什么是正则化?
举例说明
如下数据集,两个函数模型的拟合曲线如图:

显然,当阶次较高时,可以很好的拟合数据,但是一般性不好,过度拟合了数据。
下面是在之前的线性回归方程中假设的代价函数:
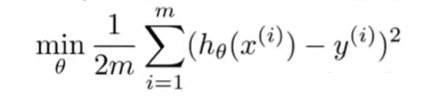
选择增加两个惩罚项来尽量减少θ3和θ4的值。
代价函数就是我们优化的目标,我们要尽量减少代价函数的均方误差
对代价函数增加如下两项:
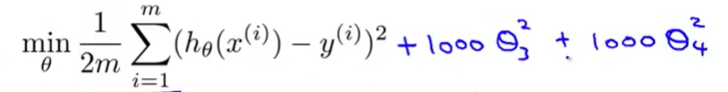
为了使这个新代价函数最小化,我们要让θ3和θ4尽量小。 实现最小化后θ3和θ4的值接近于0,此时就相当于x三次方和x四次方项几乎被忽略。这样假设函数的图像就会变得更加光滑,更少曲折,也能够更泛化的预测新数据样本。就如这个例子中的二次函数拟合数据集一样。
正则化运作思路
当θ值比较小时,可以得到形式更简单的假设函数,函数图像也会更光滑,就不易发生过拟合问题。
当一个案例中 的变量非常多时,我们并不能直观的知道我们该保留哪些变量,舍弃哪些变量来使我们的函数能够更好的拟合数据集。
为了选择参数,减少参数的数目,所以在正则化问题是我们要修改线性回归的代价函数。 修改后的代价函数如下:

最右边的求和项就是正则项,朗达是正则化参数。
我们的第一个目标就是能够更好的拟合数据集,第二个目标就是想要保持参数值较小。而朗达就是要保持这两个目标之间的平衡,使假设函数的形式更加简单。
朗达值一般是设定为非常大的数。
————————————————————
