问:Amazon Redshift 支持多可用区部署吗?
当前 Amazon Redshift 仅支持单一可用区部署。通过将数据从同一组 Amazon S3 输入文件加载到各个 AZ 中的两个 Amazon Redshift 数据仓库群集中,您便可在多个 AZ 中运行数据仓库群集。借助 Redshift Spectrum,您可以跨可用区运行多个群集,并访问 Amazon S3 中的数据,而无需将其加载到群集中。此外,您也可将数据仓库群集从数据仓库群集快照恢复至其他可用区。
问:Amazon Redshift 如何备份数据? 如何从备份中还原群集?
在加载数据时,Amazon Redshift 会复制数据仓库群集内的所有数据并将其连续备份至 S3。Amazon Redshift 始终尝试维持至少三份数据(计算节点上的正本数据、副本数据和 Amazon S3 上的备份数据)。Redshift 还能将您的快照异步复制到另一个区域的 S3 中进行灾难恢复。
默认情况下,Amazon Redshift 以一天的保留期启用数据仓库群集的自动化备份。您可将其配置为 35 天之久。
免费备份存储受限于数据仓库群集中节点上的总存储大小,并仅适用于已激活的数据仓库群集。例如,如果您有 8TB 的数据仓库总存储大小,那么我们将提供最多 8TB 的备份存储而不另外收费。
问:如何扩展 Amazon Redshift 数据仓库群集的大小和性能?
如何您想提高查询性能或应对 CPU、内存或 I/O 的过度使用,那么您可通过 AWS 管理控制台或 ModifyCluster API 增加数据仓库群集内的节点数。在您修改自己的数据仓库群集时,所请求的更改会立即应用。您可以通过 AWS 管理控制台或 Amazon CloudWatch API 免费获得计算使用率、存储使用率和 Amazon Redshift 数据仓库集群读/写流量方面的指标。您也可以通过 Amazon Cloudwatch 的自定义指标功能来添加更多用户定义的指标。
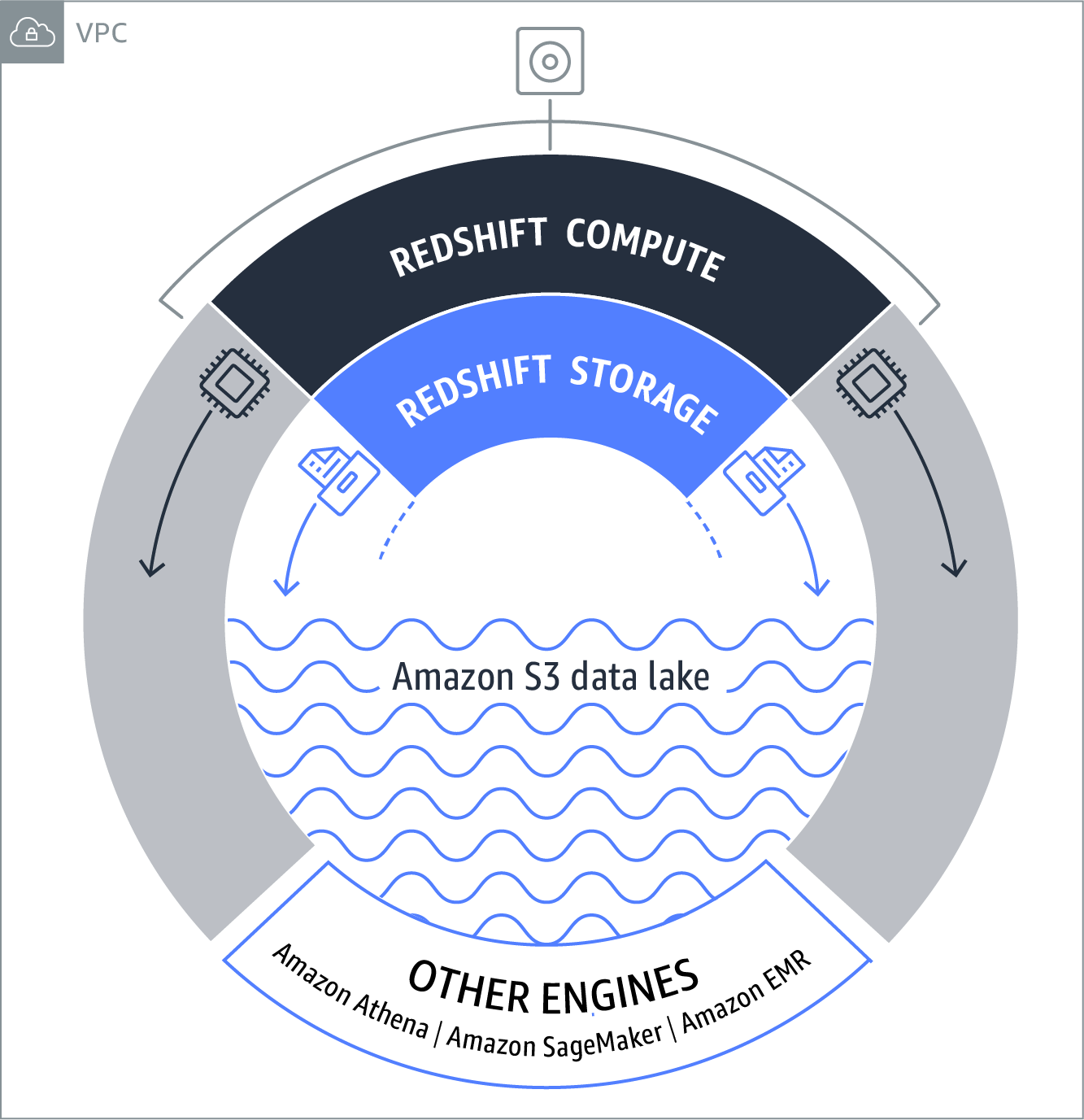
借助 Redshift Spectrum,您可以运行多个访问 Amazon S3 中相同数据的 Amazon Redshift 群集。您可以针对不同的使用案例使用不同的群集。例如,您可以将某个群集用于标准报告,将另一个群集用于数据科学查询。您的营销团队可以使用与运营团队不同的自己的群集。根据本地群集中的节点类型和数量以及运行查询需要处理的文件数量,Redshift Spectrum 会自动将查询的任执行务分配到共享资源池外的多个 Redshift Spectrum 工作线程,以读取和处理来自 Amazon S3 的数据,然后将结果返回到 Amazon Redshift 群集中进行任何剩余处理。
问:Amazon Redshift 和 Redshift Spectrum 与我的首选商业智能软件包及 ETL 工具兼容吗?
Amazon Redshift 使用行业标准 SQL 并可使用标准 JDBC 和 ODBC 驱动程序进行访问。您可以从 Redshift 控制台的“连接客户端”选项卡中下载 Amazon Redshift 自定义 JDBC 和 ODBC 驱动程序。我们与主流 BI 和 ETL 供应商进行的集成已经得到验证,其中许多都提供免费试用,以帮助您开始使用加载和分析数据。您也可以进入 AWS Marketplace,在数分钟内部署和配置能够与 Amazon Redshift 配合使用的解决方案。
Redshift Spectrum 支持所有 Amazon Redshift 客户端工具。客户端工具可继续使用 ODBC 或 JDBC 连接来连接到 Amazon Redshift 群集终端节点,而无需进行任何更改。
访问 Redshift Spectrum 中的表与访问 Redshift 群集的本地存储中的表所使用的查询语法和查询功能完全相同。您可以使用注册外部表所用的 CREATE EXTERNAL SCHEMA 命令中定义的架构名称来引用外部表。
问:Redshift Spectrum 支持哪些数据格式和压缩格式?
Redshift Spectrum 目前支持许多开源数据格式,其中包括 Avro、CSV、Grok、Ion、JSON、ORC、Parquet、RCFile、RegexSerDe、SequenceFile、TextFile 和 TSV。
Redshift Spectrum 目前支持 Gzip 和 Snappy 压缩。
问:如何将数据加载到 Amazon Redshift 数据仓库中?
您可以从一系列数据源中将数据加载到 Amazon Redshift,包括 Amazon S3、Amazon DynamoDB、Amazon EMR、AWS Glue、AWS Data Pipeline 和/或 Amazon EC2 上或本地的任何启用 SSH 的主机。Amazon Redshift 尝试将数据并行加载到每个计算节点中,从而最大限度地提高数据仓库群集数据摄入速度。
可以,用户可以使用 ODBC 或 JDBC 连接至 Amazon Redshift 并发出 'insert' SQL 命名以插入数据。请注意这会比使用 S3 或 DynamoDB 慢一些,因为那些方法将数据并行加载至每个计算节点,而 SQL 插入语句则通过单个领导节点加载数据。
问:如何将数据从现有的 Amazon RDS、Amazon EMR、Amazon DynamoDB 及 Amazon EC2 数据源加载到 Amazon Redshift?
您可以使用 COPY 命令以并行方式将数据从 Amazon EMR、Amazon DynamoDB 或任何启用 SSH 的主机直接加载到 Amazon Redshift 中。此外,您还可以通过 Redshift Spectrum 使用简单的 INSERT INTO 命令将数据从 Amazon S3 加载到群集中。这样一来,您可以将各种格式的数据(如 Parquet 和 RC)加载到群集中。请注意,如果使用此方法,则 Redshift Spectrum 会针对从 Amazon S3 中扫描到的数据量累计计费。
此外,许多 ETL 公司还对 Amazon Redshift 进行了认证,以便将其与自己的工具配合使用,其中有很多公司还提供了免费试用,以帮助您开始加载数据。AWS Data Pipeline 提供可从各种 AWS 数据源加载数据的高性能、可靠且容错的解决方案。您可用 AWS Data Pipeline 来指定数据源和理想的数据转换,然后执行一个预先写入的导入脚本,将您的数据加载到 Amazon Redshift 中。此外,AWS Glue 还是一项完全托管的提取、转换和加载 (ETL) 服务,可让您轻松准备和加载数据进行分析。您只需在 AWS 管理控制台中单击几次,即可创建并运行 AWS Glue ETL 任务。
问:我能直接访问 Amazon Redshift 计算节点吗?
不能。您的 Amazon Redshift 计算节点处于私有网络空间中,仅能从数据仓库群集的领导节点对其进行访问。这就为您的数据安全性提供了另外一层保护。