1.概要
本文档详细介绍了Redshift和MaxCompute之间SQL语法的异同。这篇文档有助于加快sql任务迁移到MaxCompute。由于Redshift和MaxCompute之间语法存在很多差异,因此我们需要修改Redshift上编写的脚本,然后才能在MaxCompute中使用,因为服务之间的SQL方言不同。
2.迁移前RedShift于MaxCompute的各项对比差异
2.1.1数据类型对比及类型转化
| 类别 |
MaxCompute |
建议转化成MaxCompute类型 |
Redshift |
|
| 数值类型 |
smallint |
Y |
Y |
Y |
| integer |
N |
int |
Y |
|
| bigint |
Y |
int |
Y |
|
| decimal |
Y |
Y |
Y |
|
| numeric |
N |
decimal |
Y |
|
| real |
N |
float |
Y |
|
| double |
Y |
Y |
Y |
|
| float |
Y |
float |
Y |
|
| TINYINT |
Y |
smallint |
N |
|
| 字符类型 |
varchar(n) |
Y |
Y |
Y |
| char(n) |
Y |
Y |
Y |
|
| STRING |
Y |
|||
| text |
N |
string |
Y |
|
| 日期 |
TIMESTAMP |
Y |
Y |
Y |
| TIMESTAMPTZ |
N |
Y |
||
| DATE |
Y |
Y |
Y |
|
| TIME |
N |
Y |
||
| DateTime |
Y |
N |
||
| boolean 数据类型 |
boolean |
Y |
Y |
Y |
| 复杂数据类型 |
ARRAY |
Y |
Y |
N |
| MAP |
Y |
Y |
N |
|
| STRUCT |
Y |
Y |
N |
|
| HLLSketch |
N |
Y |
MaxCompoute数据类型参考https://help.aliyun.com/document_detail/159541.html
2.1.2语法对比
MaxCompute没有schenma、group、库、存储过程的概念。只有project、表、分区,MaxCompute建表时没有自增序列 外键等,不支持指定编码默认utf-8,内部表不支持指定存储格式默认Aliorc
| 主要区别 |
|
| 表结构 |
不能修改分区列列名,只能修改分区列对应的值。 |
| 支持增加列,但是不支持删除列以及修改列的数据类 型。 |
|
| SQL 常见问题 |
INSERT 语法上最直观的区别是:Insert into/overwrite 后面 有个关键字 Table。 |
| 数据插入表的字段映射不是根据 Select 的别名做的,而 是根据 Select 的字段的顺序和表里的字段的顺序 |
|
| UPDATE/DELETE |
只有事务表支持UPDATE/DELETE |
| join |
Join 必须要用 on 设置关联条件,不支持笛卡尔积 |
| 触发器 |
不支持触发器、 |
| 创建外部函数 |
maxCompute没有外部函数 |
| 精度 |
DOUBLE 类型存在精度问题。 不建议在关联时候进行直接等号关联两 个 DOUBLE字段,建议把两个数做减 法,如果差距小于一个预设的值就认为 是相同,例如 abs(a1- a2) < 0.000000001。 目前产品上已经支持高精度的类型 DECIMAL。 |
| 日期 |
MaxCompute主要的日期类型是datetime(格式yyyy-mm-dd hh:mi:ss) timestamp date,datetime支持的内建函数更加丰富,建议日期转成datetime做运算,日期函数链接 |
| 存储过程 |
使用MaxCompute的pyodps修改 |
| 物化视图 |
要更新物化化视图中的数据,MaxCompute只能手动更新,不支持自动更新 |
| redshift 支持在select语句中引用别名如 select money/100 as a ,round(money/100,3) from table |
MaxCompute修改 select money/100 as a ,round(a,3) from table |
2.1.3复合表达式
| MaxCompute |
REDAHIFT |
|
| +、- |
Y |
Y |
| ^、|/、||/ |
Y |
Y |
| *、/、% |
Y |
Y |
| @ |
N |
Y |
| &、|、 |
Y |
Y |
| || |
Y |
Y |
| #、~、<<、>> |
使用shift函数替换 |
Y |
2.1.4条件比较
| MaxCompute |
REDAHIFT |
|
| <> 或 != |
Y |
Y |
| like |
Y |
Y |
| BETWEEN expression AND |
Y |
Y |
| IS [ NOT ] NULL |
Y |
Y |
| EXISTS |
Y |
Y |
| POSIX 运算符 |
N |
Y |
| SIMILAR TO |
N |
Y |
| IN |
Y |
Y |
| 正则 ~ |
Rlike |
Y |
| ~~ |
like |
Y |
2.1.5DDL语法
主要差异:
1.MaxCompute不支持主键自增和PRIMARY KEY
2.指定默认值default]不支持使用函数
3.decimal指定默认值不支持-1
| 语法 |
MaxCompute |
REDSHIFT |
| CREATE TABLE—PRIMARY KEY |
N |
Y |
| CREATE TABLE—NOT NULL |
Y |
Y |
| CREATE TABLE—CLUSTER BY |
Y |
N |
| CREATE TABLE—EXTERNAL TABLE |
Y(OSS, OTS, TDDL) |
N |
| CREATE TABLE—TEMPORARY TABLE |
N |
Y |
| table_attributes |
N(Mc内部表不需要添加属性) |
Y |
| CREATE TABLE—AS |
Y |
Y |
| create materialized view |
Y |
Y |
2.1.6DML语法差异
| 语法 |
MaxCompute |
REDSHIFT |
| CTE |
Y |
Y |
| SELECT—into |
N |
Y |
| SELECT—recursive CTE |
N |
Y |
| SELECT—GROUP BY ROLL UP |
Y |
N |
| SELECT—GROUPING SET |
Y |
Y |
| SELECT—IMPLICT JOIN |
Y |
Y |
| SEMI JOIN |
Y |
N |
| SELEC TRANSFROM |
Y |
N |
| SELECT—corelated subquery |
Y |
Y |
| LATERAL VIEW |
Y |
Y |
| SET OPERATOR—UNION (disintct) |
Y |
Y |
| SET OPERATOR—INTERSECT |
Y |
Y |
| SET OPERATOR—MINUS/EXCEPT |
Y |
Y |
| INSERT INTO ... VALUES |
Y |
Y |
| INSERT INTO (ColumnList) |
Y |
Y |
| UPDATE … WHERE |
Y(事务表支持) |
Y |
| DELETE … WHERE |
Y(事务表支持) |
Y |
| ANALYTIC—reusable WINDOWING CLUSUE |
Y |
Y |
| ANALYTIC—CURRENT ROW |
Y |
Y |
| ANALYTIC—UNBOUNDED |
Y |
Y |
| ANALYTIC—RANGE … |
Y |
Y |
| WHILE DO |
N |
Y |
| VIEW WITH PARAMETERS |
Y |
N |
| select * into |
N |
Y |
2.1.7内建函数对比
其他未列出的redshift函数不支持。
| 函数类型 |
MaxCompute |
POSTGRESQL |
在MaxCompute SQL中是否支持分区剪裁 |
| 日期函数 |
无 |
ADD_MES |
|
| 无 |
CONVERT_TIMEZONE |
||
| 无 |
DATE_CMP_TIMESTAMP |
||
| 无 |
DATE_CMP_TIMESTAMPTZ |
||
| 无 |
DATE_PART_YEAR |
||
| 无 |
DATE_CMP |
||
| 无 |
INTERVAL_CMP |
||
| 无 |
+ |
||
| 无 |
SYSDATE |
||
| 无 |
TIMEOFDAY |
||
| 无 |
TIMESTAMP_CMP |
||
| 无 |
TIMESTAMP_CMP_DATE |
||
| 无 |
TIMESTAMP_CMP_TIMESTAMPTZ |
||
| 无 |
TIMESTAMPTZ_CMP |
||
| 无 |
TIMESTAMPTZ_CMP_DATE |
||
| 无 |
TIMESTAMPTZ_CMP_TIMESTAMP |
||
| 无 |
to_timestamp |
||
| 无 |
TIMEZONE |
||
| DATEDIFF |
DATEDIFF |
|
|
| DATE_ADD |
DATEADD |
|
|
| DATEPART |
date_part |
|
|
| DATETRUNC |
date_trunc |
|
|
| FROM_UNIXTIME |
无 |
|
|
| GETDATE |
CURRENT_DATE |
|
|
| ISDATE |
无 |
|
|
| LASTDAY |
无 |
|
|
| TO_DATE |
TO_DATE |
|
|
| TO_CHAR |
to_char |
|
|
| UNIX_TIMESTAMP |
extract |
|
|
| WEEKDAY |
无 |
|
|
| WEEKOFYEAR |
无 |
|
|
| YEAR |
extract |
|
|
| QUARTER |
EXTRACT |
|
|
| MONTH |
EXTRACT |
|
|
| DAY |
EXTRACT |
|
|
| DAYOFMONTH |
无 |
|
|
| HOUR |
EXTRACT |
|
|
| MINUTE |
EXTRACT |
|
|
| CURRENT_TIMESTAMP |
CURRENT_TIMESTAMP |
|
|
| ADD_MONTHS |
运算符+ |
|
|
| LAST_DAY |
LAST_DAY |
|
|
| NEXT_DAY |
NEXT_DAY |
|
|
| MONTHS_BETWEEN |
MONTHS_BETWEEN |
|
|
| 数学函数 |
无 |
exp |
|
| 无 |
ATAN2 |
||
| 无 |
DEXP |
||
| 无 |
DLOG1 |
||
| 无 |
DLOG10 |
||
| ABS |
ABS |
|
|
| ACOS |
ACOS |
|
|
| ASIN |
ASIN |
|
|
| ATAN |
ATAN |
|
|
| CEIL |
CEIL |
|
|
| CONV |
convert |
|
|
| COS |
COS |
|
|
| COSH |
ACOS |
|
|
| COT |
COT |
|
|
| EXP |
EXP |
|
|
| FLOOR |
FLOOR |
|
|
| LN |
LN |
|
|
| LOG |
LOG |
|
|
| POW |
power |
|
|
| RAND |
random |
|
|
| ROUND |
ROUND |
|
|
| SIN |
SIN |
|
|
| SINH |
asin |
|
|
| SQRT |
SQRT |
|
|
| TAN |
TAN |
|
|
| TANH |
atan |
|
|
| TRUNC |
TRUNC |
|
|
| LOG2 |
LOG |
|
|
| LOG10 |
LOG |
|
|
| BIN |
无 |
|
|
| HEX |
无 |
|
|
| UNHEX |
无 |
|
|
| RADIANS |
RADIANS |
|
|
| DEGREES |
DEGREES |
|
|
| SIGN |
SIGN |
|
|
| E |
无 |
|
|
| PI |
PI |
|
|
| FACTORIAL |
无 |
|
|
| CBRT |
CBRT |
|
|
| SHIFTLEFT |
<< |
|
|
| SHIFTRIGHT |
>> |
|
|
| SHIFTRIGHTUNSIGNED |
>>> |
|
|
| 窗口函数 |
无 |
CUME_DIST |
|
| 无 |
FIRST_VALUE/LAST_VALUE |
||
| 无 |
LISTAGG |
||
| 无 |
NTH_VALUE |
||
| 无 |
PERCENTILE_CONT |
||
| 无 |
PERCENTILE_DISC |
||
| 无 |
RATIO_TO_REPORT ( ratio_expression ) OVER ( [ PARTITION BY partition_expression ] ) |
||
| 无 |
STDDEV_SAMP |
||
| 无 |
VAR_SAMP | VARIANCE | VAR_POP |
||
| 无 |
PERCENT_RANK |
||
| DENSE_RANK |
DENSE_RANK |
|
|
| RANK |
RANK |
|
|
| LAG |
LAG |
|
|
| LEAD |
LEAD |
|
|
| PERCENT_RANK |
PERCENT_RANK |
|
|
| ROW_NUMBER |
ROW_NUMBER |
|
|
| CLUSTER_SAMPLE |
无 |
|
|
| NTILE |
NTILE |
|
|
| 聚合函数 |
PERCENTILE_APPROX |
APPROXIMATE PERCENTILE_DISC |
|
| 无 |
LISTAGG |
||
| 无 |
PERCENTILE_CONT |
||
| ANY_VALUE |
ANY_VALUE |
||
| COUNT |
COUNT |
|
|
| AVG |
AVG |
|
|
| MAX |
MAX |
|
|
| MIN |
MIN |
|
|
| MEDIAN |
PERCENTILE_disc |
|
|
| STDDEV |
STDDEV |
|
|
| STDDEV_SAMP |
STDDEV_SAMP |
|
|
| SUM |
SUM |
|
|
| WM_CONCAT |
string_agg |
|
|
| COLLECT_LIST |
无 |
|
|
| COLLECT_SET |
无 |
|
|
| VARIANCE/VAR_POP |
VARIANCE/VAR_POP |
|
|
| VAR_SAMP |
VAR_SAMP |
|
|
| COVAR_POP |
COVAR_POP |
|
|
| COVAR_SAMP |
COVAR_SAMP |
|
|
| PERCENTILE |
PERCENTILE_disc |
|
|
| 字符串函数 |
无 |
|| |
|
| 无 |
BPCHARCMP |
||
| 无 |
BTRIM |
||
| 无 |
CHAR_LENGTH |
||
| 无 |
CHARACTER_LENGTH |
||
| 无 |
CHARINDEX |
||
| 无 |
COLLATE |
||
| 无 |
CRC32 |
||
| 无 |
DIFFERENCE |
||
| 无 |
INITCAP |
||
| 无 |
OCTETINDEX |
||
| 无 |
OCTET_LENGTH |
||
| 无 |
QUOTE_IDENT |
||
| 无 |
QUOTE_LITERAL |
||
| 无 |
POSITION |
||
| 无 |
REPEAT |
||
| 无 |
LEFT /RIGHT |
||
| 无 |
STRPOS |
||
| 无 |
STRTOL |
||
| CHAR_MATCHCOUNT |
无 |
|
|
| CHR |
CHR |
|
|
| CONCAT |
CONCAT|array_concat |
|
|
| GET_JSON_OBJECT |
无 |
|
|
| INSTR |
无 |
|
|
| IS_ENCODING |
无 |
|
|
| KEYVALUE |
无 |
|
|
| LENGTH |
LENGTH |
|
|
| LENGTHB |
LEN |
|
|
| MD5 |
无 |
|
|
| REGEXP_EXTRACT |
无 |
|
|
| REGEXP_INSTR |
REGEXP_INSTR |
|
|
| REGEXP_REPLACE |
REGEXP_REPLACE |
|
|
| REGEXP_SUBSTR |
REGEXP_SUBSTR |
|
|
| REGEXP_COUNT |
REGEXP_COUNT |
|
|
| SPLIT_PART |
SPLIT_PART |
|
|
| SUBSTR |
SUBSTR |
|
|
| SUBSTRING |
SUBSTRING |
|
|
| TOLOWER |
LOWER |
|
|
| TOUPPER |
UPPER |
|
|
| TRIM |
TRIM |
|
|
| LTRIM |
LTRIM |
|
|
| RTRIM |
RTRIM |
|
|
| REVERSE |
REVERSE |
|
|
| REPEAT |
REPEAT |
|
|
| ASCII |
ASCII |
|
|
| CONCAT_WS |
CONCAT_WS |
|
|
| LPAD |
LPAD |
|
|
| RPAD |
RPAD |
|
|
| REPLACE |
REPLACE |
|
|
| SOUNDEX |
SOUNDEX |
|
|
| SUBSTRING_INDEX |
SUBSTRING_INDEX |
|
|
| TRANSLATE |
TRANSLATE |
|
|
| URL_DECODE |
无 |
|
|
| URL_ENCODE |
无 |
|
|
| CRC32 |
无 |
|
|
| 其他函数 |
CAST |
CAST |
|
| COALESCE |
COALESCE |
|
|
| DECODE |
DECODE |
|
|
| GET_IDCARD_AGE |
无 |
|
|
| GET_IDCARD_BIRTHDAY |
无 |
|
|
| GET_IDCARD_SEX |
无 |
|
|
| GREATEST |
GREATEST |
|
|
| ORDINAL |
无 |
|
|
| LEAST |
LEAST |
|
|
| MAX_PT |
无 |
|
|
| UUID |
uuid_generate_v1 |
|
|
| SAMPLE |
无 |
|
|
| IF |
IF |
|
|
| CASE WHEN |
CASE WHEN |
|
|
| SPLIT |
SPLIT |
|
|
| STR_TO_MAP |
无 |
|
|
| EXPLODE |
split_to_array |
|
|
| MAP |
无 |
|
|
| MAP_KEYS |
无 |
|
|
| MAP_VALUES |
无 |
|
|
| NVL |
NVL |
|
|
| ARRAY |
ARRAY |
|
|
| SIZE |
get_array_length |
|
|
| ARRAY_CONTAINS |
@> |
|
|
| POSEXPLODE |
无 |
|
|
| TRANS_ARRAY |
无 |
|
|
| INLINE |
无 |
|
|
| NAMED_STRUCT |
无 |
|
|
| 无 |
SUBARRAY |
2.1.8 MaxCompute 产品特性
| 功能 |
MaxCompute 产品组件 |
特性介绍 |
| 数据存储 |
MaxCompute 表 (基于盘古 分布式存储) |
MaxCompute 支持大规模计算存储,适用于 TB 以上规模的存 储及计算需求,最大可达 EB 级别。同一个 MaxCompute 项 目支持企业从 创业团队发展到独角兽的数据规模需求; 数据 分布式存储,多副本冗余,数据存储对外仅开放 表的 操作接口,不提供文件系统访问接口 MaxCompute 支持大规模计算存储,适用于 TB 以上规模的存 储及计算需求,最大可达 EB 级别。同一个 MaxCompute 项目支持企业从 创业团队发展到独角兽的数据规模需求; 数据分布式存储,多副本冗余,数据存储对外仅 开放表的操作接口,不提供文件系统访问接口; 自研数据存储结构,表数据列式存储,默认高度 压缩,后续将提供兼容 ORC的Ali-ORC存储格 式; 支持外表,将存储在OSS 对象存储、OTS表格 存储的数据映射为二维表; 支持Partition、Bucket 的分区、分桶存储; 更底层不是 HDFS,是阿里自研的盘古文件系 统,但可借助 HDFS 理解对应的表之下文件的 体系结构、任务并发机制使用时,存储与计算解 耦,不需要仅仅为了存储扩大不必要的计算资 源; |
| 存储 |
Pangu |
阿里自研分布式存储服务,类似 HDFS。 MaxCompute 对外目前只暴露表接口,不能直 接访问文件系统。 |
| 资源调度 |
Fuxi |
阿里自研的资源调度系统,类似 Yarn |
| 数据上传下载 |
Tunnel Streaming Tunnel |
不暴露文件系统,通过 Tunnel 进行批量数据上传下载 |
| 开发&诊断 |
Dataworks/Studio/Logview |
配套的数据同步、作业开发、工作流编排调度、 作业运维及诊断工具。开源社区常见的 Sqoop、Kettle、Ozzie 等实现数据同步和调度 |
| 用户接口 |
CLT/SDK |
统一的命令行工具和 JAVA/PYTHON SDK |
| SQL |
MaxCompute SQL |
TPC-DS 100%支持,同时语法高度兼容 Hive, 有Hive 背景,开发者直接上手,特别在大数据 规模下性能强大。 * 完全自主开发的 compiler,语言功能开发更 灵活,迭代快,语法语义检查更加灵活高效 * 基于代价的优化器,更智能,更强大,更适合 复杂的查询 * 基于LLVM 的代码生成,让执行过程更高效 * 支持复杂数据类型(array,map,struct) * 支持Java、Python语言的UDF/UDAF/UDTF * 语法:Values、CTE、SEMIJOIN、FROM倒 装、Subquery Operations 、 Set Operations(UNION /INTERSECT /MINUS)、 SELECT TRANSFORM 、User Defined Type、 GROUPING SET(CUBE/rollup/GROUPING SET)、脚本运行模式、参数化视图 * 支持外表(外部数据源+StorageHandler,支 持非结构化数据) |
| Spark |
MaxCompute Spark |
MaxCompute提供了Spark on MaxCompute 的解决方案,使 MaxCompute 提供兼容开源的 Spark 计算服务,让它在统一的计算资源和数据 集权限体系之上,提供 Spark 计算框架,支持用 户以熟悉的开发使用方式提交运行 Spark 作 业。 * 支持原生多版本 Spark 作业: Spark1.x/Spark2.x作业都可运行; * 开源系统的使用体验:Spark-submit 提交方 式,提供原生的 Spark WebUI供用户查看; * 通过访问OSS、OTS、database 等外部数据 源,实现更复杂的 ETL 处理,支持对 OSS 非结 构化进行处理; * 使用 Spark 面向 MaxCompute 内外部数据 开展机器学习, 扩展应用场景 |
| 机器学习 |
PAI |
MaxCompute 内建支持的上百种机器学习算 法,目前 MaxCompute 的机器学习能力由 PAI 产品进行统一提供服务,同时 PAI提供了深度学 习框架、Notebook 开发环境、GPU计算资源、 模型在线部署的弹性预测服务。MaxCompute 的数据对PAI产品无缝集成。 |
| 数据接入 |
目前支撑通过 DTS或者 DataWorks数据集成功能 |
数据集成是稳定高效、弹性伸缩的数据同步平台,丰富的异构数据源之间高速稳定的数据移动及同步能力。支持实时任务和批任务写入MaxCompute |
| 整体 |
不是孤立的功能,完整的企业 服务 |
不需要多组件集成、调优、定制,开箱即用 |
3、RedShift到MaxCompute迁移工具介绍
从数据库表导入到 Amazon S3
https://docs.aws.amazon.com/zh_cn/redshift/latest/dg/c_unloading_data.html?spm=a2c4g.11186623.0.0.50d3358eWX84rm
在线迁移上云服务
https://help.aliyun.com/document_detail/94352.html
将数据从OSS迁移至同区域的MaxCompute项目load命令
https://help.aliyun.com/document_detail/157418.htm?spm=a2c4g.11186623.0.0.50d3358eWX84rm#concept-2419019
语法校验工具二选一
MaxCompute studio
https://help.aliyun.com/document_detail/50889.html
DataWorks sql节点
https://help.aliyun.com/document_detail/137510.html
4、迁移整体方案
数据库迁移主要包含以下内容

迁移实施计划:
| 序号 |
项目 |
预估时间 |
| 1 |
调研评估 |
1~2周 |
| 2 |
方案设计 |
1~2周 |
| 3 |
资源规划 |
1周 |
| 4 |
改造与测试验证 |
5~7周,需要根据复杂度评估 |
| 5 |
生成割接 |
1~2周 |
5、迁移详细方案

5.1. 现状分析及需求分析
5.2. 迁移方案设计
用户根据自身现有 RedShift数据量、QPS、TPS 等性能指标、高可用需求和未来业务增长需求,制定合理化的迁移方案。
5.3. 资源规划
用户需要准备好 MaxCompute 的相关环境,同时获取到对应需要使用的迁移工具。迁移工具的相关内容请参考《 RedShift到MaxCompute迁移工具介绍 》 章节。
5.4. 改造及测试验证
5.4.1. 改造
迁移工具可以利用MaxCompute studio(或者DataWorks新建sql节点)客户端语法校验,新建一个sql文件,如图不支持的语法会报红
MaxCompute Studio安装文档https://help.aliyun.com/document_detail/50889.html

5.4.1.1. 建表
在RedShift中获取表列表和表字段定义,按照Maxcompute支持的字段值进行转换,对于有update和delete语句的表必须建成Transactional表
类型转化参考《数据类型对比及类型转化》章节
建表语法
--创建新表。
create [external] table [if not exists]
[( [not null] [default ] [comment ], ...)]
[comment ]
[partitioned by ( [comment ], ...)]
--用于创建聚簇表时设置表的Shuffle和Sort属性。
[clustered by | range clustered by ( [, , ...]) [sorted by ( [asc | desc] [, [asc | desc] ...])] into buckets]
--仅限外部表。
[stored by StorageHandler]
--仅限外部表。
[with serdeproperties (options)]
--仅限外部表。
[location ]
--指定表为Transactional表,后续可以对该表执行更新或删除表数据操作,但是Transactional表有部分使用限制,请根据需求创建。
[tblproperties("transactional"="true")]
[lifecycle ];
--基于已存在的表创建新表并复制数据,但不复制分区属性。
create table [if not exists] [lifecycle ] as ;
--基于已存在的表创建具备相同结构的新表但不复制数据。
create table [if not exists] like [lifecycle ];
说明:
- 表名与列名均对大小写不敏感。
- 在创建表时,如果不指定 if not exists选项而存在同名表,则返回报错;若指定此选项,则无论是否存在同名表,即使原表结构与要创建的目标表结构不一致, 均返回成功。已存在的同名表的元信息不会被改动。
- 表名、列名中不能有特殊字符,只能用英文的 a-z、A-Z 及数字和下划线(_),
且以字母开头,名称的长度不超过 128 字节。
- tblproperties("transactional"="true"):可选(有update和delete语句必须设置)。设置表为Transactional表。后续可以对Transactional表执行update、delete操作实现行级更新或删除数据。更多信息,请参见更新或删除数据(UPDATE | DELETE)。
- Partitioned by 指定表的分区字段,目前仅支持 string类型。分区值不可以有双字节字符(如中文),必须是以英文字母 a-z、A-Z开始后可跟字母数字,名称的长度不超过 128 字节。允许的字符包括:空格、冒号(:)、下划线(_)、美元符$)、井号(#)、点(.)、感叹号(!)和@,出现其他字符行为未定义, 例如:“\t”、“\n”、“/”等。当利用分区字段对表进行分区时,新增分区、更新分区内数据和读取分区数据均不需要做全表扫描,可以提高处理效率。
- 注释内容是长度不超过 1024 字节的有效字符串。
- lifecycle 指明此表的生命周期,单位:天。create table like 语句不会复制源表
的生命周期属性。
- 理论上源表分区最多只能 6 级,但考虑极限存储的分区膨胀方式,请尽可能少用
分区。
- 一个表允许的分区个数支持按照具体的 project 配置,默认 60000 个。
- 在create table ... as select ...语句中,如果在 select 子句中使用常量作为列的
值,建议指定列的名字。
- 如果希望源表和目标表具有相同的表结构,可以尝试使用 create table ... like 操
作。
5.4.1.1.1建表具体案例
- 列名双引号要去掉
- 形如BIGINT primary key identity(1,1)主键⾃增列要去掉,只保留默认值default 1
- numeric数据类型要转为decimal
- 形如::character varying,'1900/01/01'::text这种,两个冒号及后⾯内容要删除,MC不⽀持
- 形如"n_car_no" numeric DEFAULT -1::numeric,MC不⽀持默认值为-1,需要去掉
- 形如"ts_req_time" timestamp without time zone DEFAULT to_timestamp('1900/00/00 00:00:00'::text, 'YYYY-MM-DD HH24:MI:SS.MS'::text),需要去掉timezone,并改为timestamp DEFAULT timestamp "1900-01-01 00:00:00"
- 形如INTERLEAVED SORTKEY(vc_trans_id),MC不⽀持交错排序列功能,可以考虑替换为 zorder。
- MC不⽀持时区time zone,有关time zone的需要删除。
- 物化视图修改去掉 AUTO REFRESH YES,同时MaxCompute物化视图不支持窗口函数
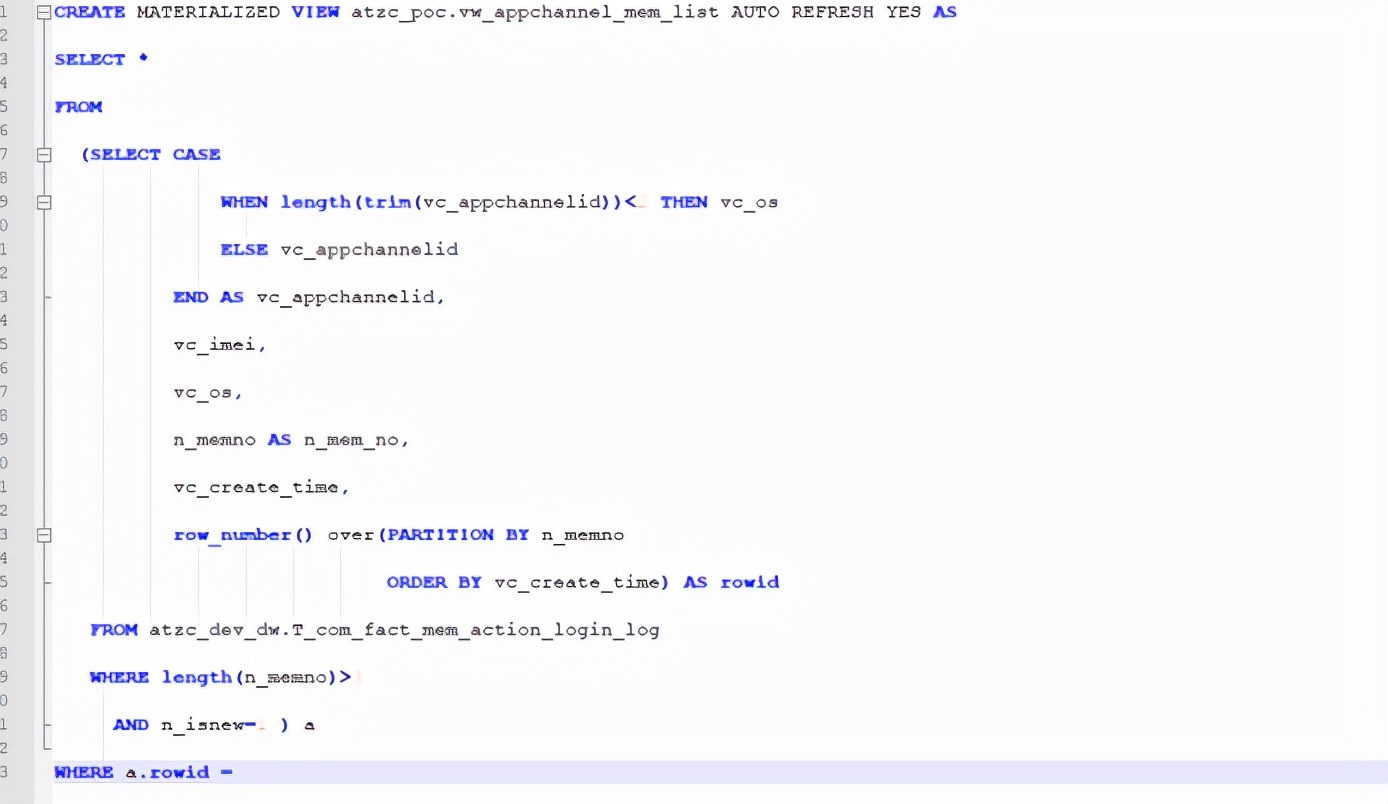
5.4.1.2. SQL 迁移
SQL 迁移实际上就是根据 Oracle 和MaxCompute 两者间 SQL 的差异进行转化,将RedShift中的 SQL 转化成 MaxCompute 中的 SQL,从而使 SQL 可用。具体的 SQL间差异请参考《迁移前RedShift于MaxCompute的各项对比差异》 章节中的相关内容
5.4.1.2.1 SQL 迁移 具体案例
DML语句
1.执行updae或者delet的语句需要创建事务表("transactional"="true")
2. 形如COMMENT ON column atzc_dev_dw.t_com_fact_auto_pay_gw_trans_pay_gw."n_trans_amt" is 'dml';给列添加 注释,需要改为MC⽀持的语法alter table change column comment '';
DQL语句
| 问题现象 |
迁移指导 |
|
| cte(with)语句 |
with语句写在insert into下面语法解析报错 |
with语句移动到insert into上面 |
|
MC不支持嵌套的with 需要将with拿出来 |
with a as () , b as () |
|
| 类型转化 |
redshift都使用的是 :: 如:a::date |
使用cast(a as date) |
| 正常匹配 |
redshift使用的是 ~ |
使用rlike替换 |
| group by |
redshift group by中的整型常量会被当做select的列序号处理 如:group by 1,2. |
SQL语句设置了属性,即set odps.sql.groupby.position.alias=true;一起提交 |
| 类型转化 :: |
redshift ::代表类型转化 |
使用cast函数转化 |
| 数据类型 |
varchar |
需要指定位数varchar(100)或者直接指定string |
| decimal 类型常量1 |
改成1bd |
|
| smallint 常量 |
1s |
|
| join |
join的不等值 |
mc不支持普通join不等值表达式,可以使用mapjoin |
内建函数
| RedShift |
MaxCompute |
RS举例 |
MC举例 |
| 多行注释/* xxxxx */ |
框选所需注释内容,ctrl+/,进行注释 |
||
| DATEADD( datepart, interval, {date|time|timetz|timestamp} ) |
datetime dateadd(date|datetime|timestamp <date>, bigint <delta>, string <datepart>) |
dateadd(day,1,f.dt_date) |
dateadd(f.dt_date,1,'dd') |
| DATEDIFF ( datepart, {date|time|timetz|timestamp}, {date|time|time|timestamp} ) |
bigint datediff(date|datetime|timestamp <date1>, date|datetime|timestamp <date2>, string <datepart>) |
datediff(min,a,b) |
datediff(b,a,'mi') |
| current_date-n/current_date+n |
dateadd(GETDATE(),n) dateadd可以加减时间,getdate可以获取当前时间 |
current_date-1 |
dateadd(GETDATE(),1,'dd') |
| 类型转化 :: |
cast转 |
a::date |
cast(a as date) |
| 正则 ~ |
rlike |
||
| 日期加减current_date+30 |
date_add(current_date(),30) |
||
| CEILING 或 CEIL 函数用于将数字向上舍入到下一个整数。 |
ceil |
select ceiling(commission) |
select ceil(1.1); |
| TO_TIMETAMP 将时间戳字符串转换为时间标记 |
bigint unix_timestamp(datetime <date>) |
to_timestamp('1900/00/00 00:00:00'as string, 'YYYY-MM-DD HH24:MI:SS.MS'as string) |
unix_timestamp(cast ("1900-00-00 00:00:00" as datetime)) |
| dateadd按指定的时间间隔递增日期、时间、时间或时间戳值 |
datetime dateadd(date|datetime|timestamp <date>, bigint <delta>, string <datepart>) |
dateadd(month,-6,a.dt_end_date) |
dateadd(a.dt_end_date,-6,"mm") |
| LISTAGG 聚合函数根据 ORDER BY 表达式对该组的行进行排序,然后将值串联成一个字符串 |
wm_concat(string <separator>, string <colname>) |
listagg(remark) |
wm_Concat(",",remark) |
| CURRENT_DATE获取当前日期 |
CURRENT_DATE() MaxCompute需要添加括号 |
||
| EXTRACT(week from $1)提取函数从 TIMESTAMP 值或表达式 |
weekofyear() |
||
| EXTRACT(weekday from $1) 和 extract(DOW from $1) |
weekday($1) |
||
| DATEPART(WEEKDAY,T3.dt_report) |
WEEKDAY(cast(T3.dt_report as DATETIME)) |
||
| LEN 函数返回一个整数,表示输入字符串中的字符的数量 |
bigint length(string <str>) |
len |
length |
| LOWER 函数返回与输入字符串具有相同数据类型的字符串 |
tolower(string <source>) |
lower |
|
| CONVERT ( TIMESTAMP, id_card_back_overdue) 函数将值从一种数据类型转换为另一种数据类型 |
转为cast() |
CONVERT ( TIMESTAMP, id_card_back_overdue) |
cast(id_card_back_overdue as TIMESTAMP) |
| sysdate返回当前会话时区(默认为 UTC)中的当前日期和时间 |
getdate() 返回DATETIME ‘2017-11-11 00:00:00’ |
||
| charindex() 返回指定子字符串在字符串中的位置 |
INSTR() |
charindex('fish', 'dogfish') |
instr('dogfish','fish') |
| left()这些函数返回指定数量的位于字符串最左侧 |
substr() |
||
| right()这些函数返回指定数量的位于字符串最右侧 |
reverse(substr(reverse())) |
||
| DATE_TRUNC 函数根据您指定的日期部分(如小时、周或月)截断时间戳表达式或文字 date_trunc('month') |
datetrunc(,'month') |
||
| json_extract_path_text 函数返回键:Value对引用 JSON 字符串中的一系列路径元素 |
改为get_json_object写法get_json_object(content,'$.DeviceID') |
根据key路径获取json字符串的value |
json_extract_path_text('{"f2":{"f3":1},"f4":{"f5":99,"f6":"star"}}','f4', 'f6') |
| json_extract_array_element_text |
使用atzc_dev_dw.json_extract_array_element_text |
根据索引返回数组元素 |
json_extract_array_element_text('[111,112,113]', 2) |
| POSITION返回指定子字符串在字符串中的位置 |
改成:instr |
||
| BTRIM 函数通过删除前导空格和尾随空格或删除 |
TRIM maxCompute只能删除左右空格不能删除指定位置空格,删除指定位置需要自己写udf实现 |
||
| date_part()从表达式中提取日期部分值 |
datepart() |
||
| mod() 函数返回一个数字结果 |
$1%$2 |
||
| ~~ |
like |
||
| date_part(w,time) |
weekofyear() |
5.4.1.2存储过程迁移
建议改成临时表或者pyodps的方式
5.4.2数据迁移
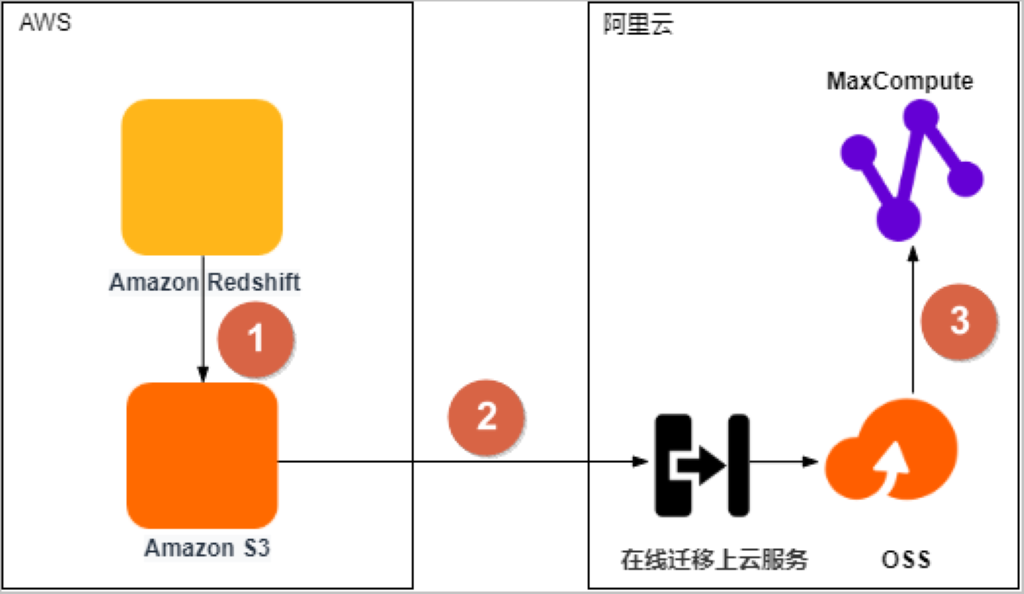
| 序号 |
描述 |
| ① |
将Amazon Redshift数据导出至Amazon S3数据湖(简称S3)。 |
| ② |
通过对象存储服务OSS的在线迁移上云服务,将数据从S3迁移至OSS。 |
| ③ |
将数据从OSS迁移至同区域的MaxCompute项目中,并校验数据完整性和正确性。 |
数据迁移参考文档:
https://help.aliyun.com/document_detail/181920.html
5.4.3. 测试验证
目前RedShift到MaxCompute 迁移的数据测试验证工作,还没有工具可以支持,需要
自行编写脚本工具完成,常用校验方案有如下几种:
- 表结构校验,从 RedShift和MaxCompute 分别导出数据表列及类型定义后计算
md5 进行校验
- 数据表行数比对,执行 SQL 语句分别在 RedShift和MaxCompute 统计相同表的
数据行数进行逐行比对
- 数据全量校验,一般用于核心表且数据量较小的校验场景,导出全量数据计算
md5 进行校验,或全量数据分段计算 md5 进行校验
- 数据抽样校验,一般用于核心大表的数据校验场景,按一定抽样规则从源和目标
抽取数据进行校验。
原文链接:http://click.aliyun.com/m/1000305755/
本文为阿里云原创内容,未经允许不得转载。