过度拟合
什么是过度拟合?
线性回归的过度拟合
在线性回归问题中,我们用了直线方程,二次方程,高次方程来拟合数据集,如图:
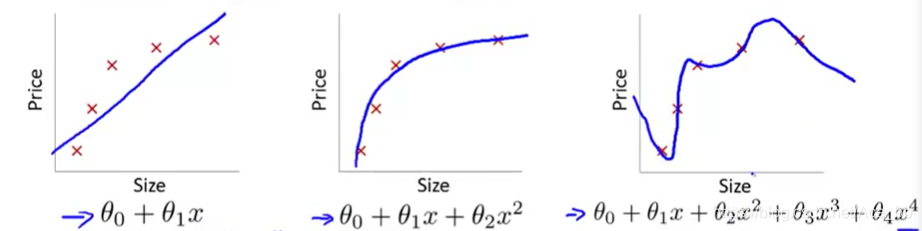
显然直线方程没有很好的拟合数据集,是欠拟合,存在着高误差,
二次方程 是一个很好的拟合模型。
高次方程虽然经过每一个数据样本,但曲线过于曲折,并不认为它是一个好的模型。 称为过拟合。另一个描述该问题的术语是:高方差
高方差: 我们用一个函数拟合数据样本时,这个函数能很好的拟合训练集,能够拟合几乎所有的训练数据,这就可能面临函数太过庞大的问题,变量过多,同时如果我们没有足够的数据去约束变量过多的模型,那么这就是过度拟合。
概括的讲,过度拟合在变量过多的时候发生,这时候训练出来的方程总能很好的拟合训练数据,所有你的代价函数,实际上可能非常接近于0,这样就导致方程无法泛化到新的数据样本中,以至于无法预测新样本的价格
泛化指的是一个假设模型能够引用到新样本的能力。
逻辑回归的过度拟合
以下面这个数据集样本为例:
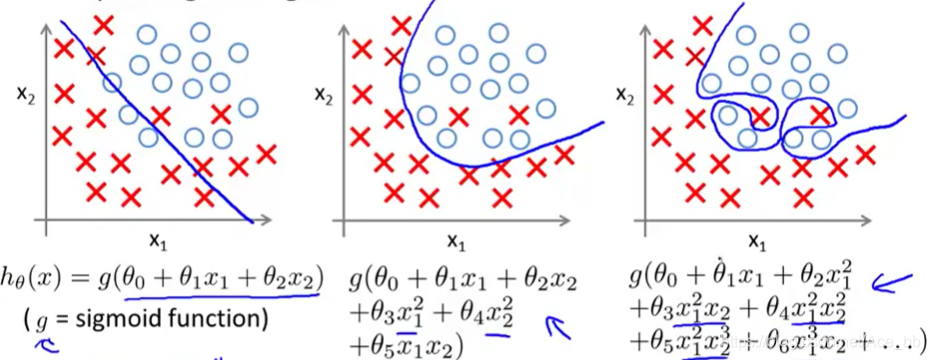
显然,用直线作为逻辑回归函数时同样存在欠拟合,假设模型存在高偏差。
图二中添加了二次项后正好能够很好的拟合数据集。
而添加更多的高此项后,拟合过度,函数模型自身曲线扭曲,并不能很好的预测新样本。即不能泛化到新样本。
如何解决过度拟合的问题:
可以通过绘画函数图形来绘制合适的多项式阶次。但当有很多个变量的时候,画函数图形并不是很好的方法。
第一个办法是尽量减少选取变量的数量,具体而言,我们可以人工检查变量的条目,并以此决定哪些变量更为重要,然后决定哪些变量应该保留,哪些应该舍弃。
第二个方法计算正则化。正则化中将保留所有的特征变量。但是我们将减少数量级或参数数值的大小。这是一个很好的方法,因为每一个变量我们都使用到了。
————————————————————
