阅读Transformer之后的系列文章,这里记录下阅读论文之后的一些问题:
问题1: attention机制与全连接的差异:
深度学习中Attention与全连接层的区别何在? - 知乎
i 注意力机制可以利用输入的特征信息来确定哪些部分更重要
ii 注意力机制的意义是引入了权重函数f,使得权重与输入相关,从而避免了全连接层中权重固定的问题。
对于变长的序列,计算注意力的筛选标准避免了长度带来的信息的天然变化,而是有一定侧重及标准的。
问题2: 怎样理解attention层:
注意力机制的keras书籍中的解释看起来是比较经典的:
Attention的第一步:计算注意力分布可以理解为计算查询变量query与周边单词的相似度(语言模型即计算embedding之积),而第二步可以理解为计算句子中所有的词向量的和,即结果向量是结合查询变量query与周边文本关系的结果。
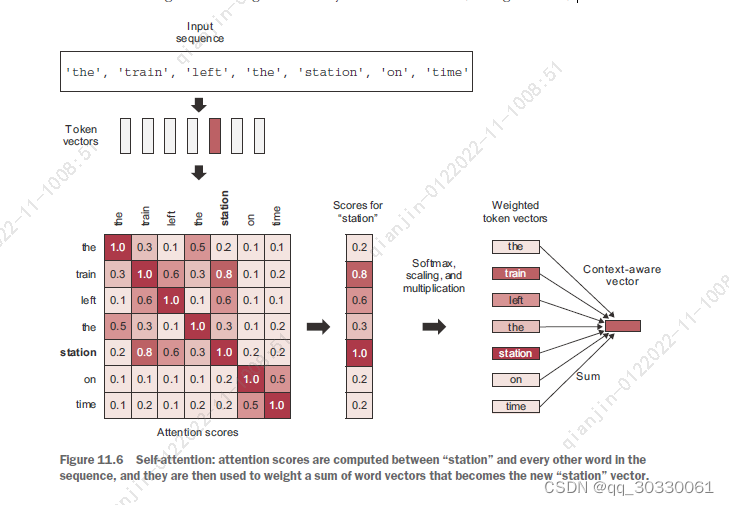
ATTENTION的计算过程被理解为: 1、compute relevancy scores between the vector like “station” and every other word in the sentence;
2、to compute the sum of all word vectors in the sentence,The resulting vector is our new representation for “station”: a representation that incorporates the surrounding context.
You’d repeat this process for every word in the sentence, producing a new sequence of vectors encoding the sentence.
问题3:键值对注意力,如何选择键值对
键值对注意力的思想开始来自于推荐系统,需要根据query的情况来对于结果进行重排。Transformer-style attention的思路也是这样的,根据query来提取sequence中的exact information。You simply match the query to the keys. Then you return a weighted
sum of values。由此说明,我们可以知道:
翻译问题中,问题应该是 target sequence, 而 the source sequence 将是 keys and values。
分类问题中,then query, keys, and values are all the same,因为我们希望将自身与自身的周围元素进行比较,并将结果通过句子本身抽象出来。
问题4: 怎样理解Multi-head attention:
Multi-head attention采用的思路是与卷积的思路比较类似的, Multi-head attention可以实现学习不同组别的token相关的特征,从而类似卷积实现:学习到不同的子空间的独立的特征对。