李宏毅《深度学习》卷积神经网络CNN:https://www.bilibili.com/video/av9770190/?p=10
1、介绍CNN特性
2、CNN架构
3、Keras
4、应用
卷积神经网络CNN常用于影像处理,每个神经元就是classify,但是用之前讲过的fully connected来进行处理的时候参数会太多
假如3万的维度输入,1000个神经元,那就得是1000*30000个wight,所以我们使用CNN来简化这个架构进行处理

首先,介绍一些CNN的三个特性
1、不需要看整张图片,只需要链接到一小块
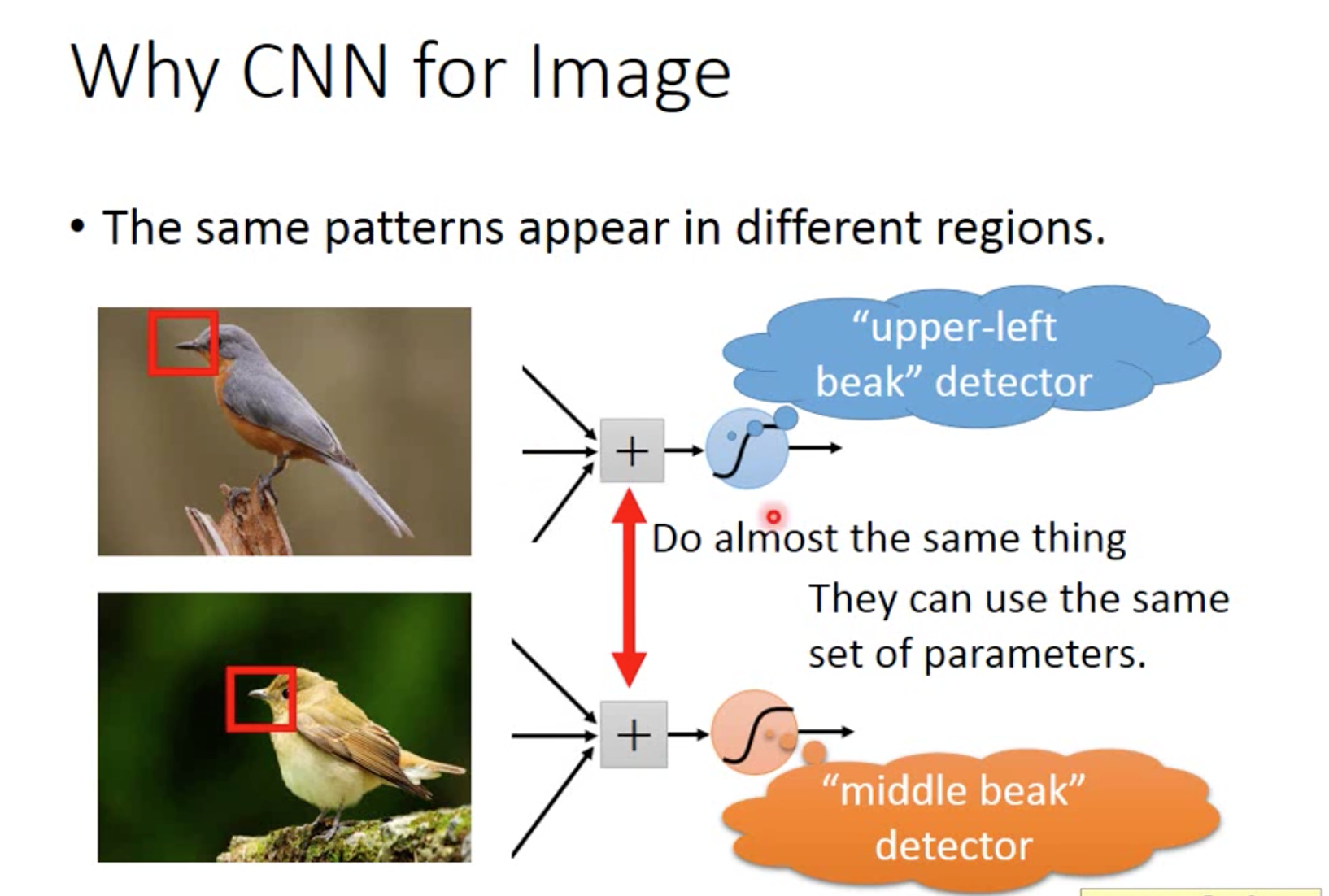
2、相同的pattern可以应用到不同的区域
例如鸟嘴这个pattern,在第一张图片中处于左上角,但是第二张图片中位于中间,但是这个神经元都可以用来识别嘴
3、subsampling
将图片缩小并不会产生影响,这样还可以减小参数

根据这三个特性,我们可以使用CNN,并且在处理图片上非常有效
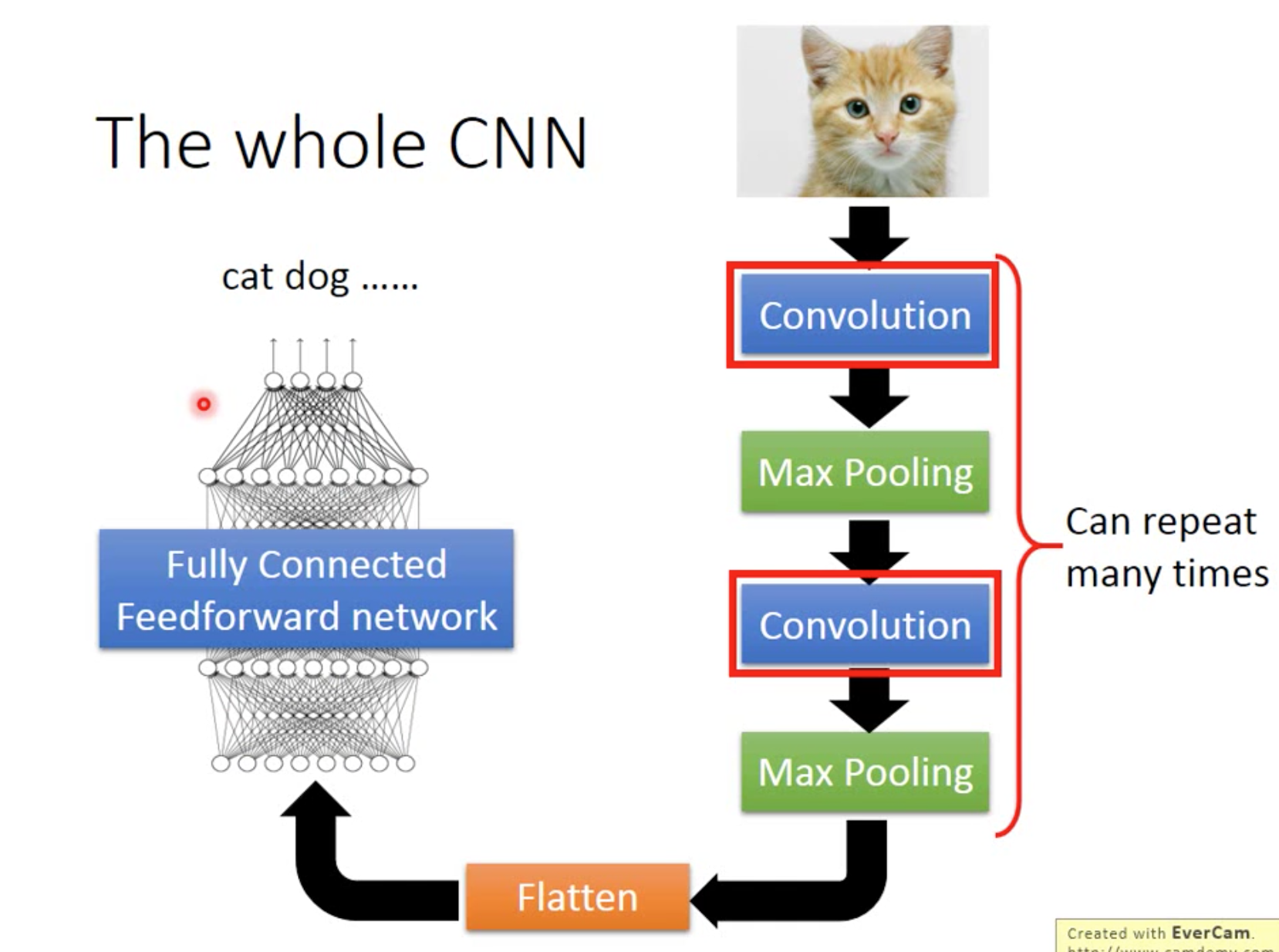
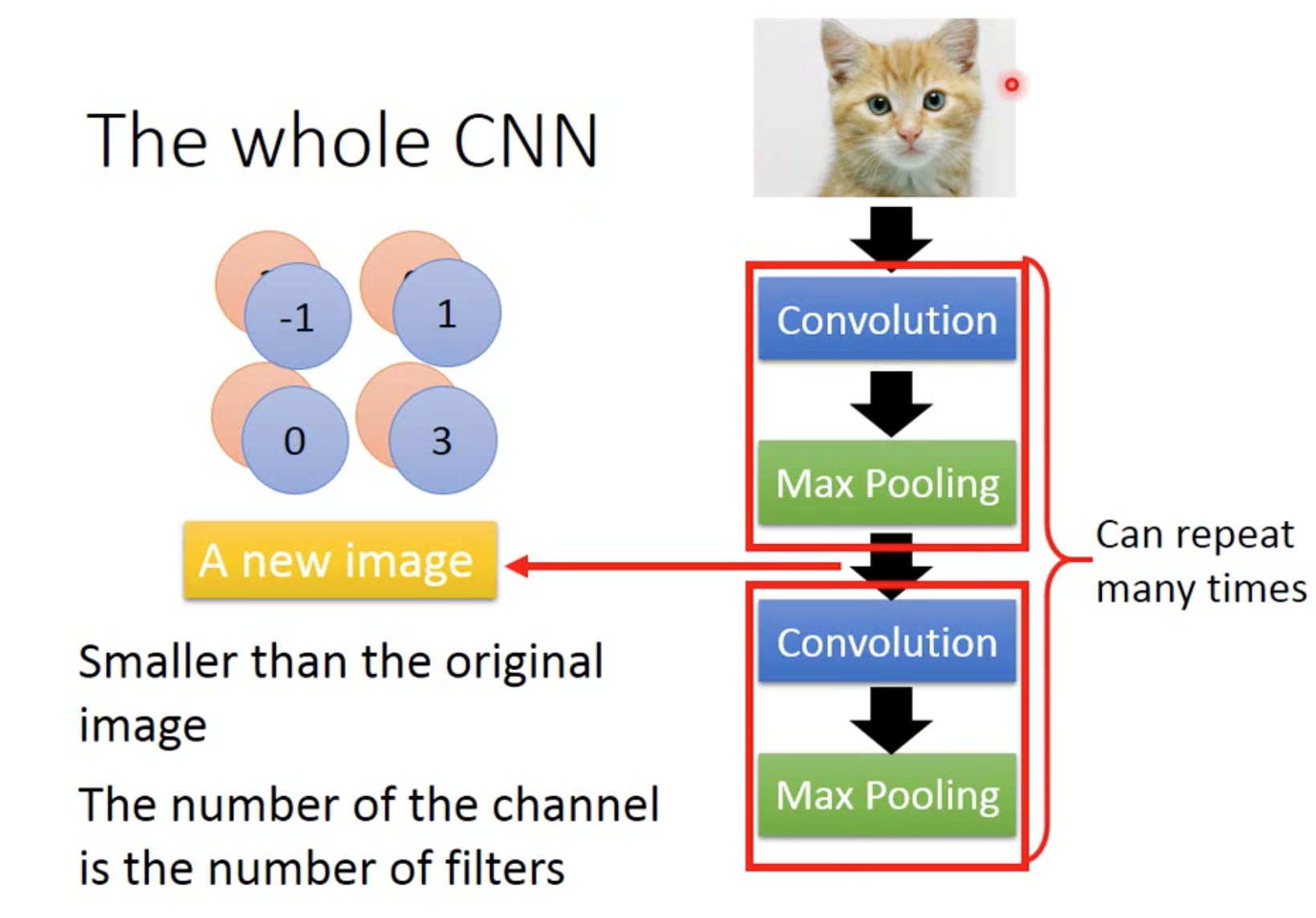
CNN大体结构可以分为convolution、max pooling和flatten,其中convolution和max pooling可以重复多次
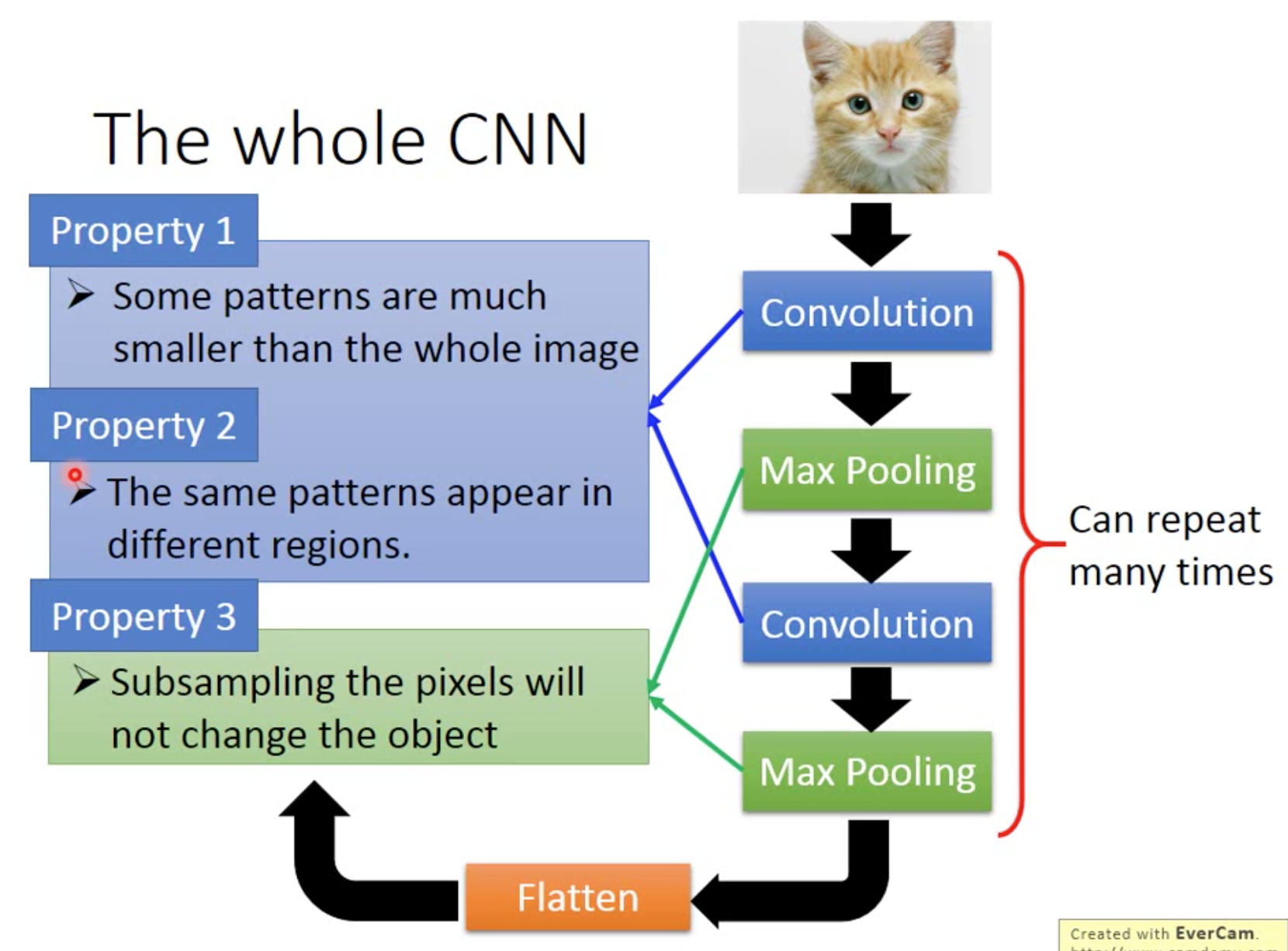
三个特点,前两个作用于convolution,第三个作用于max pooling
然后,介绍一下CNN的每个部分的原理
1、convolution
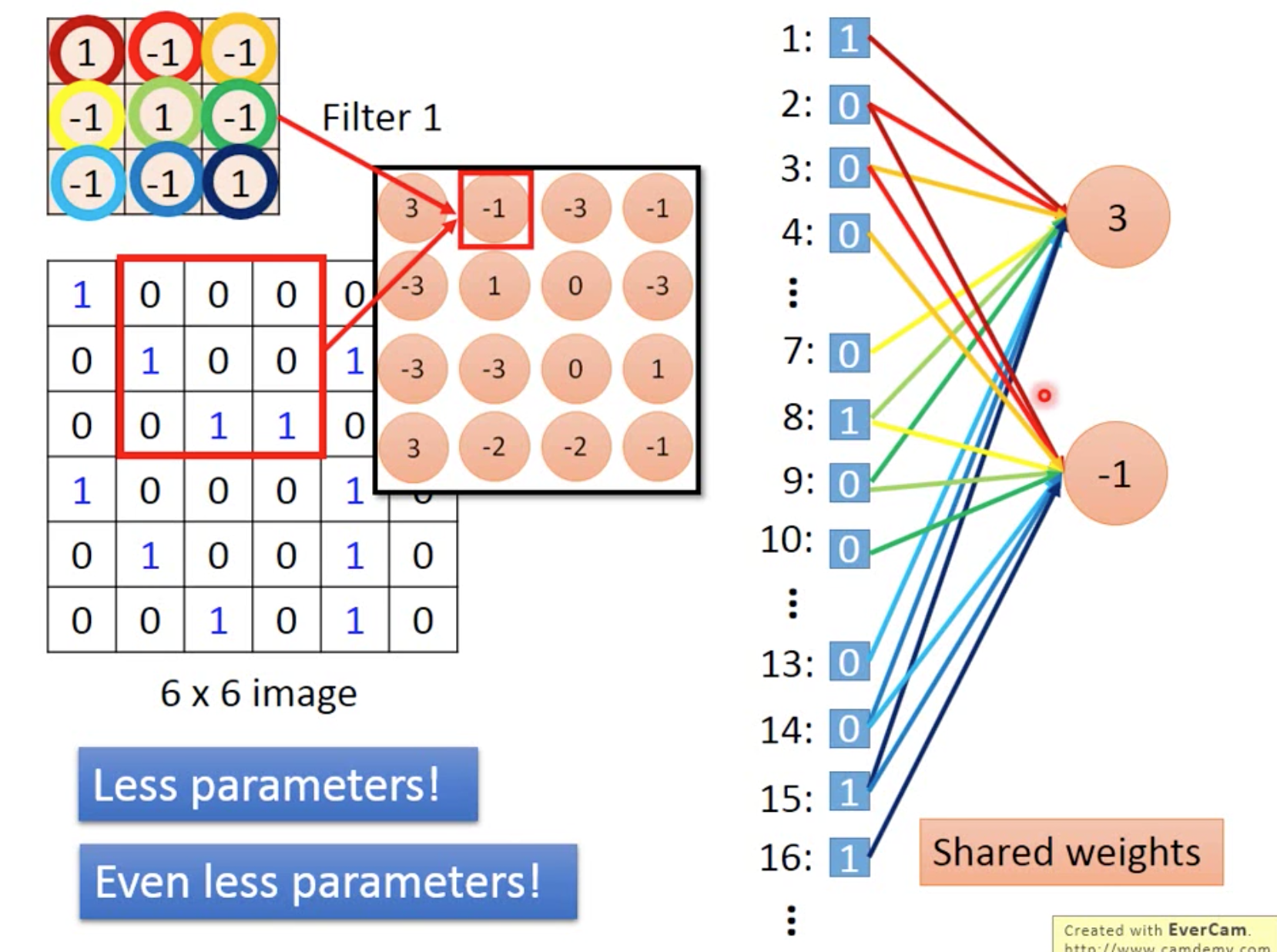
在这里我们使用2*2的filter,每个filter都是需要学习出来的,类似于netural,比实际的image所需参数小

filter从图片左上角开始计算,计算内积,每次转移距离要事先定好,如图stride=1,每次转移一个单位
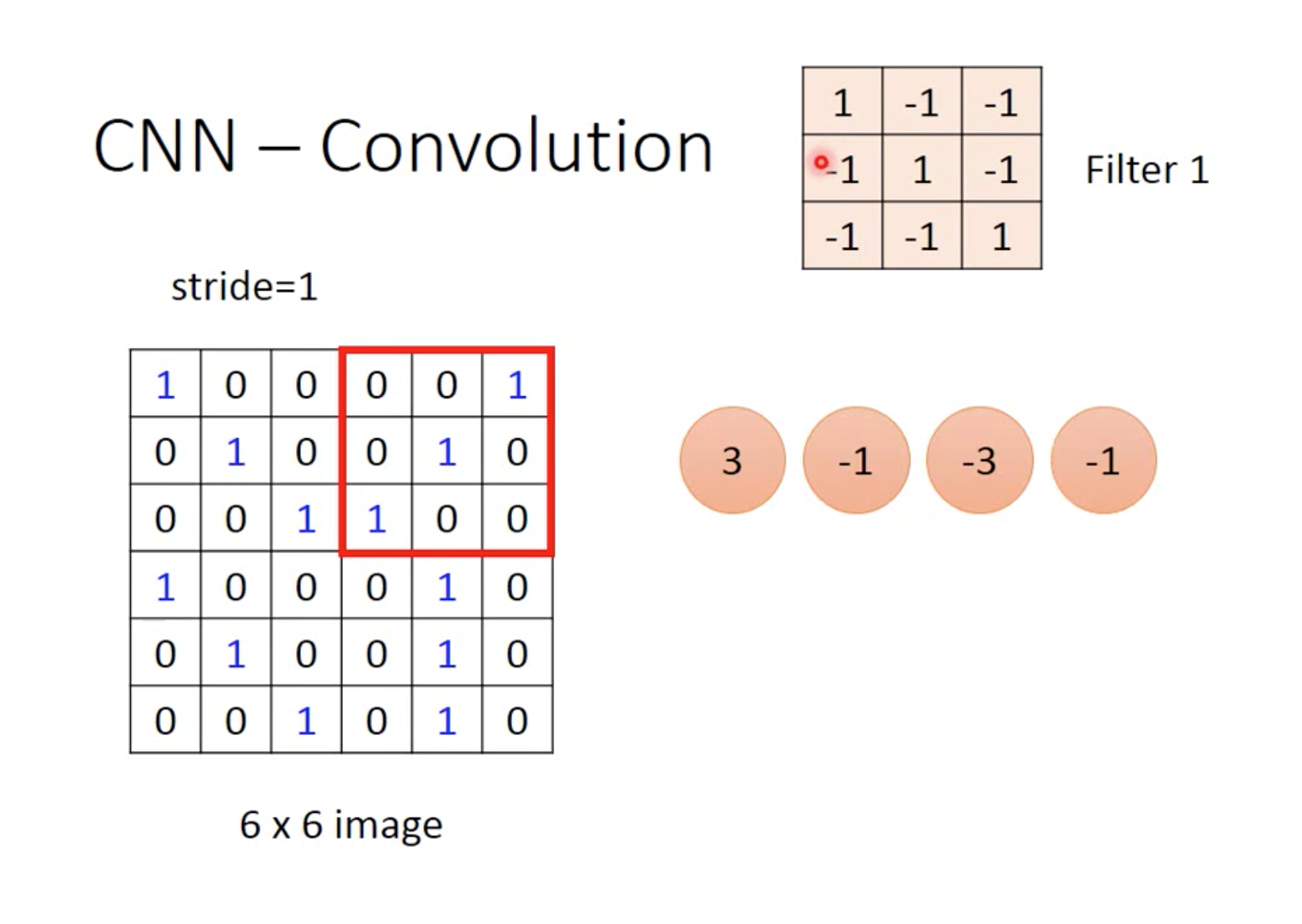
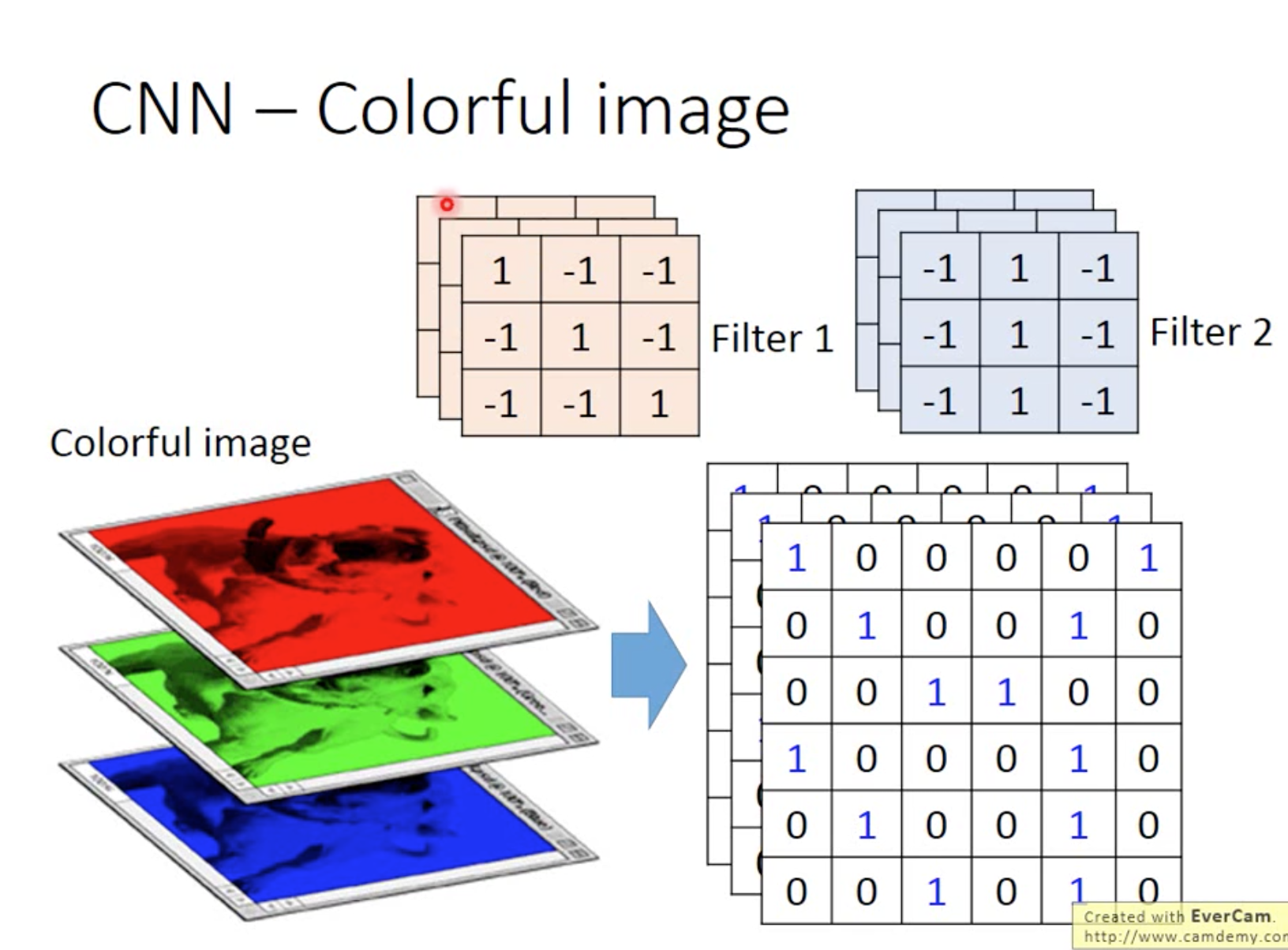
通过内积计算将6*6变为4*4,每个filter都可以将image转小,如图
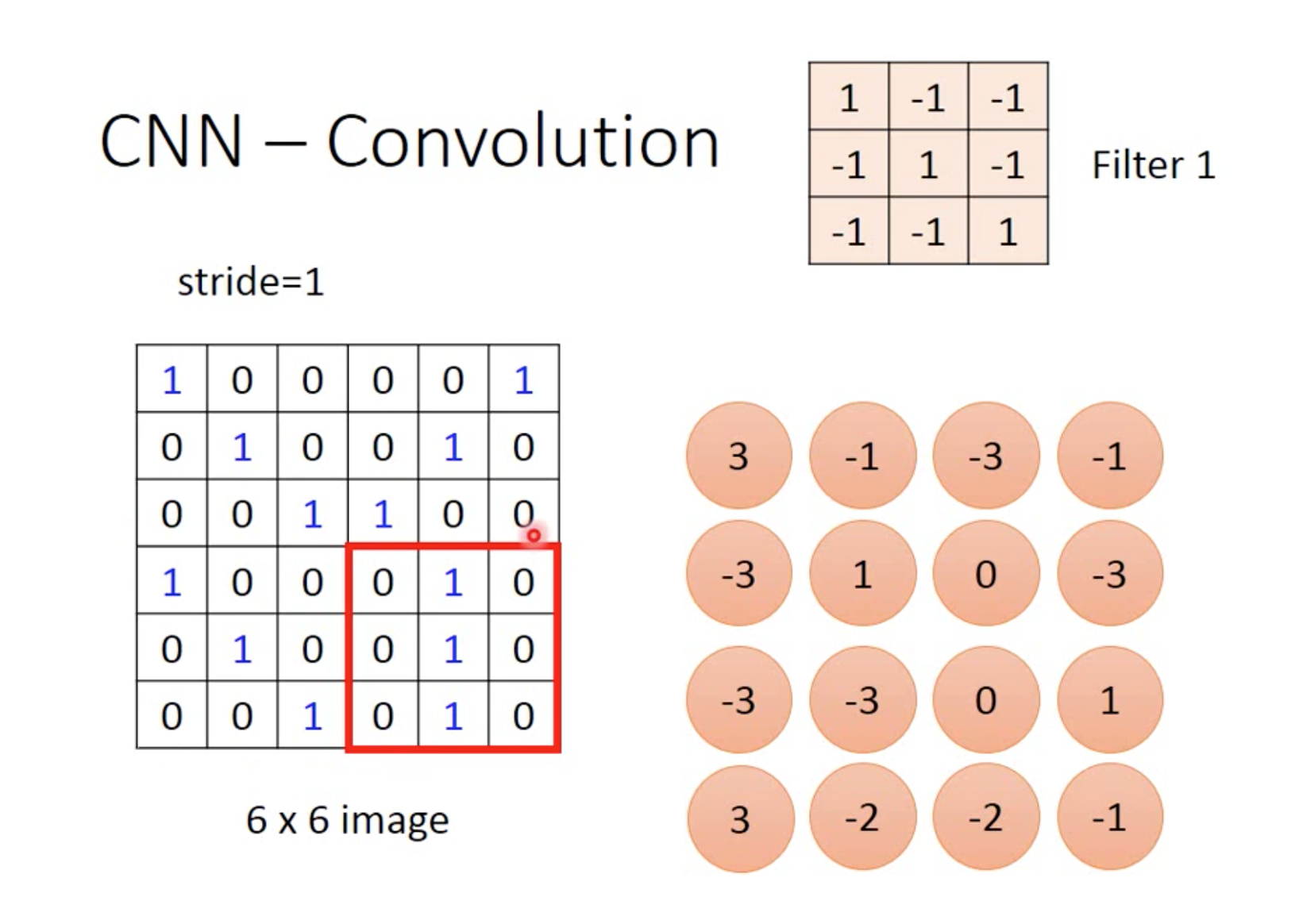
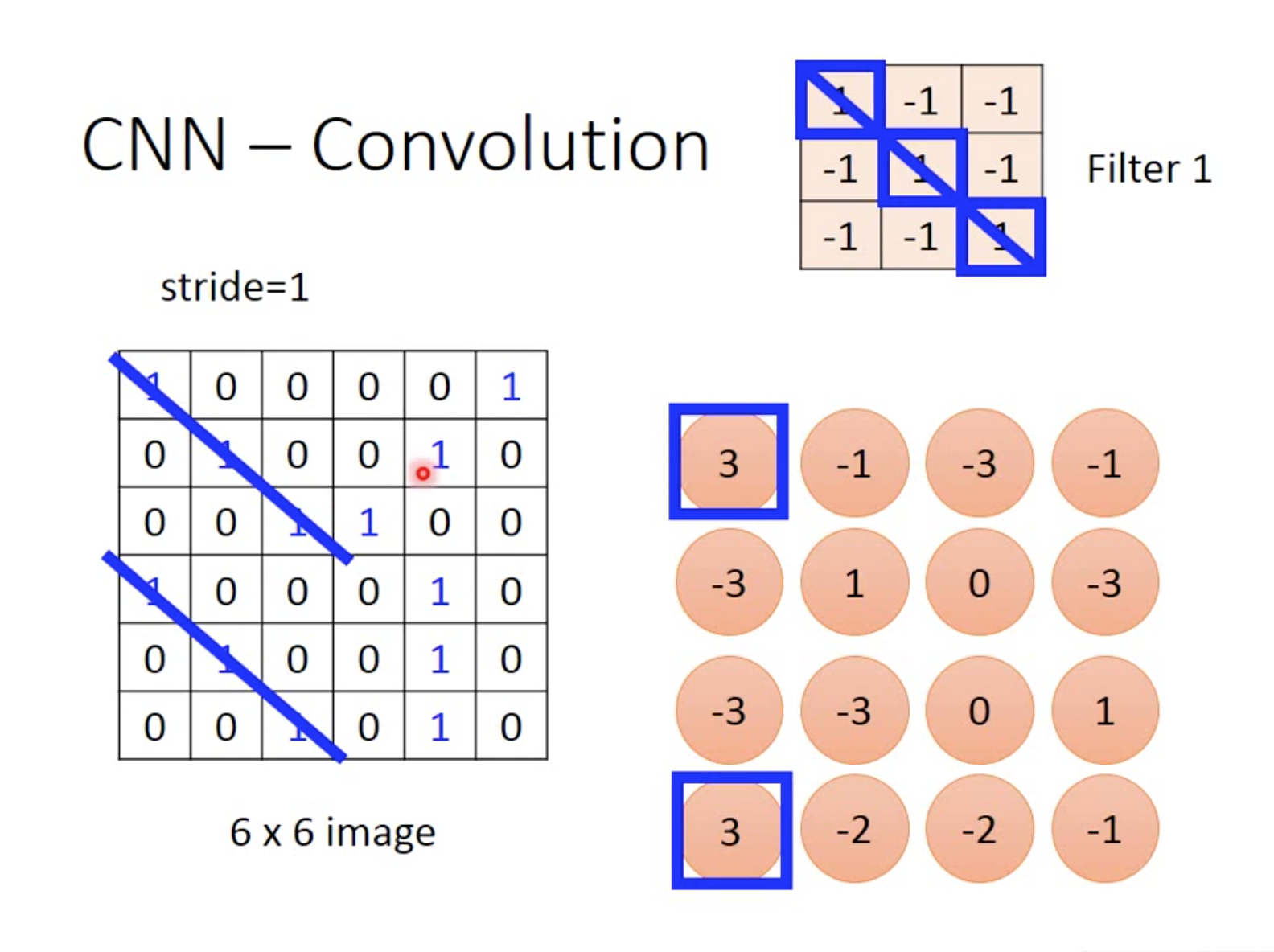
如图根据计算结果,说明filter 1在左上和坐下出现最大
对不同的filter做相同的步骤,如图

每个filter得出的结果4*4叫做feature map
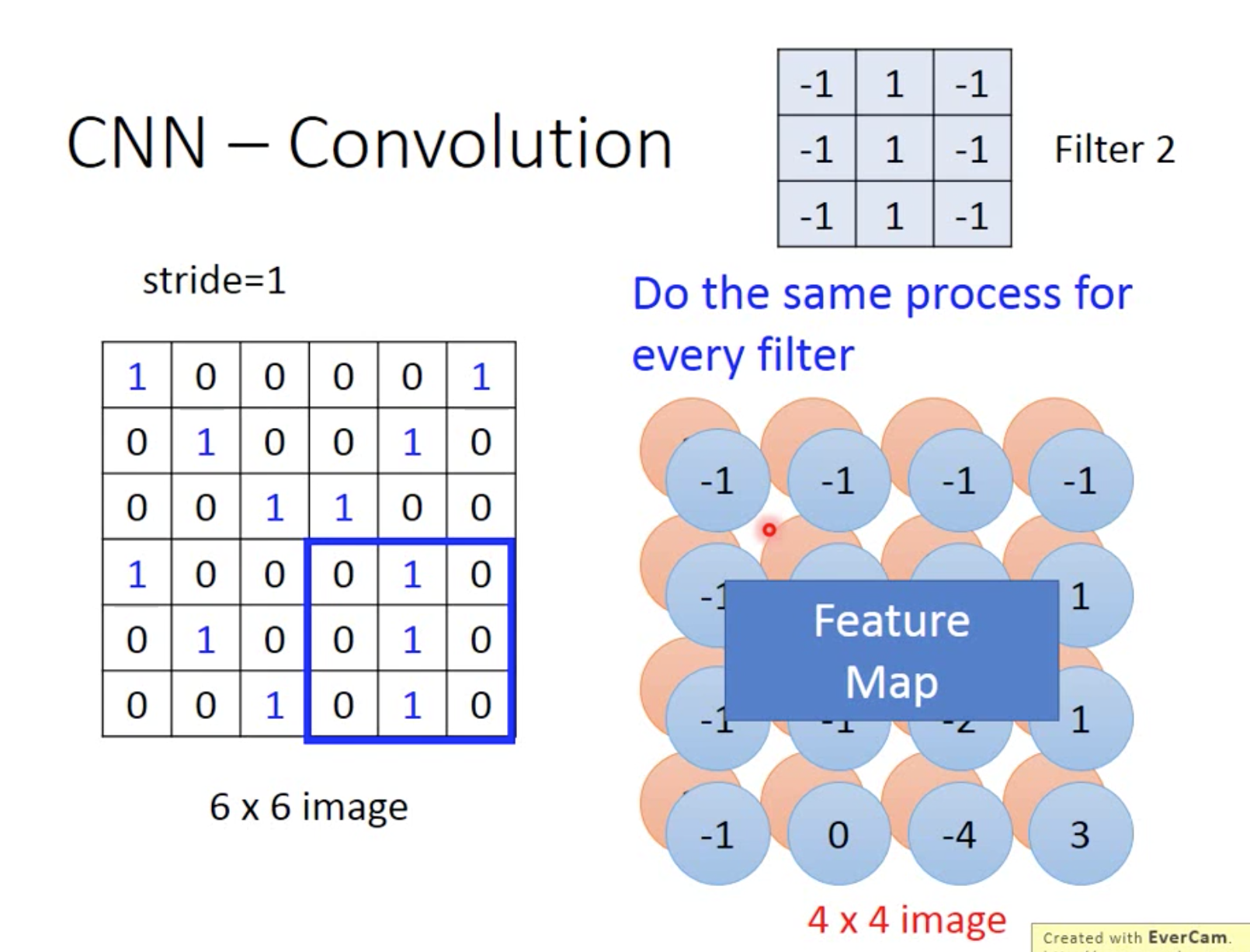
黑白即1、0,假如是彩色的,那就是RGB三值,这样image就变成深度为3的矩阵簇
convolution & fully connected

如图,convolution可以类似于fully connected计算

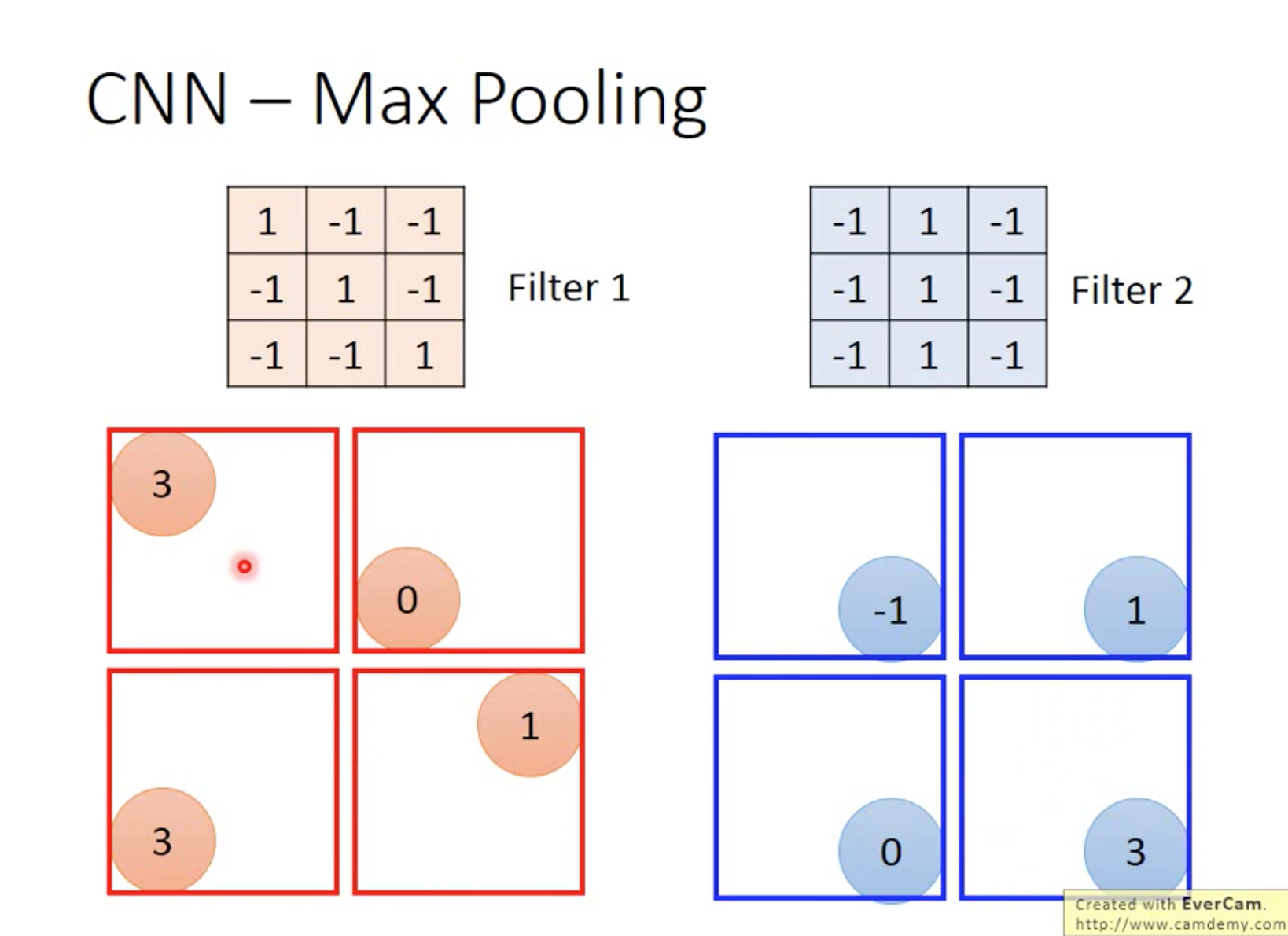
2、max pooling
将filter计算的结果缩小,即4*4的矩阵每4个里用最大的来代替,变成2*2
做完一次convolution和map pooling就是2*2矩阵,多少个filter即深度,这样image就减小

一次又一次进行convolution和max pooling,图片会越来越小
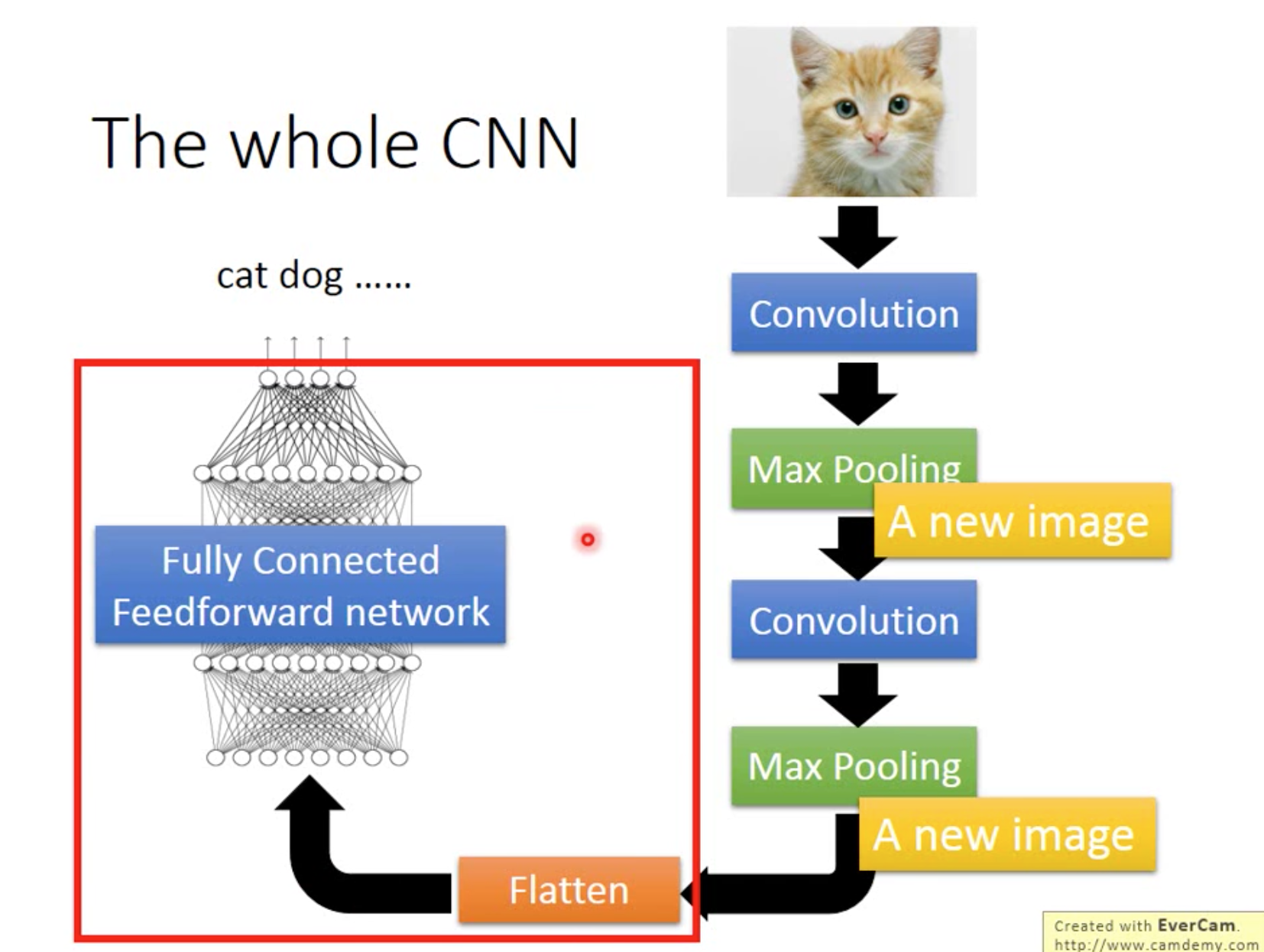
3、flatten

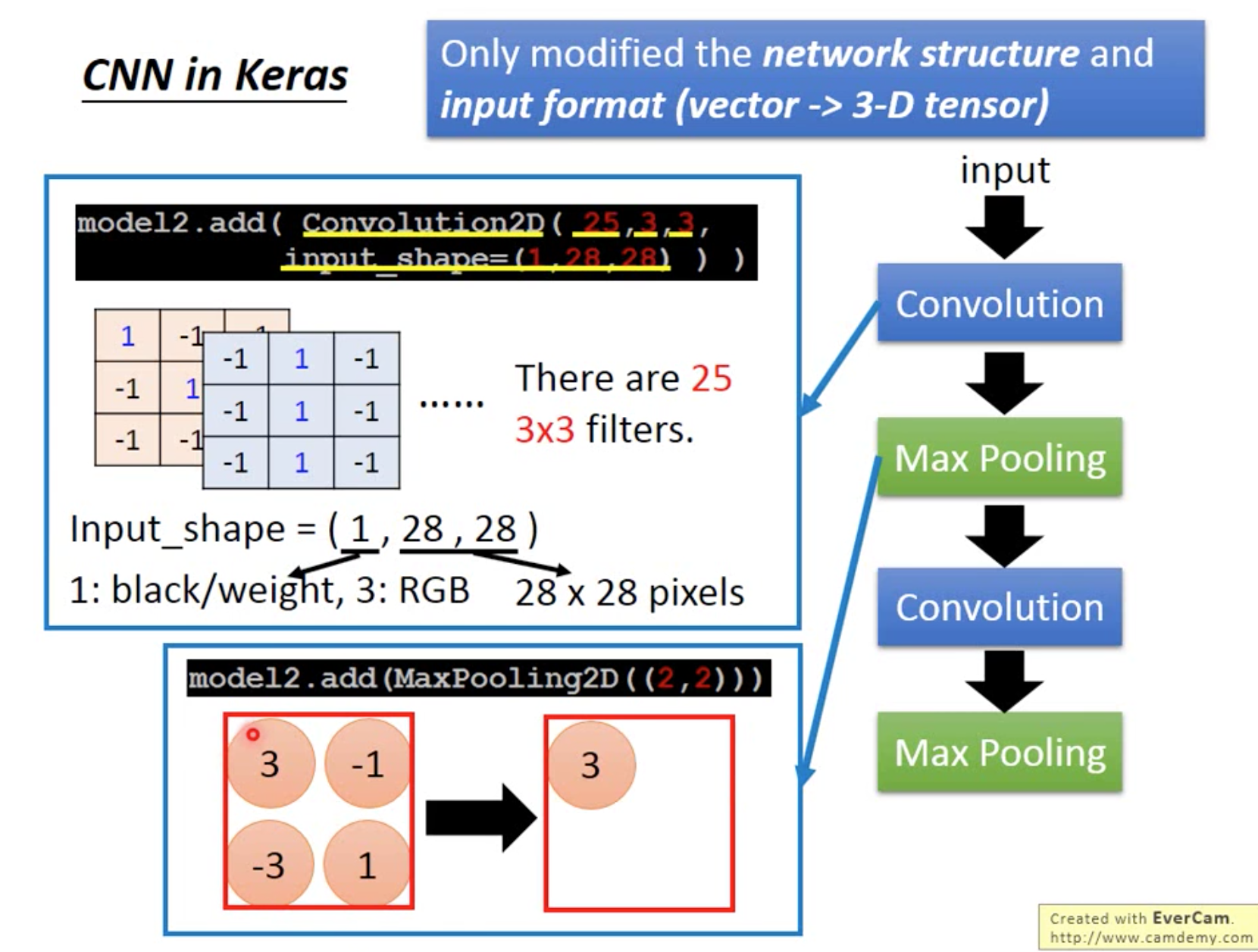
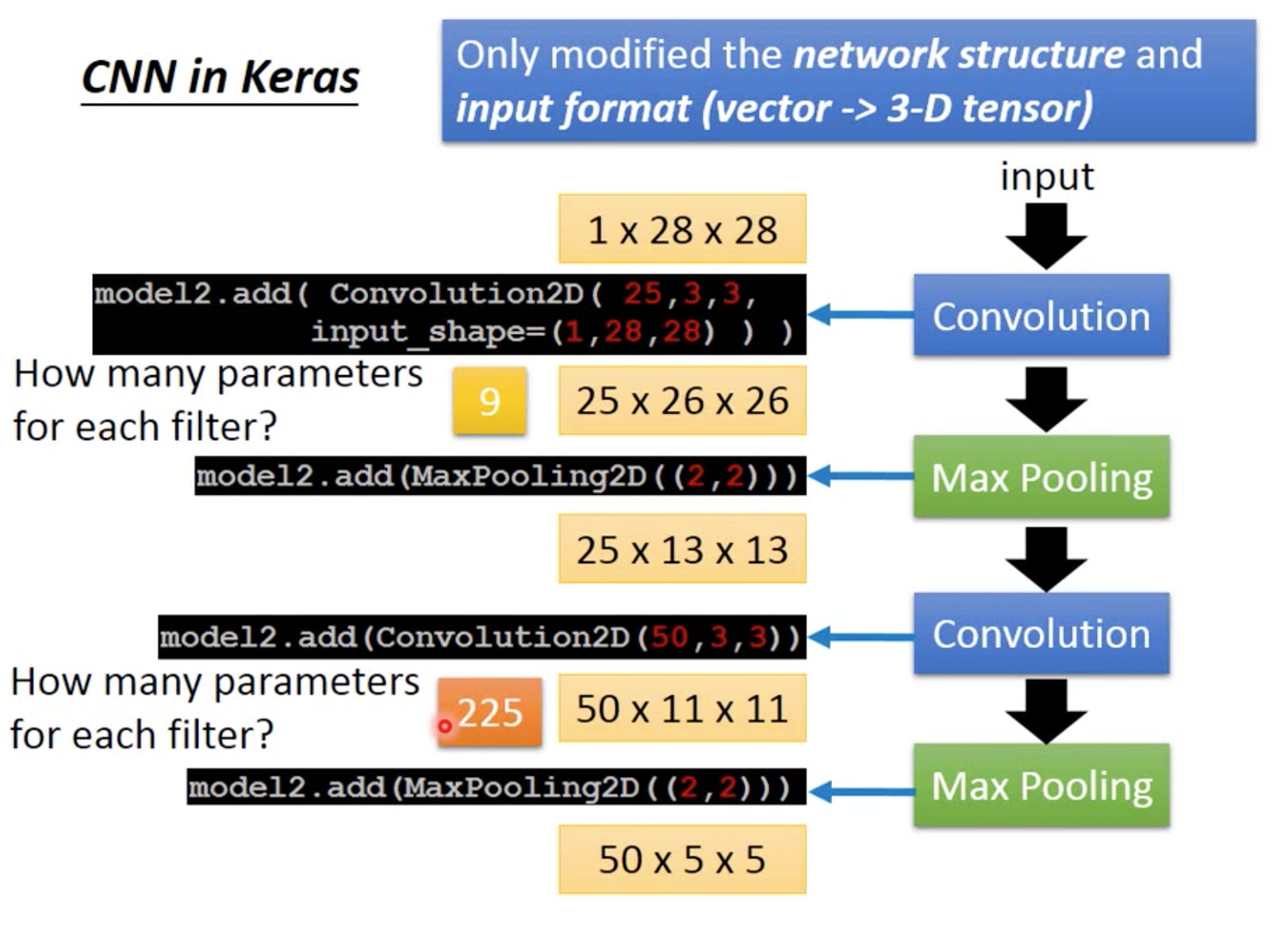
Keras应用

What does CNN learn?
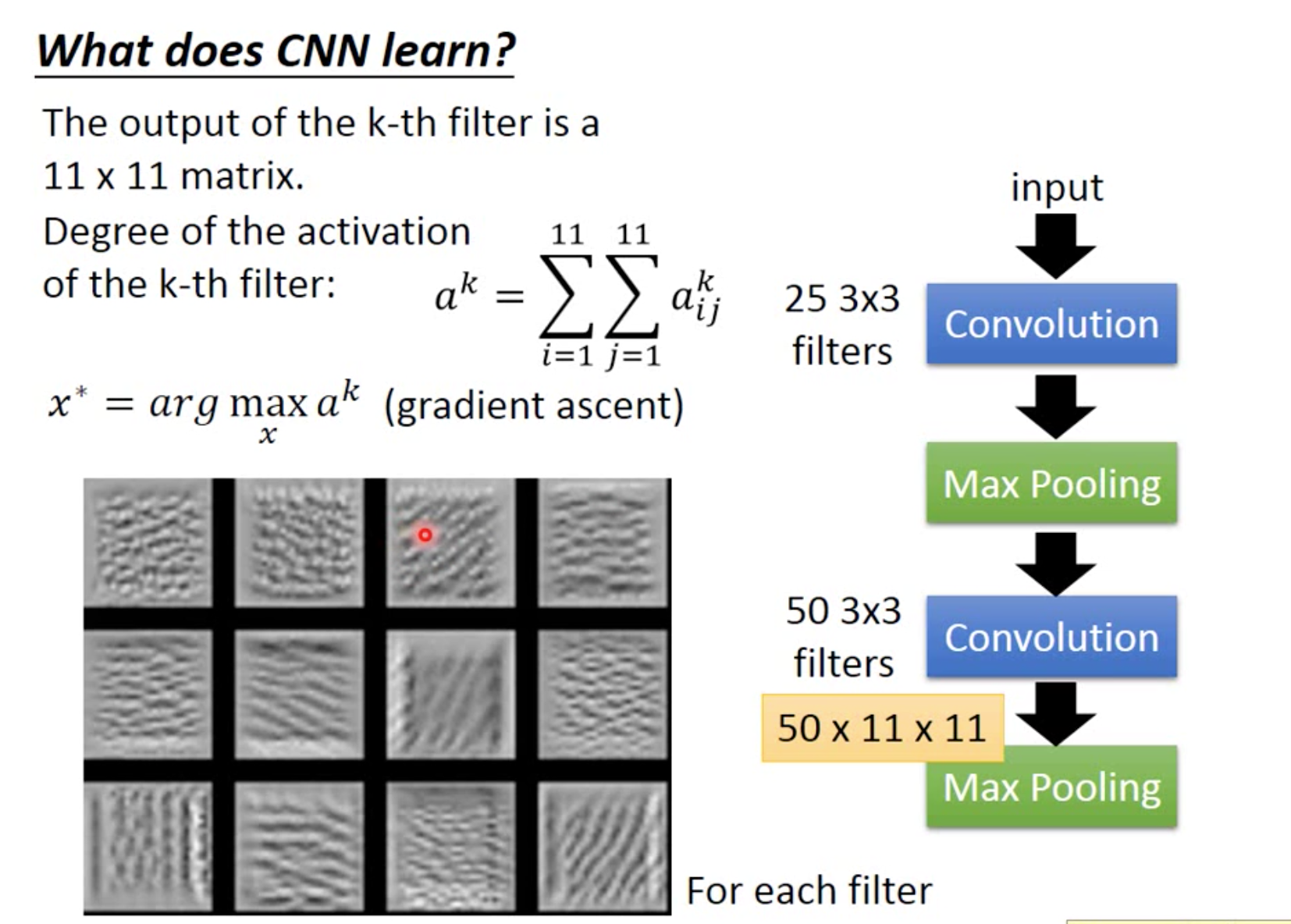
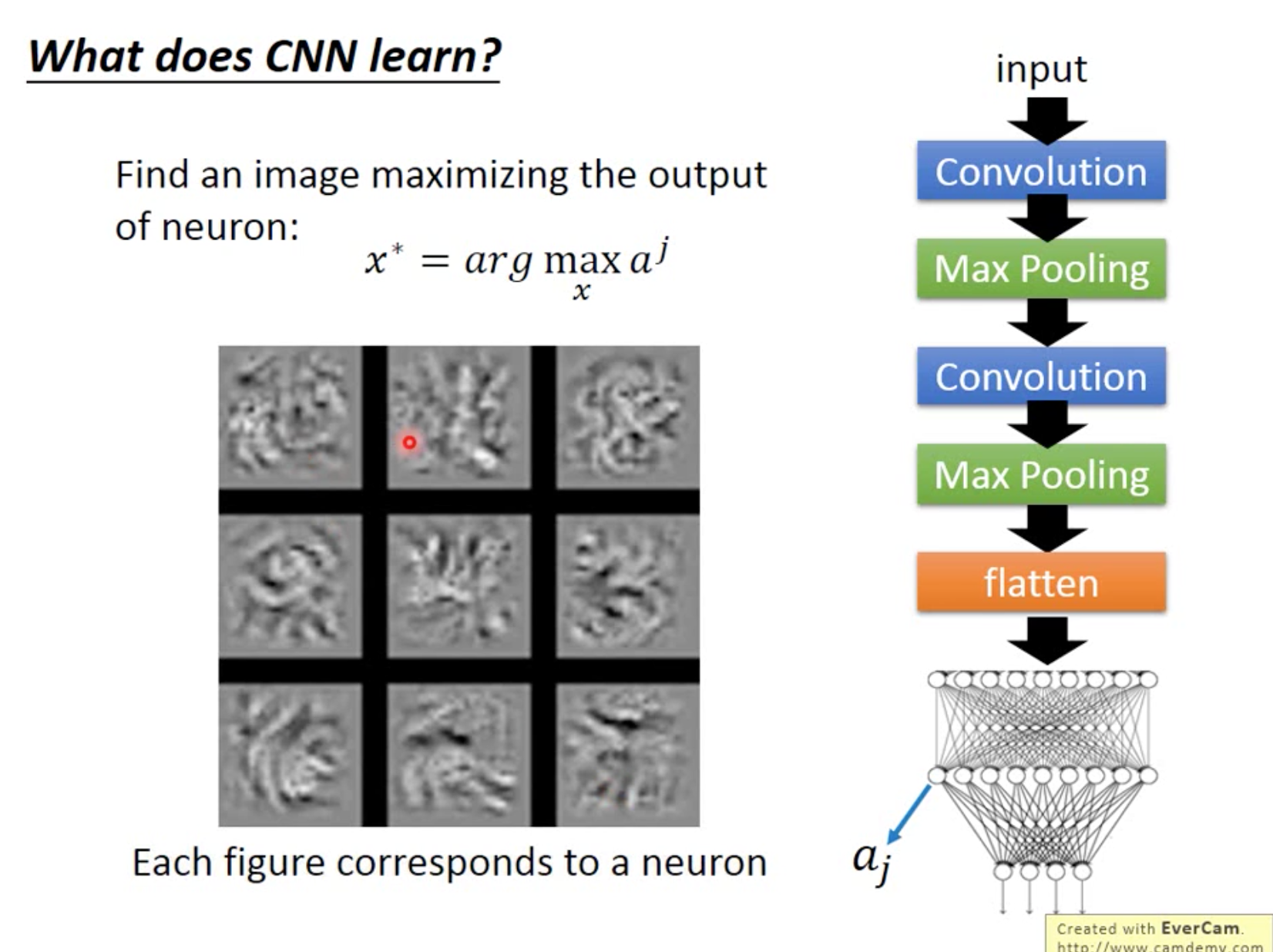
实际上与人类来说不太一样,就是说train与人类是非常不一样
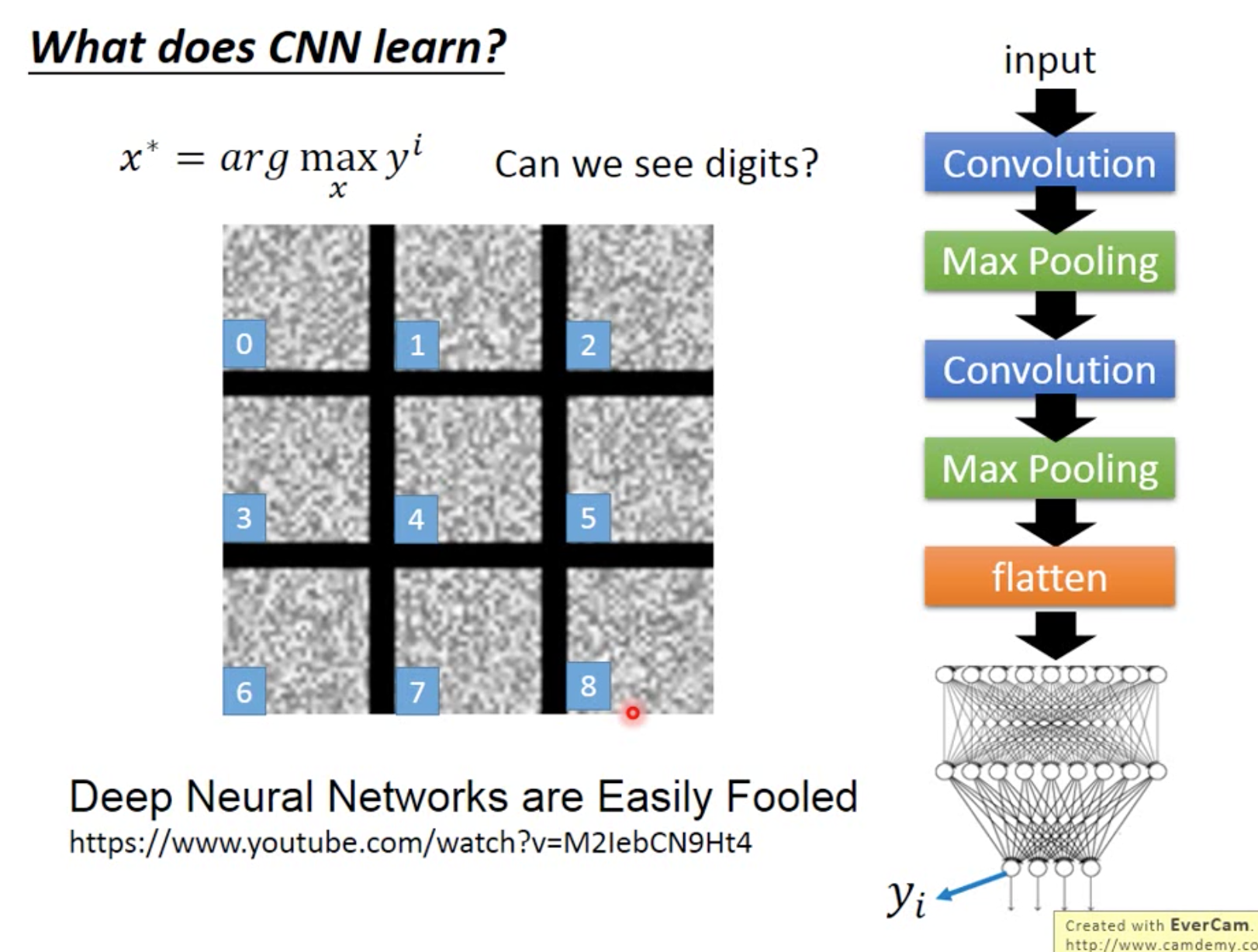
注意,右边式子的加好应该是减号

Deep Dream应用



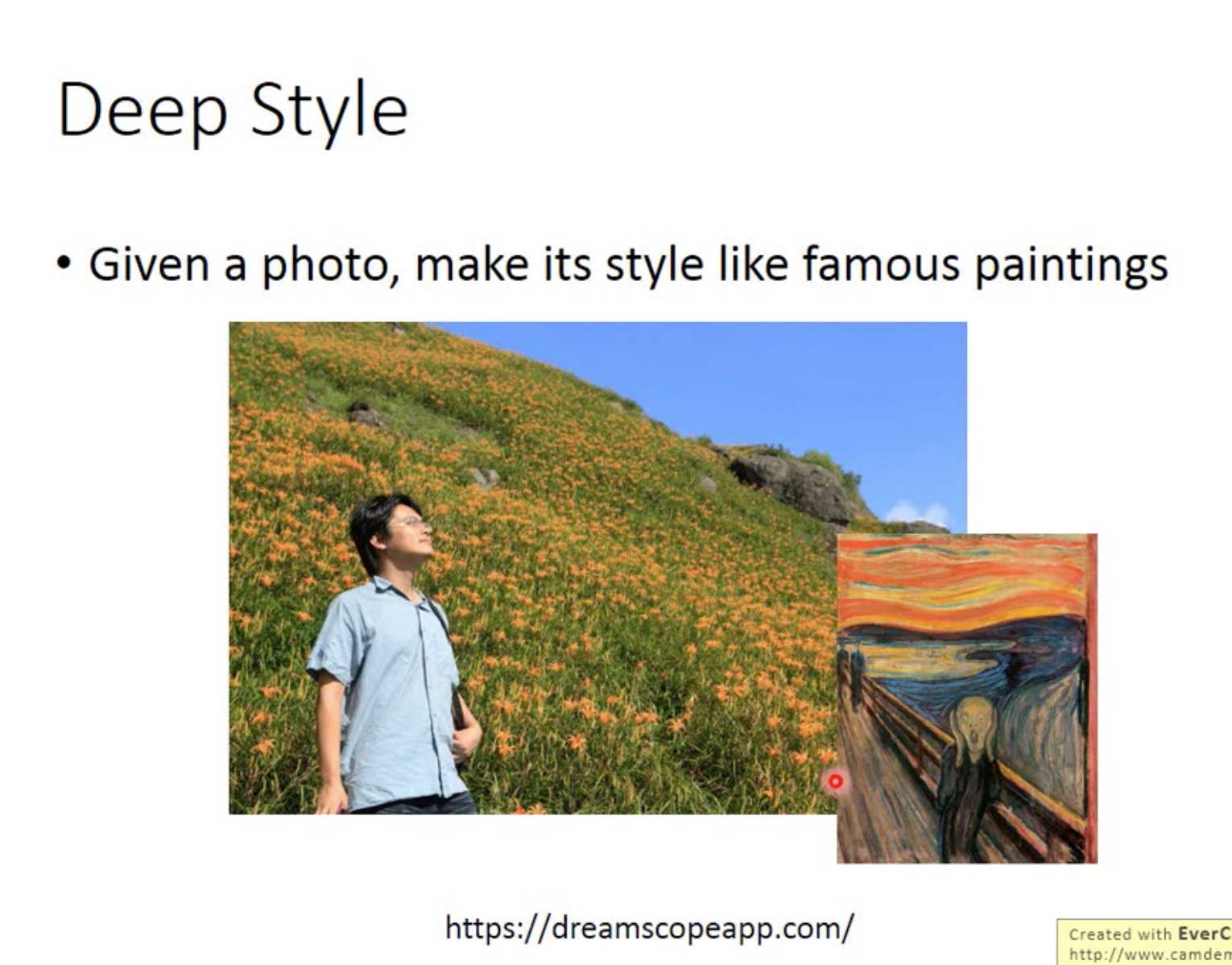
Deep Style

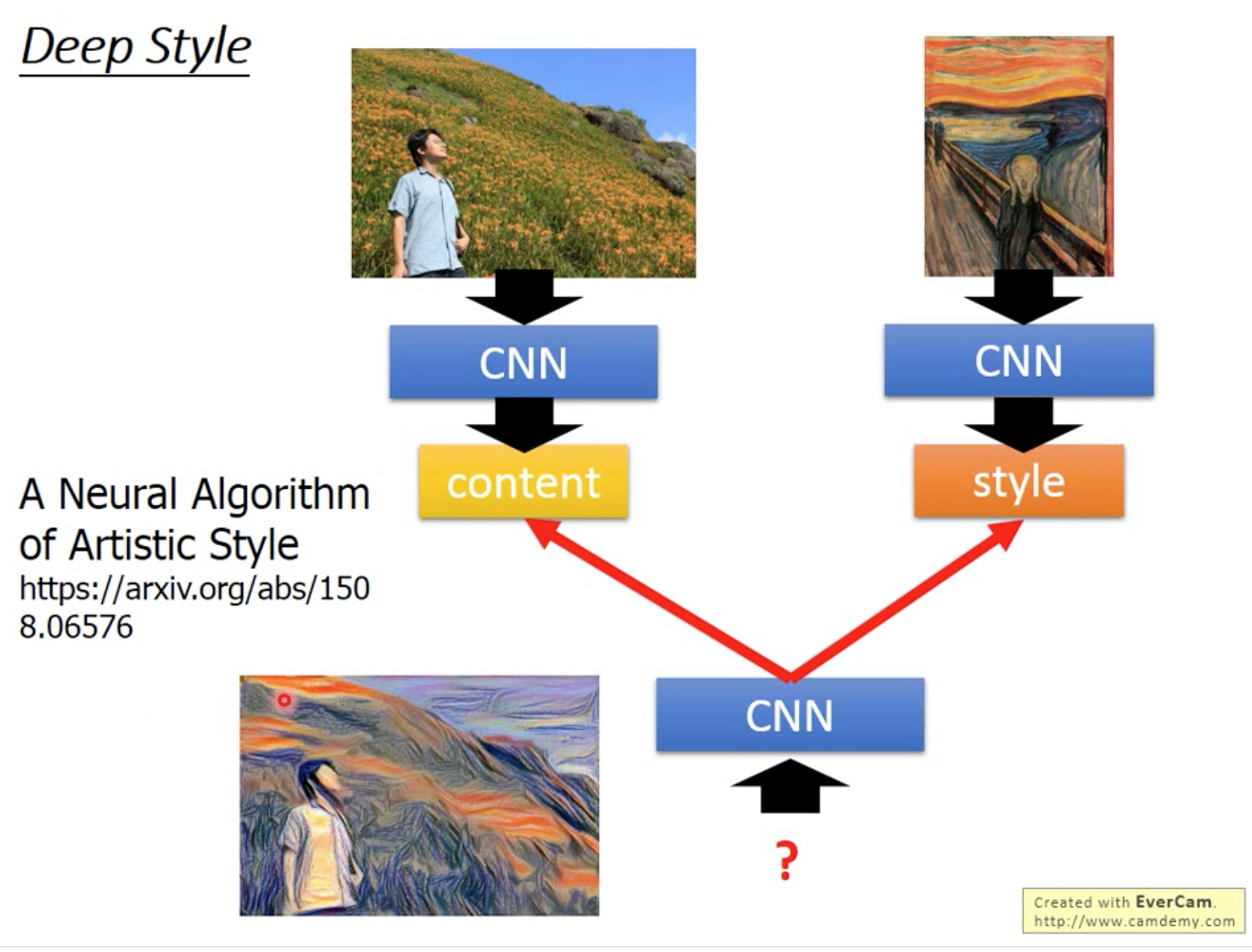
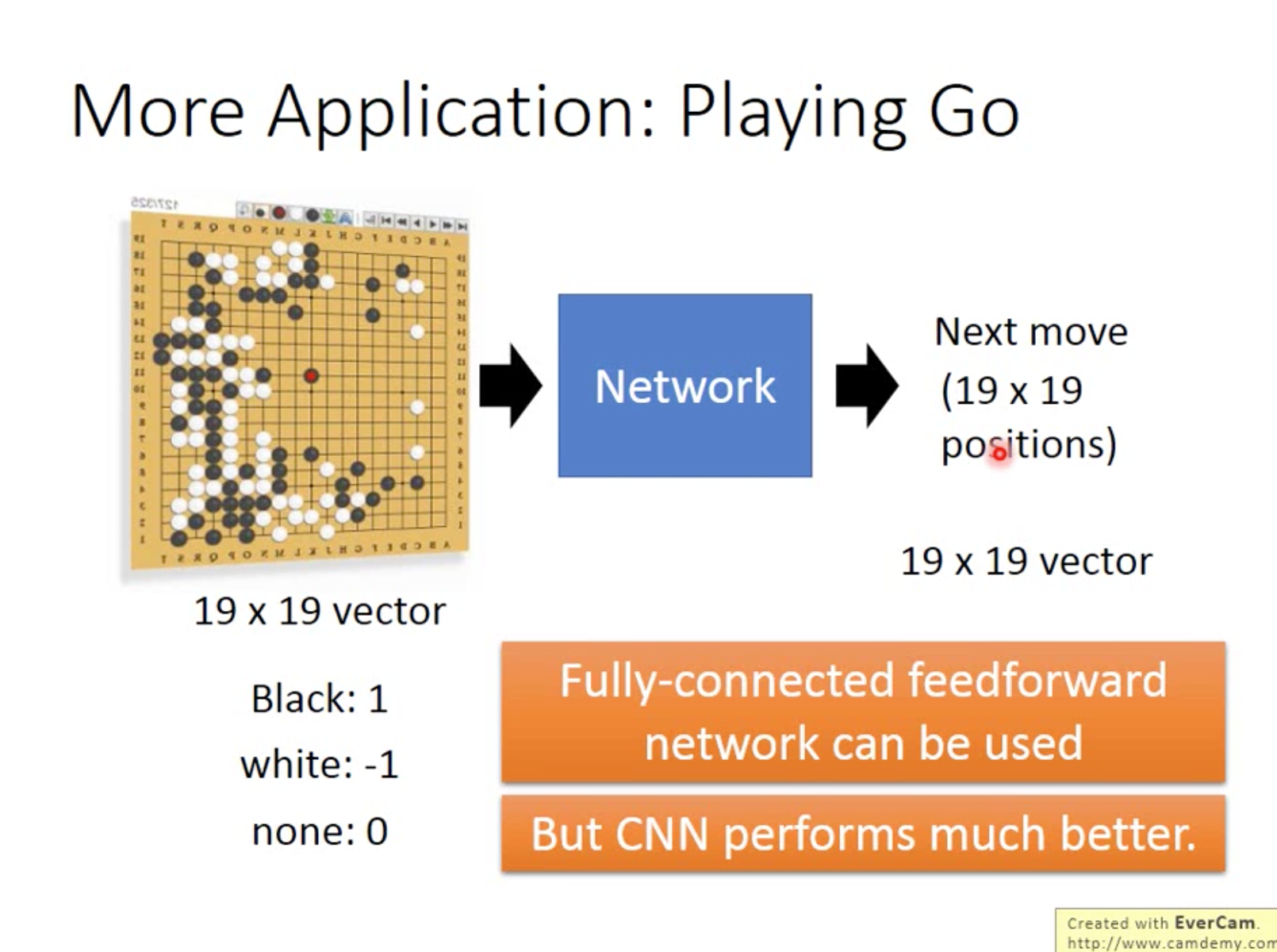
Playing Go




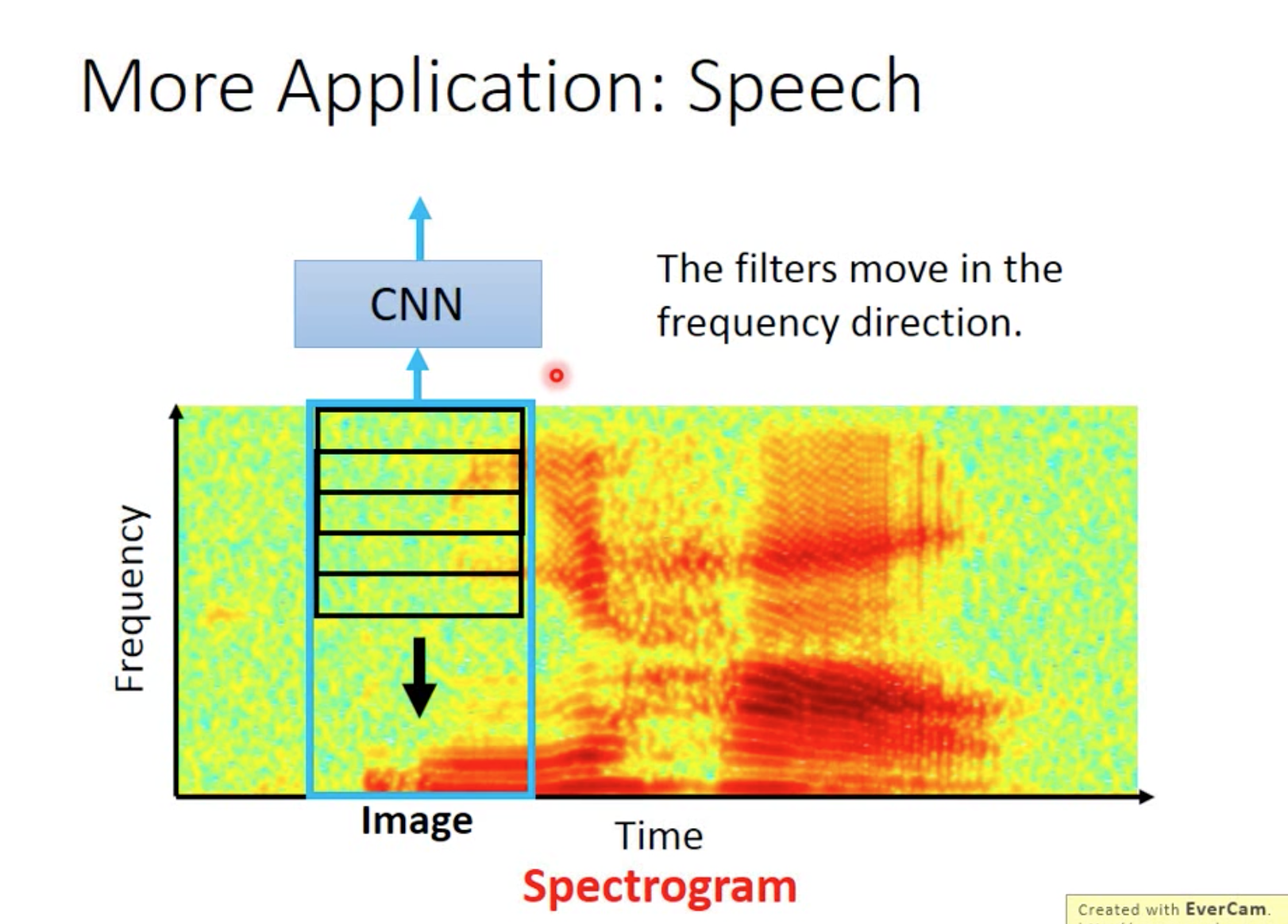
Speech
可以通过图片来知道这是一段什么样的声音