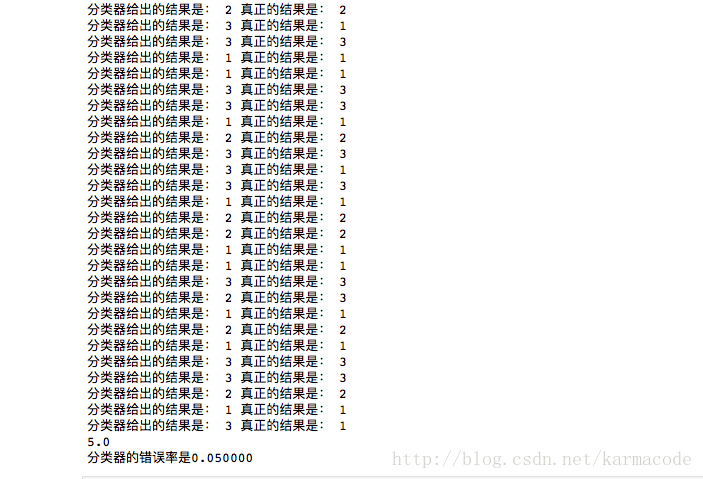
这里,我用的是10%的数据,错误率是5%,还算不错的结果。
2.2.5使用算法,构建完整的系统;
到此为止,分类器写好了,数据集也处理好了,归一化特征值也完成了,错误率也查看了,剩下的就是使用写的knn算法开始实现预测了。
构建完整可用的系统。
#约会网站预测函数 终极必杀
import numpy as np
import knn
#19739 2.816760 1.686209
#340920 8.326976 0.953952
resultList = ['一点也不喜欢','可能会喜欢一点点','超级喜欢的有木有']
percentTats = float(input('请输入玩视频游戏所占的百分比:'))
ffmils = float(input('请输入每年获取的飞行公里数:'))
iceCream = float(input('请输入每周消费的冰激凌公升数:'))
#将训练集导入
datingDataMat,datingLabels = knn.file2matrix('数据集/datingTestSet2.txt')
#开始训练并归一化数值
normMat,ranges,minVals = knn.autoNorm(datingDataMat)
inArr = np.array([ffmils,percentTats,iceCream])
classifierResult = knn.classify((inArr-minVals)/ranges,normMat,datingLabels,3)
print("你会喜欢这个人的可能性:",resultList[classifierResult - 1])

到此,K近邻算法第一个实战完成。
k近邻算法算是机器学习中最简单的一个分类算法,然而我还是啃了好几天才啃的差不多,看来以后的路更难走了,不过,还是要下血本去学的。