同事在用hdfs api 写入hdfs文件,2年前没有成功,这次一起解决了这个问题。详细代码如下:
客户端需要指定ns名称,节点配置,ConfiguredFailoverProxyProvider等信息。
代码示例:
package cn.itacst.hadoop.hdfs;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HDFS_HA {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://ns1");
conf.set("dfs.nameservices", "ns1");
conf.set("dfs.ha.namenodes.ns1", "nn1,nn2");
conf.set("dfs.namenode.rpc-address.ns1.nn1", "hdfsname01:9000");
conf.set("dfs.namenode.rpc-address.ns1.nn2", "hdfsname02:9000");
//conf.setBoolean(name, value);
conf.set("dfs.client.failover.proxy.provider.ns1", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
FileSystem fs = FileSystem.get(new URI("hdfs://ns1"), conf, "hadoop");
InputStream in =new FileInputStream("c://test.rar");
OutputStream out = fs.create(new Path("/test"));
IOUtils.copyBytes(in, out, 4096, true);
}
}下面是调用api 官网说明
static FileSystem |
get(URI uri, Configuration conf, String user) Get a filesystem instance based on the uri, the passed configuration and the user |
网址:http://hadoop.apache.org/docs/r2.4.1/api/org/apache/hadoop/fs/FileSystem.html
喜欢追踪原来的朋友可以看第二部分。
二。原理解析
跟踪进入FileSystem
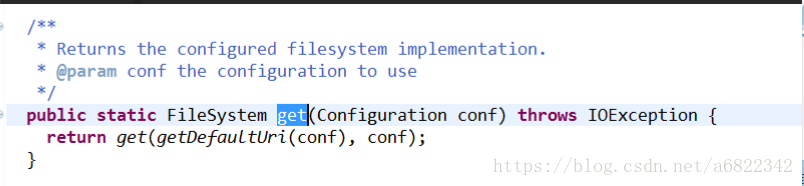
通过getDefaultUri(conf)获得前面代码中设置的主机的uri地址,然后再调用重载的get方法。
以下是重载的get方法内容:
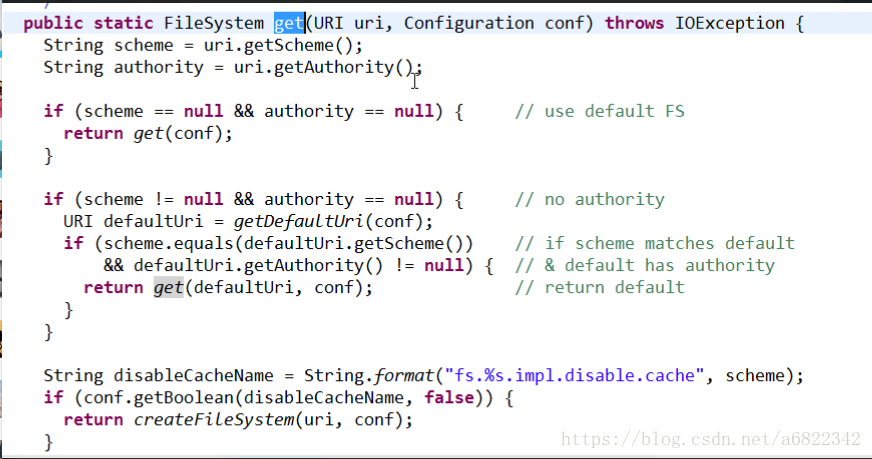
①getScheme() scheme的值是hdfs,getAuthority是获得namenode的主机名和端口号。
如果scheme==null 以及authority==null 就返回default fs也就是本地文件系统。
②然后拼接disableCacheName,将scheme拼接进去,拼接为fs.hdfs.impl.disable.cache。然后从conf里面区get该参数值,如果有值就返回,如果没值就返回false。该参数的意思是禁用缓存,禁用缓存为false就意味着要用缓存,然后走到下面的程序。CACHE.get(uri,conf).
到这里,filesystem的get方法什么也没做,搞了一堆判断。然后返回的CACHE.get(uri,conf).
我们下面看一下CACHE.get干了什么。
③CACHE是filesystem的内部类

获得了key(uri和用户名串联起来)
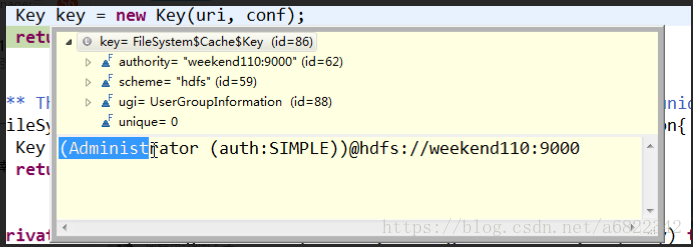
这里的get也没拿到实际的文件对象,返回了getInternal(uri,conf,key)。
下面是getInternal的方法
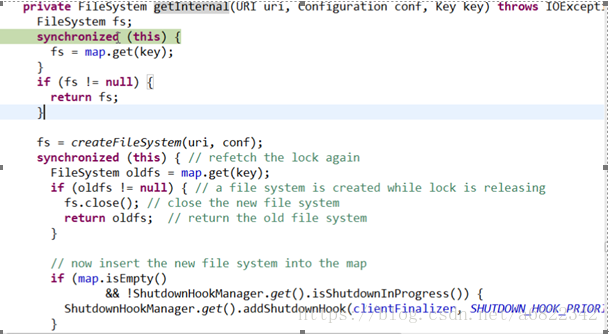
一开始map是空的,然后可能这次处理完之后,就可以把文件系统对象暂时存进去(不同的用户访问集群的时候,都可以把他的文件系统实例放进去,对于一个具体的用户来说,你永远拿到的是同一个对象,对于每一个用户来说相当于单例模式。),做一个缓存作用,万一后面还有下载文件之类的操作,就可以直接从map里面取了。
Fs=null后,就create一个fs对象。具体代码:fs=createFileSystem(uri,conf).
④进入createFileSystem方法。

首先去拿一个class的文件,根据uri.getScheme和conf来得到这个class,然后进行反射得到fs实例对象。
下面是getFileSystemClass代码:
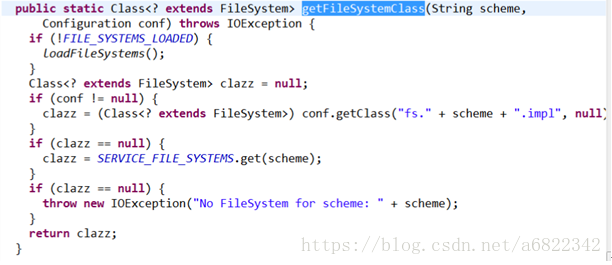
此时scheme的值是hdfs,然后conf.getClass(“fs.hdfs.impl”)去获得class,如果conf里面没有这个配置,那么就返回null。

拿到了就返回clazz。
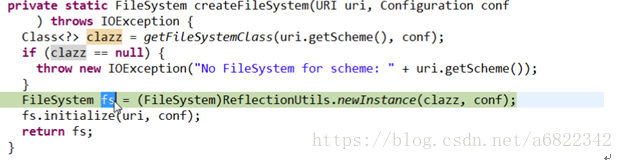
拿到了clazz,然后就通过ReflectionUtils反射出fs。Fs里面有个成员DFS,然后通过反射拿到的成员都是空的。
然后进行初始化操作,fs.initialize(uri,Conf)
调用的是filesystem的实现类distributedFileSystem的initialize方法
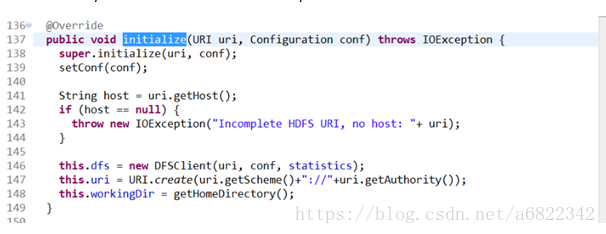
这里面分别是对成员赋值。
Dfs是客户端,到目前为止,fs持有dfs对象,但是我们目的是要看到一个rpc的对象,所以这个dfs对象里面应该是持有一个rpc客户端对象。
下面看看new DFSClient()构造方法。

然后调用一个四个参数的构造函数

然后看看这个DFSClient中的成员对象:
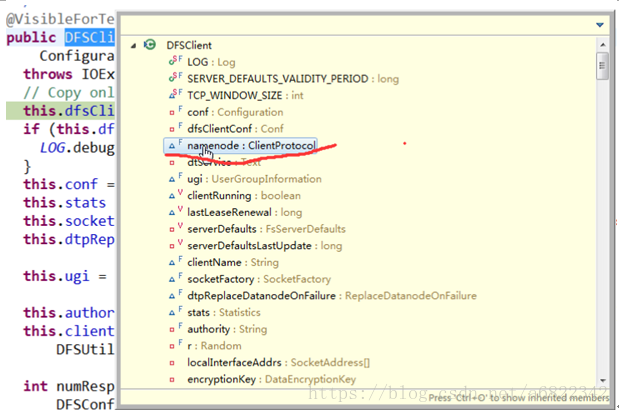
有一个namenode的ClientProtocol,这个成员就是客户端和服务端需要共同实现的动态代理对象,它这个是调用真实的namenode的业务方法,所以直接取名为namenode。
在代码中进行一系列赋值和判断之后,主要代码如下:
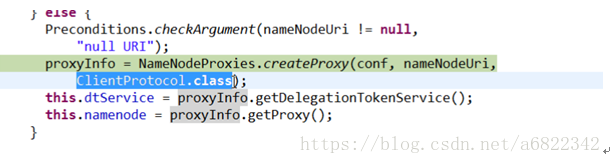
然后通过动态代理和反射技术获得proxyinfo对象
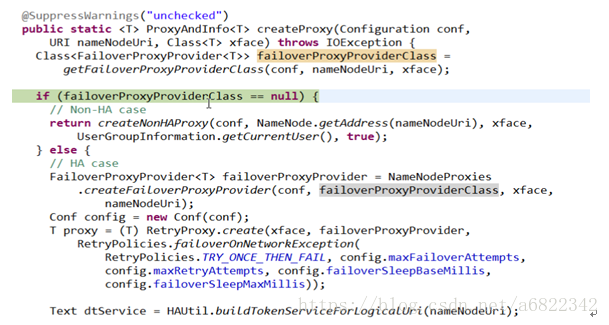
这个failoverProxyProviderClass是针对ha机制的,如果配置了就会走else部分程序,如果没有就return 一个非ha的通信代理对象。然后我们看看createNonHAProxy方法里面干了什么。
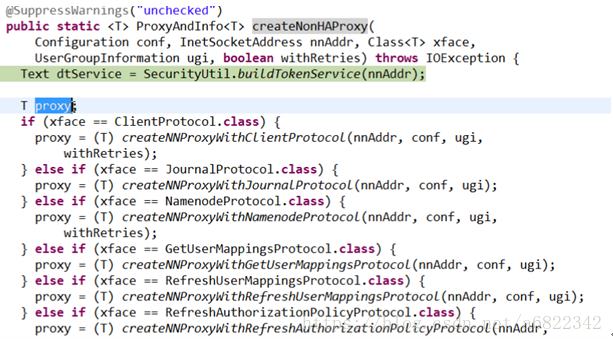
我们这里是客户端,所以和第一个条件匹配,返回的是客户端和namenode通信的proxy,nnAddr就是namenode的ip地址,withRetries是可重试的机制设定(若第一次失败,则重来)。
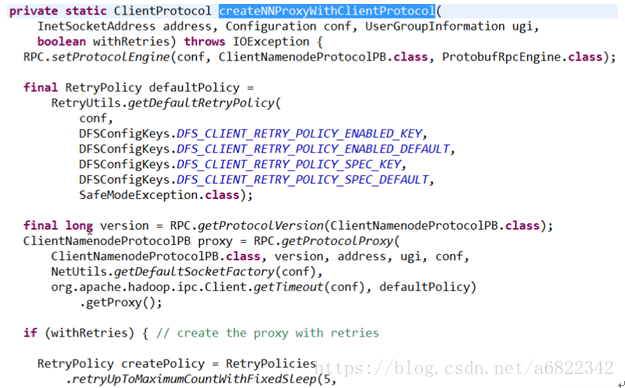
通过RPC.getProtocolProxy获得proxy,最后封装一下返回。
然后一直返回,通过initialize方法的返回值赋值给distributedfilesystem的dfs成员
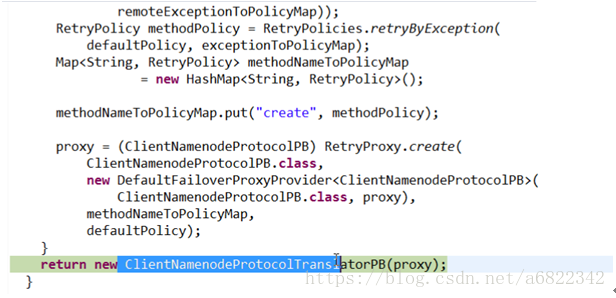
最后到工作代码里面来
