准备研究一下AWS平台对大数据的支持,我之前用的是aliyun的maxcompute,在国内比较好,但是如果要想把业务扩展到国际,阿里云可能没有AWS那么大的优势。
太细节的东西我就懒得写了,只要给大家梳理一下流程思路,细节的东西我会找到相应的文档贴出来。
浏览AWS平台中大数据相关的工具,最终把目光定位在了redshift上面,这是个数据仓库产品,与maxcomponte对比下得出的结果是
| 对标项 | redshift | maxcompute |
|---|---|---|
| 性能 | 赢 | 输 |
| 功能 | 输 | 赢 |
| 界面 | 输 | 赢 |
想用redshift来代替maxcompute中的功能就比了一下强弱,其实说实话它俩对标性不是太强。redshift更多的只是用来做存储,但是maxcompute把存储、计算、运维甚至是ETL都给干了。但是redshift在存储方面做的更优秀。
redshift入门步骤
一、选国际AWS服务,但是要越过那道。。。你懂的
AWS现在也入驻国内了,但是支持企业去注册,这点比较尴尬,所以也只能用国外的服务。另外国外是有2个月的免费使用期限的,国内的啥都没有。说起来还是看阿里云比较亲切。
二、入门文档阅读顺序
https://docs.aws.amazon.com/zh_cn/redshift/latest/gsg/rs-gsg-prereq.html
先按这个文档把活给做了
主要就是环境搭建的前置条件
workbench下载地址在这里
http://www.sql-workbench.eu/downloads.html
三、workbench/j连接redshift服务
第一次连接在这里踩过坑,直接连不上的,需要设置一下防火墙,找了好几个文档才找到原因,如果对AWS平台更熟悉点可能会快一些,无奈是新手呀。具体参见文档 : https://docs.aws.amazon.com/zh_cn/redshift/latest/gsg/rs-gsg-authorize-cluster-access.html
给大家展示一下我的workbench/J工具连接界面
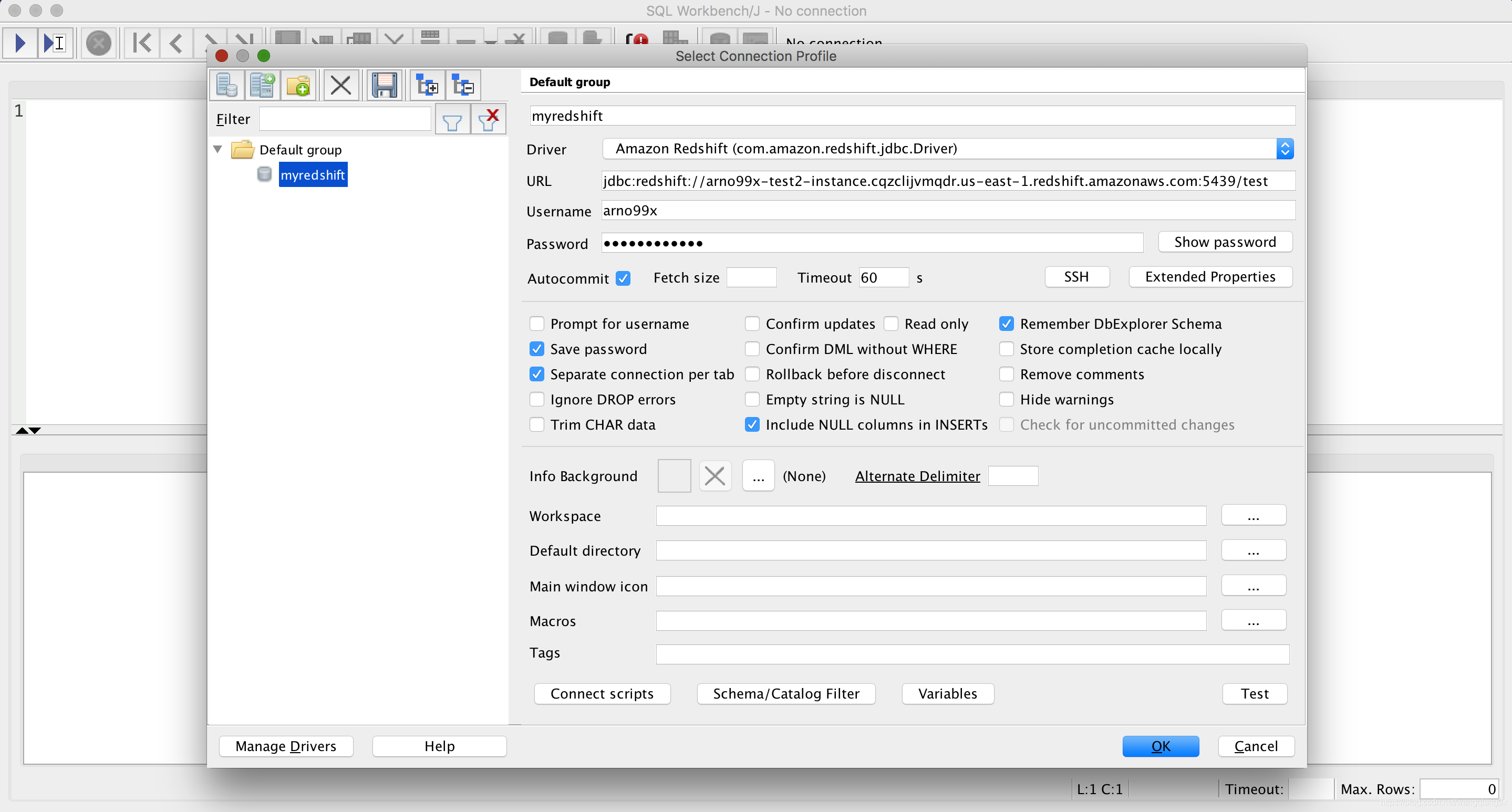
连接后可以在workbench/j中编辑自己的SQL,如下图
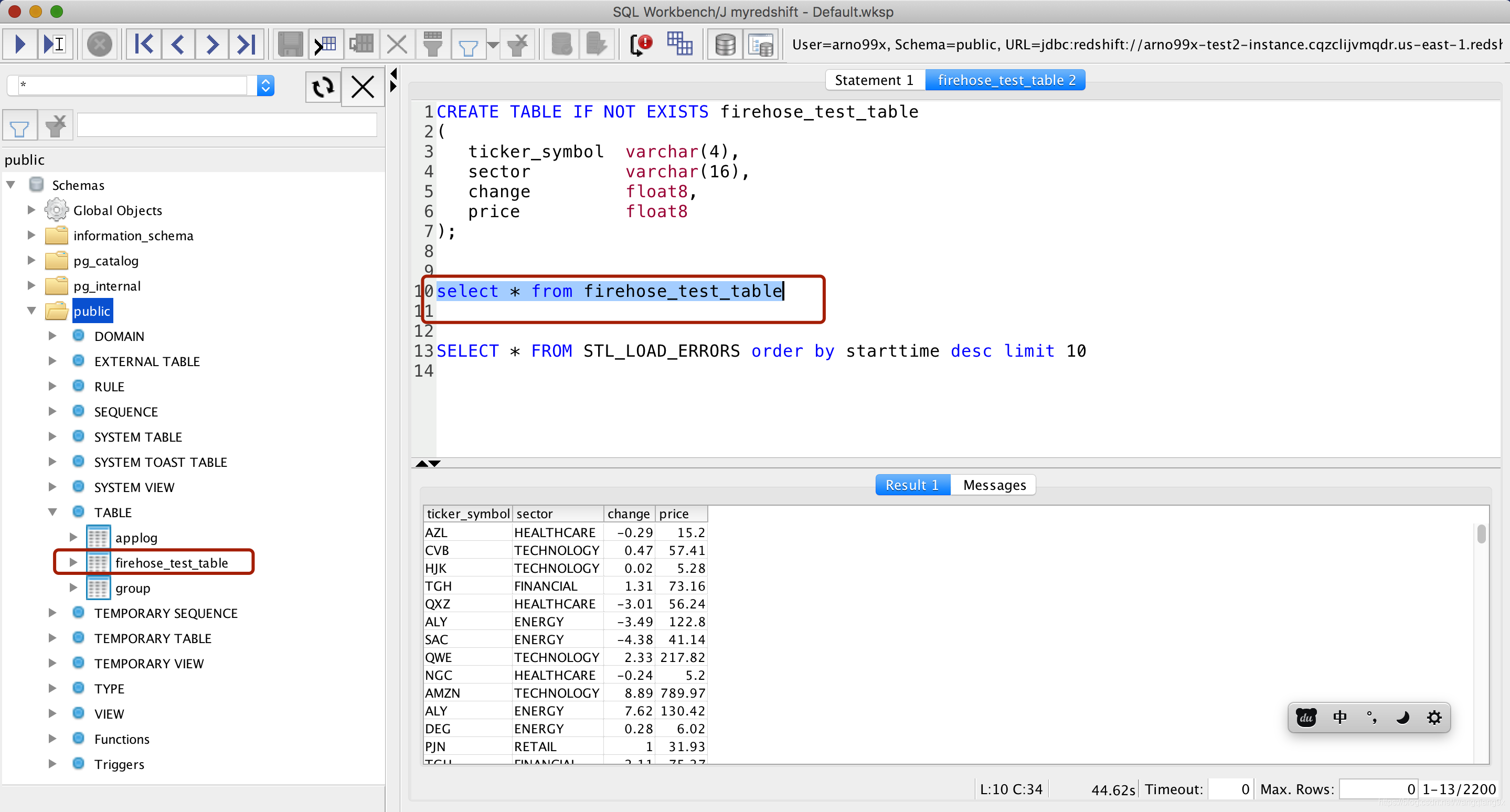
我也是初学者,介绍的不是很深入但是打通任督二脉后,真气运转起来会很快的,可以直接进入实战了。
有了数据仓库,下一步更重要的肯定是要想办法去收集各种数据,等我下篇吧。