爬取全国大学排名 用pyecharts进行可视化
院校网址:http://college.gaokao.com/schlist/p
F12 先找到对应的全部list
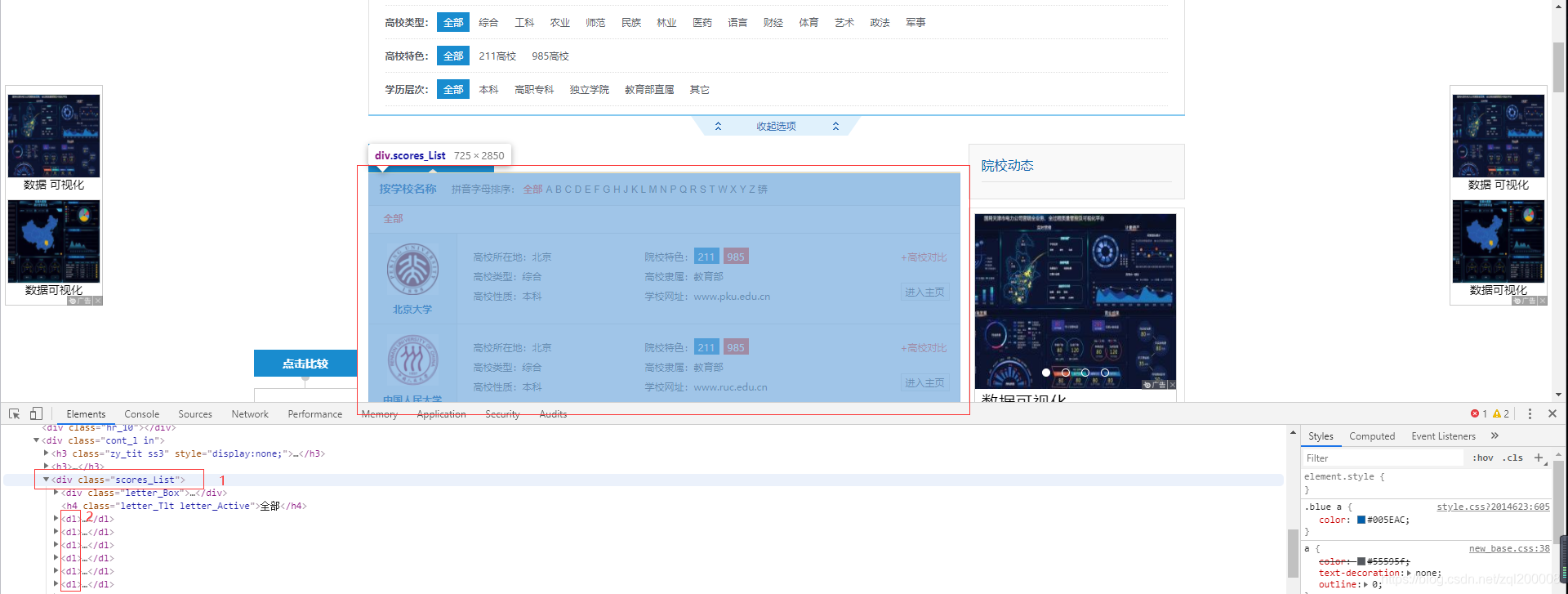
需要先安装requests,lxml
可直接用 pip install requests pip install lxml 命令安装
导入需要的相关包
import requests
from lxml import etree
import time
import random
import csv
#避免网页反爬虫
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
url = 'http://college.gaokao.com/schlist/p'
response = requests.get(url,headers=headers)
time.sleep(random.randint(0,2)) #同样用于反爬虫
再调用 lxml 获取到整页的学校名称
selector = etree.HTML(response.text)
all_list = selector.xpath('//*[starts-with(@class,"scores_List")]/dl') #页面中全部学校 全部dl列
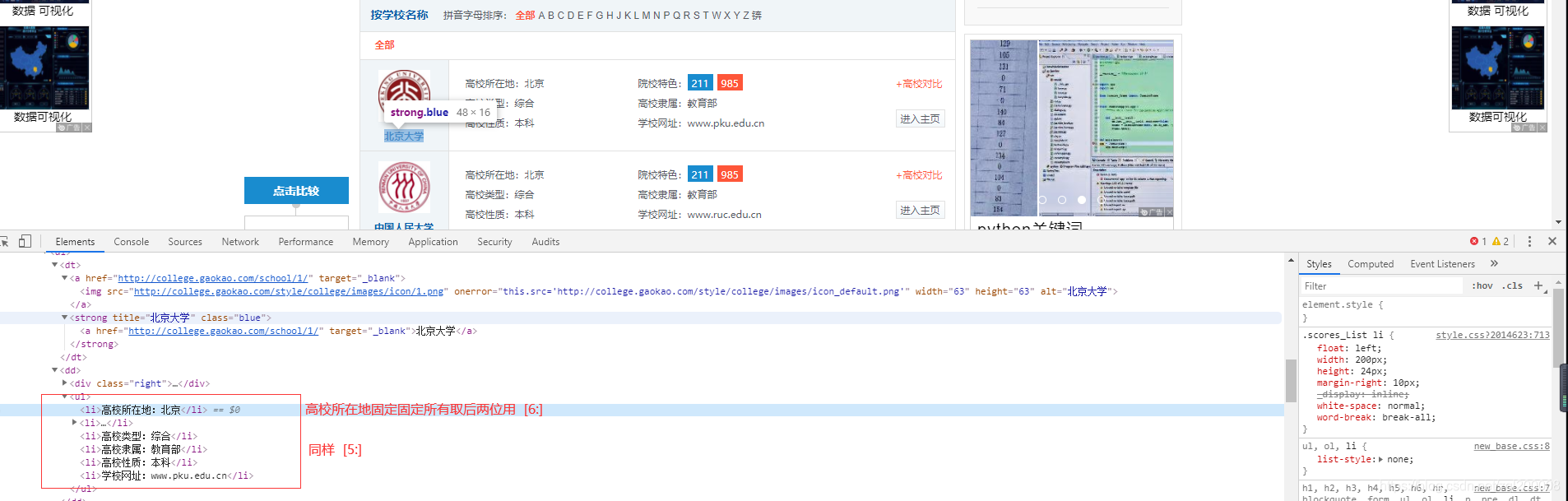
调用 for 循环获取dl中所有需要的数据
for sel in all_list:
name = sel.xpath('dt/strong/a/text()')[0] #学校名称
place = sel.xpath('dd/ul/li[1]/text()')[0][6:] #高校所在地
type = sel.xpath('dd/ul/li[3]/text()')[0][5:] #高校类型
nature = sel.xpath('dd/ul/li[5]/text()')[0][5:] #高校性质
try: #获取的数据院校特色有地方空缺为避免出现空缺无法爬取数据
tese = sel.xpath('string(dd/ul/li[2])')[5:] #院校特色
except:
tese='' #遇到空缺值让院校特色等于null
lishu = sel.xpath('dd/ul/li[4]/text()')[0][5:] #高校隶属
最后将爬取的数据保存(保存成CSV文件格式)
with open('school.csv','a',encoding='gbk',newline='')as file:
writer = csv.writer(file)
try:
writer.writerow(item)
except Exception as e:
print(e)
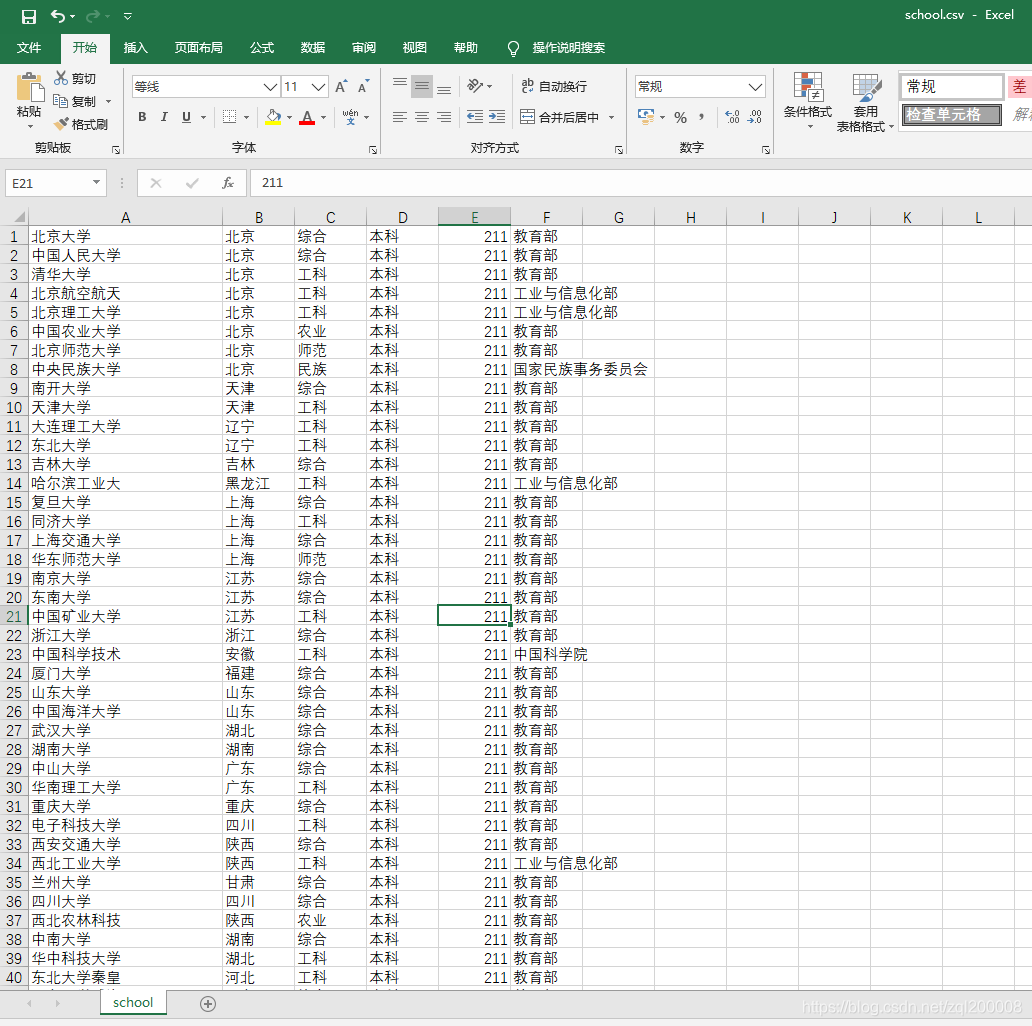
爬取的部分内容如下
最后用函数将全部代码串接
附上完整代码
import requests
from lxml import etree
import time
import random #用于反爬 产生随机数
import csv
def csv_writer(item):
with open('school.csv','a',encoding='gbk',newline='')as file: #newline='' 保证写入到CSV中不空行
writer = csv.writer(file)
try:
writer.writerow(item)
except Exception as e:
print(e)
def spider(url_):
time.sleep(random.randint(0,2)) # 同样用于反爬虫
res = requests.get(url_,headers=headers)
return etree.HTML(res.text)
def parse(list_url):
selector = spider(list_url)
all_list = selector.xpath('//*[starts-with(@class,"scores_List")]/dl') #页面中全部学校 全部dl列
for sel in all_list:
try:
name = sel.xpath('dt/strong/a/text()')[0] #学校名称
except:
name = ''
place = sel.xpath('dd/ul/li[1]/text()')[0][6:] #高校所在地
type = sel.xpath('dd/ul/li[3]/text()')[0][5:] #高校类型
nature = sel.xpath('dd/ul/li[5]/text()')[0][5:] #高校性质
try: #获取的数据院校特色有地方空缺为避免出现空缺无法爬取数据
tese = sel.xpath('string(dd/ul/li[2])')[5:] #院校特色
except:
tese='' #遇到空缺值让院校特色等于null
lishu = sel.xpath('dd/ul/li[4]/text()')[0][5:] #高校隶属
# print(name,place,type,nature,tese,lishu)
csv_writer([name,place,type,nature,tese,lishu])
#避免网页反爬虫
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
url_ = 'http://college.gaokao.com/schlist/p'
all_url = [url_ + str(i) for i in range(1,107)] #提取到所有学校的全部网址
for url in all_url:
parse(url)
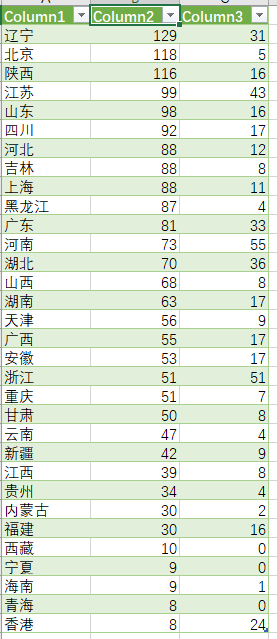
*为了方便观看爬取到情况将爬取的文件进行整合并进行可视化
**整合内容如下:*Column2:本科数 Column3:专科数
1、柱状图
from pyecharts.charts import Bar
from pyecharts import options as opts
import pandas as pd
datafile = r'D:/Program Files/Tencent/QQ/QQ/out2/school.xlsx'
data = pd.read_excel(datafile)
x1 = data['Column1'].tolist() #变成列表形式
y1 = data['Column2'].tolist()
y2 = data['Column3'].tolist()
# 更新后有两种调用方法 不习惯链式调用依旧可以单独调用方法
# 链式调用 V1版本要求>=1.0
bar = (
Bar()
.add_xaxis(x1)
.add_yaxis("本科",y1)
.add_yaxis("专科",y2)
.set_global_opts(title_opts=opts.TitleOpts(title="大学",subtitle="情况"))
)
bar.render(path='bar.html')
# 单独调用
bar = Bar()
bar.add_xaxis(x1)
bar.add_yaxis("本科",y1)
bar.add_yaxis("专科",y2)
bar.set_global_opts(title_opts=opts.TitleOpts(title="大学",subtitle="情况"))
bar.render(path='bar.html')
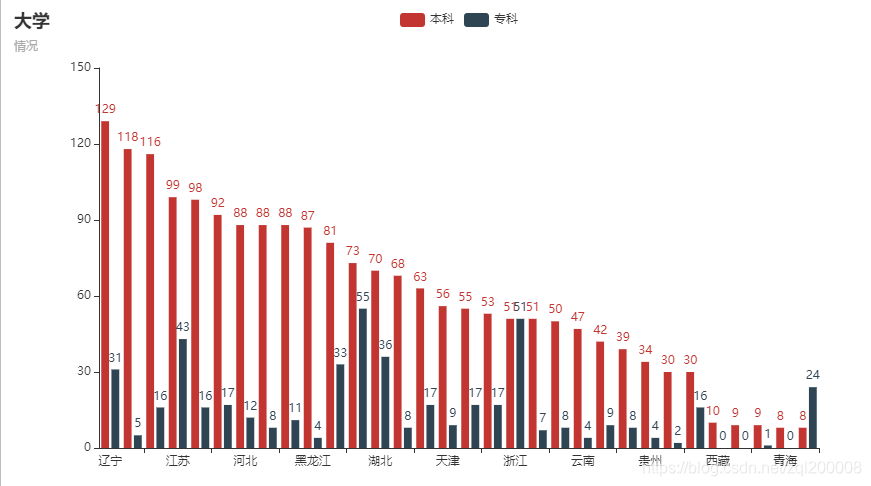
2、前十条形图
from pyecharts.charts import Line
import pandas as pd
from pyecharts import options as opts
datafile = r'D:/Program Files/Tencent/QQ/QQ/out2/school.xlsx'
data = pd.read_excel(datafile)
encoding='utf-8'
x1 = data['Column1'].tolist()[:10]
y1 = data['Column2'].tolist()[:10]
y2 = data['Column3'].tolist()[:10]
# 单独调用
line = Line()
line.add_xaxis(x1)
line.add_yaxis("本科",y1)
line.add_yaxis("专科",y2)
line.set_global_opts(title_opts=opts.TitleOpts(title="前十"))
line.render(path='line.html')
# 链式调用
line = (
Line()
.add_xaxis(x1)
.add_yaxis("本科",y1)
.add_yaxis("专科",y2)
.set_global_opts(title_opts=opts.TitleOpts(title="前十"))
)
line.render(path='line.html')
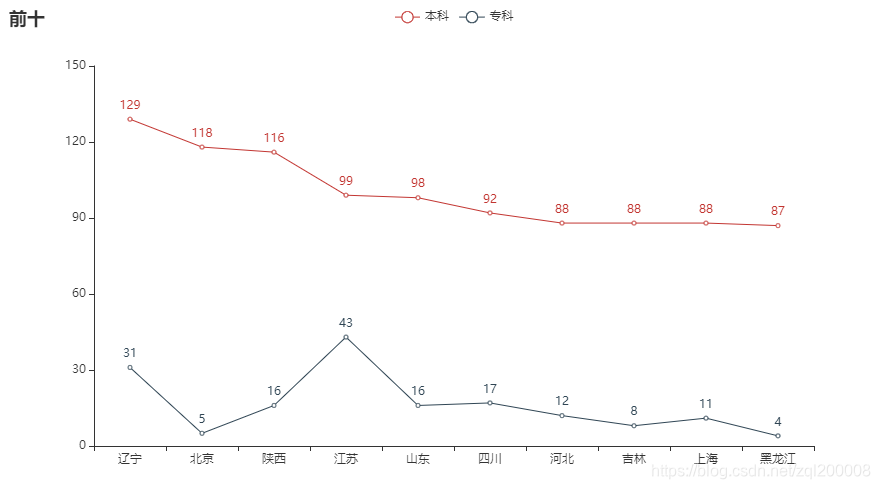
3、高校数前十名 环形图
from pyecharts.charts import Pie
import pandas as pd
from pyecharts import options as opts
datafile = r'D:/Program Files/Tencent/QQ/QQ/out2/school.xlsx'
data = pd.read_excel(datafile)
# 高校数量前十名
# 单独调用
pie = Pie()
pie.add("", [list(z) for z in zip(data['Column1'].values.tolist()[:10], data['Column2'].values.tolist()[:10])],
radius=["30%", "75%"],
center=["40%", "50%"],
rosetype="radius")
pie.set_global_opts(
title_opts=opts.TitleOpts(title="高校数量前十名"),
legend_opts=opts.LegendOpts(
type_="scroll", pos_left="80%", orient="vertical"
)
)
pie.render('高校数量前十名.html')
# 链式调用
pie =(
Pie()
.add("", [list(z) for z in zip(data['Column1'].values.tolist()[:10], data['Column2'].values.tolist()[:10])],
radius=["30%", "75%"],
center=["40%", "50%"],
rosetype="radius")
.set_global_opts(
title_opts=opts.TitleOpts(title="高校数量前十名"),
legend_opts=opts.LegendOpts(
type_="scroll", pos_left="80%", orient="vertical"
)
)
)
pie.render('高校数量前十名.html')
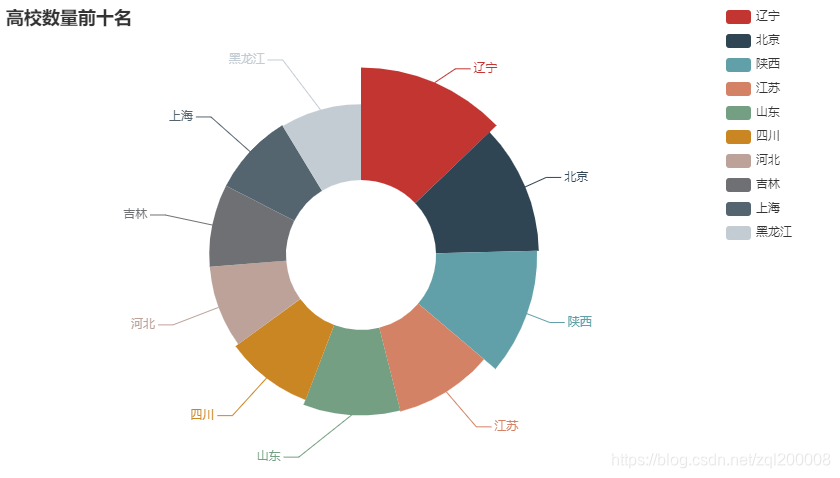
4、散点图
import pyecharts.options as opts
from pyecharts.charts import Scatter
import pandas as pd
datafile = r'D:/Program Files/Tencent/QQ/QQ/out2/school.xlsx'
data = pd.read_excel(datafile)
x1 = data['Column1'].tolist()[:10]
y1 = data['Column2'].tolist()[:10]
y2 = data['Column3'].tolist()[:10]
#单独调用方法
scatter = Scatter()
scatter.add_xaxis(x1)
scatter.add_yaxis('本科',y1)
scatter.add_yaxis('专科',y2)
scatter.set_global_opts(title_opts=opts.TitleOpts(title="高校"))
scatter.render(path='scatter.html')
# 链式调用 效果和单独调用一样 但更方便观看
scatter = (
Scatter()
.add_xaxis(x1)
.add_yaxis('本科',y1)
.add_yaxis('专科',y2)
.set_global_opts(title_opts=opts.TitleOpts(title="高校"))
)
scatter.render(path='scatter.html')
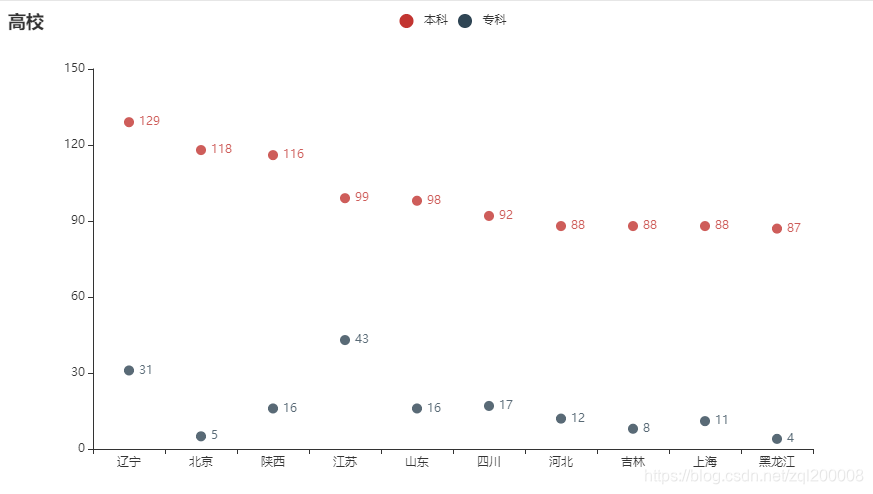
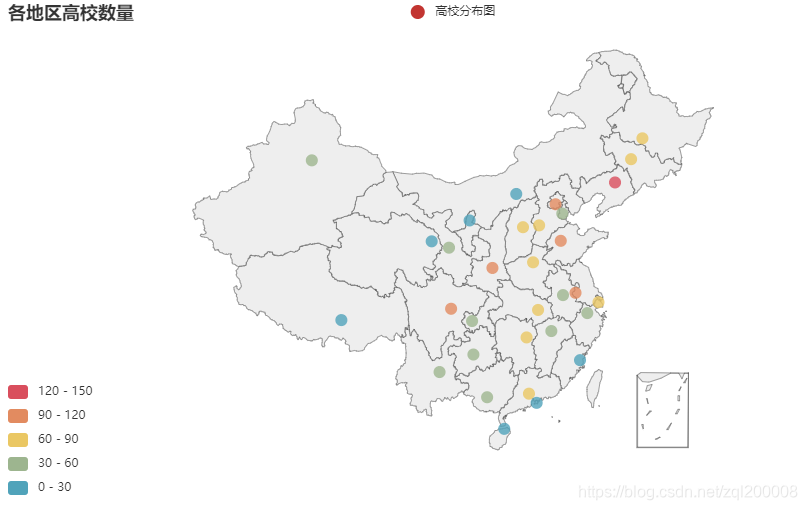
5、Geo
from pyecharts.charts import Geo
import pandas as pd
from pyecharts import options as opts
datafile = r'D:/Program Files/Tencent/QQ/QQ/out2/school.xlsx'
data = pd.read_excel(datafile)
# 单独调用
geo = Geo()
geo.add_schema(maptype="china")
geo.add("高校分布图",[list(z) for z in zip(data['Column1'].values.tolist(), data['Column2'].values.tolist())])
geo.set_global_opts(visualmap_opts=opts.VisualMapOpts(is_piecewise=True,max_=150),
title_opts=opts.TitleOpts(title="各地区高校数量"))
geo.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
geo.render(path='geo.html')
# 链式调用
geo = (
Geo()
.add_schema(maptype="china")
.add("高校分布图",[list(z) for z in zip(data['Column1'].values.tolist(), data['Column2'].values.tolist())])
.set_global_opts(visualmap_opts=opts.VisualMapOpts(is_piecewise=True,max_=150),
title_opts=opts.TitleOpts(title="各地区高校数量"))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
geo.render(path='geo.html')
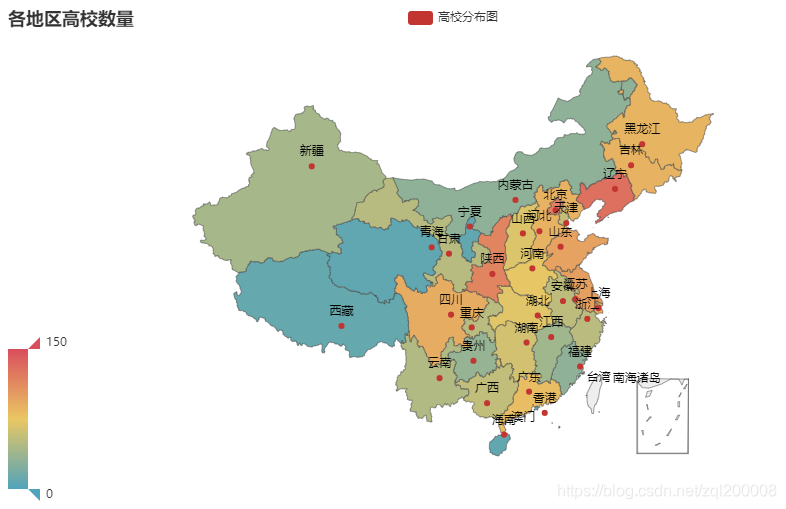
6、Map
from pyecharts.charts import Map
import pandas as pd
from pyecharts import options as opts
datafile = r'D:/Program Files/Tencent/QQ/QQ/out2/school.xlsx'
data = pd.read_excel(datafile)
# 单独调用
map = Map()
map.add("高校分布图",[list(z) for z in zip(data['Column1'].values.tolist(), data['Column2'].values.tolist())])
map.set_global_opts(visualmap_opts=opts.VisualMapOpts(max_=150),
title_opts=opts.TitleOpts(title="各地区高校数量"))
map.render(path='map.html')
# 链式调用
map = (
Map()
.add("高校分布图",[list(z) for z in zip(data['Column1'].values.tolist(), data['Column2'].values.tolist())])
.set_global_opts(visualmap_opts=opts.VisualMapOpts(max_=150),
title_opts=opts.TitleOpts(title="各地区高校数量"))
)
map.render(path='map.html')
7、词云图
from pyecharts.charts import WordCloud
from pyecharts import options as opts
import pandas as pd
datafile = r'D:/Program Files/Tencent/QQ/QQ/out2/school.xlsx'
data = pd.read_excel(datafile)
num = [10000,6181,4386,4005,4212,1212,15564,4845,1581,4511,151] #词大小size
words = list(data['Column1'][:10]) #调取前十个转换为列表
# print(type(words))
# print(type(num)) #查看类型
word = [(a,b)for a,b in zip(words,num)] #将num,words两个列表整合合并
# print(word)
# 链式调用
wordcloud = (
WordCloud()
.add('',word,word_size_range=[20,100])
.set_global_opts(title_opts=opts.TitleOpts(title="wordcloud"))
)
wordcloud.render(path="wordcloud.html")
# 单独调用
wordcloud = WordCloud()
wordcloud.add('',word,word_size_range=[20,100])
wordcloud.set_global_opts(title_opts=opts.TitleOpts(title="wordcloud"))
wordcloud.render(path="wordcloud.html")

