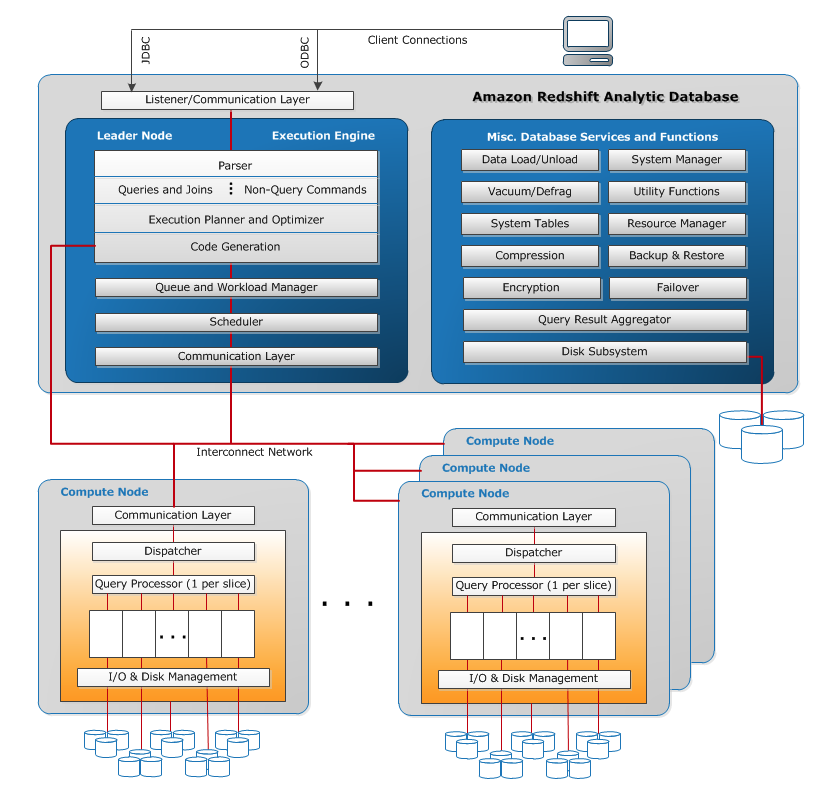
系统架构

Redshfit优点
- MPP(大规模并行处理)
- 多个计算节点处理查询以获得最终结果并提交给Leader聚合,执行相同的编译后查询的每个节点的每个Slices在整个数据的各个部分进行分段。
- Redshift 将表行分配给计算节点,以便能并行处理数据。通过为每个表选择相应的分配键,可以优化数据分配以均衡工作负载,并最大程度地减少节点间的数据移动。
- 加载平面文件中的数据时将利用并行处理,方式是跨多个节点分配工作负载,同时从多个文件进行读取。
- 列式数据存储
- 数据压缩
- 结果缓存
- 为了缩短查询执行时间并改进系统性能,Amazon Redshift 在领导节点的内存中缓存特定查询类型的结果。当用户提交查询时,Amazon Redshift 会在结果缓存中检查是否有查询结果的有效缓存副本。如果在结果缓存中找到匹配项,则 Amazon Redshift 会使用缓存的结果而不执行查询。结果缓存对用户透明。
- 默认情况下,结果缓存处于启用状态。要为当前会话禁用结果缓存,请将 enable_result_cache_for_session 参数设置为
off。 - 在满足以下所有条件时,Amazon Redshift 将为新查询使用缓存的结果:
- 提交查询的用户具有在查询中所用对象的访问权限。
- 查询中的表或视图未更改。
- 查询不使用必须在每次运行时求值的函数,例如 GETDATE。
- 该查询不引用 Amazon Redshift Spectrum 外部表。
- 可能影响查询结果的配置参数未更改。
- 查询的语法与缓存的查询相符。
- 为了最大限度地提升缓存有效性和资源的使用效率,Amazon Redshift 不缓存一些非常大的查询结果集。
- 要确定查询是否使用了结果缓存,请查询 SVL_QLOG 系统视图。如果查询使用了结果缓存,source_query 列会返回源查询的查询 ID。如果未使用结果缓存,则 source_query 列值为 NULL。
-
select userid, query, elapsed, source_query from svl_qlog where userid > 1 order by query desc; userid | query | elapsed | source_query -------+--------+----------+------------- 104 | 629035 | 27 | 628919 104 | 629034 | 60 | 628900 104 | 629033 | 23 | 628891 102 | 629017 | 1229393 | 102 | 628942 | 28 | 628919 102 | 628941 | 57 | 628900 102 | 628940 | 26 | 628891 100 | 628919 | 84295686 | 100 | 628900 | 87015637 | 100 | 628891 | 58808694 |
节点
Leader节点:
- Leader节点负责接收客户端SQL并分发给对应的Worker节点,并将数据返回给客户端。
- 它分析和制定执行计划以实施数据库操作,特别是获得复杂查询的结果所需执行的一系列步骤。根据执行计划,领导节点编译节点、将编译后的节点分发给计算节点,并将部分数据分配给每个计算节点。
- 领导节点仅在查询引用计算节点上存储的表时,才将 SQL 语句分发给计算节点。所有其他查询仅在领导节点上运行。
Worker节点:
- 领导节点为执行计划的单个元素编译代码并将代码分配给各个计算节点。
- 计算节点执行编译后的代码,并将中间结果发送回领导节点以便最终聚合。
Slices切片
- 一个计算节点分为多个切片。将为每个切片分配节点的内存和磁盘空间的一部分,从而处理分配给节点的工作负载的一部分。
- 导节点管理向切片分发数据的工作,并将任何查询或其他数据库操作的工作负载分配给切片。然后,切片将并行工作以完成操作。
| R3 节点类型 | ||||||
|---|---|---|---|---|---|---|
| 节点大小 | vCPU | RAM (GiB) | 每节点的切片数 | 每个节点的托管存储 | 节点范围 | 总容量 |
| ra3.16xlarge | 48 | 384 | 16 | 64 TB* | 2–128 | 8.192 PB |
| 密集存储节点类型 | ||||||
|---|---|---|---|---|---|---|
| 节点大小 | vCPU | RAM (GiB) | 每节点的切片数 | 每节点的存储容量 | 节点范围 | 总容量 |
| ds2.xlarge | 4 | 13 | 2 | 2TB HDD | 1–32 | 64 TB |
| ds2.8xlarge | 36 | 244 | 16 | 16TB HDD | 2–128 | 2PB |
| 密集计算节点类型 | ||||||
|---|---|---|---|---|---|---|
| 节点大小 | vCPU | RAM (GiB) | 每节点的切片数 | 每节点的存储容量 | 节点范围 | 总容量 |
| dc1.large | 2 | 15 | 2 | 160GB SSD | 1–32 | 5.12 TB |
| dc1.8xlarge | 32 | 244 | 32 | 2.56TB SSD | 2–128 | 326 TB |
| dc2.large | 2 | 15.25 | 2 | 160 GB NVMe-SSD | 1–32 | 5.12 TB |
| dc2.8xlarge | 32 | 244 | 16 | 2.56 TB NVMe-SSD | 2–128 | 326 TB |
注意事项:
- Redshift基于 PostgreSQL 8.0.2,建议使用 JDBC4 Postgresql 驱动程序 8.4.703 版和 psqlODBC 9.x 版的驱动程序 或Redshift驱动
- 为了避免在使用 JDBC 检索大型数据集时出现客户端内存不足错误,您可通过设置 JDBC 提取大小参数来使您的客户端能够成批提取数据。有关更多信息,请参阅 设置 JDBC 提取大小参数。
- postgres中Vacuum只回收空间并重复使用,但Redshift中vacuum为vacuum full,回收磁盘空间并对所有列重新排序。
集群状态
| 状态 | 描述 |
|---|---|
available |
集群正在运行且可供使用。 |
available, prep-for-resize |
该集群正在为弹性调整大小操作做准备。集群正在运行且可用于读取和写入查询,但集群操作(例如,创建快照)不可用。 |
available, resize-cleanup |
弹性调整大小操作正在完成到新集群节点的数据传输。集群正在运行且可用于读取和写入查询,但集群操作(例如,创建快照)不可用。 |
creating |
Amazon Redshift 正在创建集群。有关更多信息,请参阅创建集群。 |
deleting |
Amazon Redshift 正在删除集群。有关更多信息,请参阅删除集群。 |
final-snapshot |
Amazon Redshift 正在删除集群前对其制作最终快照。有关更多信息,请参阅删除集群。 |
hardware-failure |
集群发生了硬件故障。 如果您的集群为单节点集群,则该节点无法替换。要恢复您的集群,请还原快照。有关更多信息,请参阅 Amazon Redshift 快照。 |
incompatible-hsm |
Amazon Redshift 无法连接到硬件安全模块 (HSM)。检查集群和 HSM 之间的 HSM 配置。有关更多信息,请参阅使用硬件安全模为 Amazon Redshift 加密。 |
incompatible-network |
基本网络配置出现问题。确保您在其中启动集群的 VPC 及其设置正确无误。有关更多信息,请参阅在 VPC 中管理集群 。 |
incompatible-parameters |
相关联的参数组中的一个或多个参数值出现问题,此时无法应用这些参数值。修改参数组并更新所有无效值。有关更多信息,请参阅Amazon Redshift 参数组。 |
incompatible-restore |
从快照中还原集群时出现问题。使用其他快照再次尝试还原集群。有关更多信息,请参阅Amazon Redshift 快照。 |
modifying |
Amazon Redshift 正在将更改应用于集群。有关更多信息,请参阅修改集群。 |
rebooting |
Amazon Redshift 正在重启集群。有关更多信息,请参阅重启集群。 |
renaming |
Amazon Redshift 正在将新名称应用于集群。有关更多信息,请参阅重命名集群。 |
resizing |
Amazon Redshift 正在调整集群的大小。有关更多信息,请参阅调整集群大小。 |
rotating-keys |
Amazon Redshift 正在轮换集群的加密密钥。有关更多信息,请参阅Amazon Redshift 中的加密密钥轮换。 |
storage-full |
集群已达到其存储容量。调整集群的大小以添加节点或选择其他节点大小。有关更多信息,请参阅调整集群大小。 |
updating-hsm |
Amazon Redshift 正在更新 HSM 配置。。 |
影响查询性能的因素
- 节点、处理器或切片的数量
- 节点类型
- 数据分配:在执行查询时,查询优化程序根据执行联接和聚合的需要将数据重新分配到计算节点。为表选择适当的分配方式可在执行联接前将数据放置到所需位置,这有助于尽量减少重新分配步骤产生的影响。
- 数据排序顺序(SortKey):查询优化程序和查询处理器利用数据放置位置的相关信息减少需要扫描的数据块数,从而提高查询速度。
- 数据集大小
- 并发操作:每个操作都会占用可用查询队列中的一个或多个槽,并占用与这些槽关联的内存。如果其他操作正在运行,则可能没有充足的查询队列槽可用。在这种情况下,查询必须等待有槽回收后才能开始处理。
- 查询结构:查询的编写方式也会影响其性能。在满足需求的前提下,请尽量将查询编写为处理和返回尽量少的数据。
- 代码编译
- Amazon Redshift 为每个查询执行计划生成和编译代码。
- 编译代码执行更快,因为它消除了使用解释器的开销。首次生成和编译代码时总会产生一些开销。因此,首次运行查询时的性能可能会造成误导。运行一次性查询时,此开销可能会特别明显。再一次运行查询以确定其典型性能。
- 编译的代码段本地存储集群中并远程存储在 AWS 账户级缓存中。相同查询的后续执行可以更快地运行,因为它可以跳过编译阶段。缓存在集群重启后依然保留,但可通过维护升级擦除。
- Amazon Redshift 为每个查询执行计划生成和编译代码。