经过我的分析发现QS全球大学排名网页是通过Ajax进行加载的。
首先介绍一下Ajax:
AJAX = 异步 JavaScript 和 XML。
AJAX 是一种用于创建快速动态网页的技术。
通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
Ajax 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术,它并不是新的编程语言,而是一种使用现有标准的新方法。
这是要爬取的url(2018年的QS排名):
https://www.topuniversities.com/university-rankings/world-university-rankings/2018第一步,分析请求:
首先,打开Chrome里面的开发者工具,右键----检查----Network----XHR
点击检查:

点击Network:
点击XHR:

重新加载后,便会才采集到XHR数据
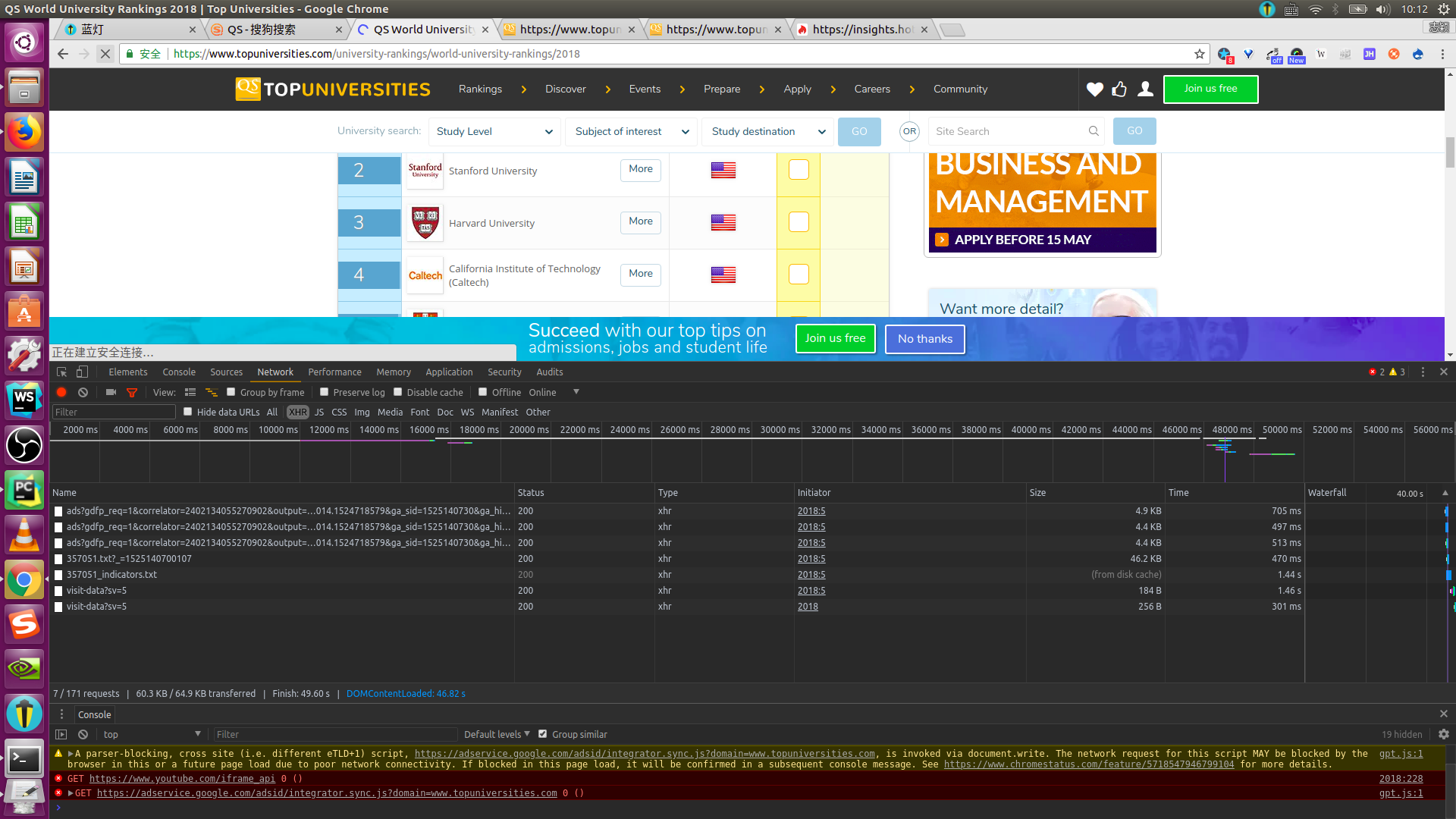
查看请求的具体数据:
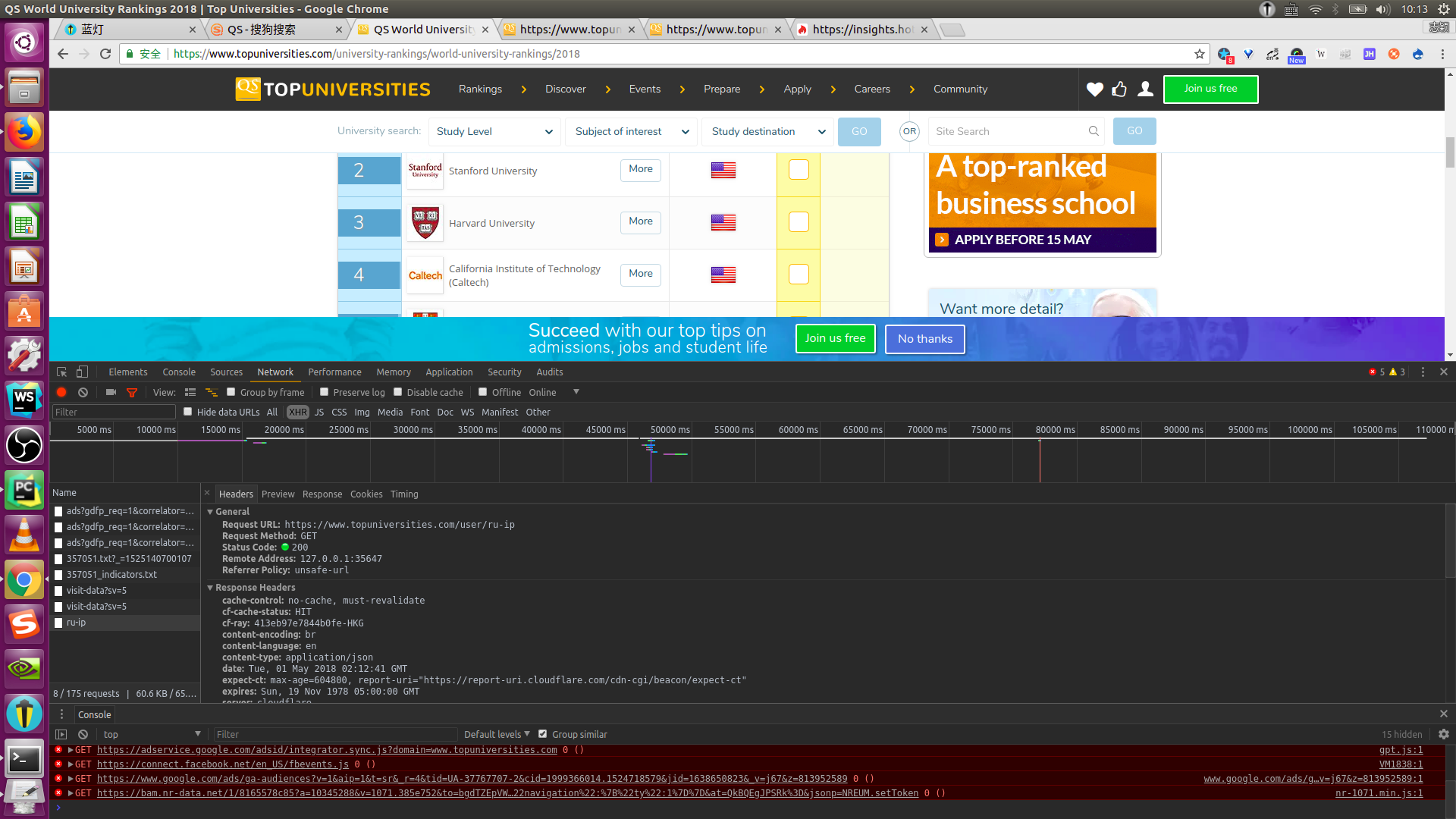
Headers里面是请求和响应的头。包括请求的url,请求的方式,响应的状态码等等。
Preview里面是请求之后服务器返回的内容。Response里面也是返回的内容。
通过分析我们知道第4个请求返回来的数据正是我要爬取的内容。

上面 是点击preview之后出现的内容。
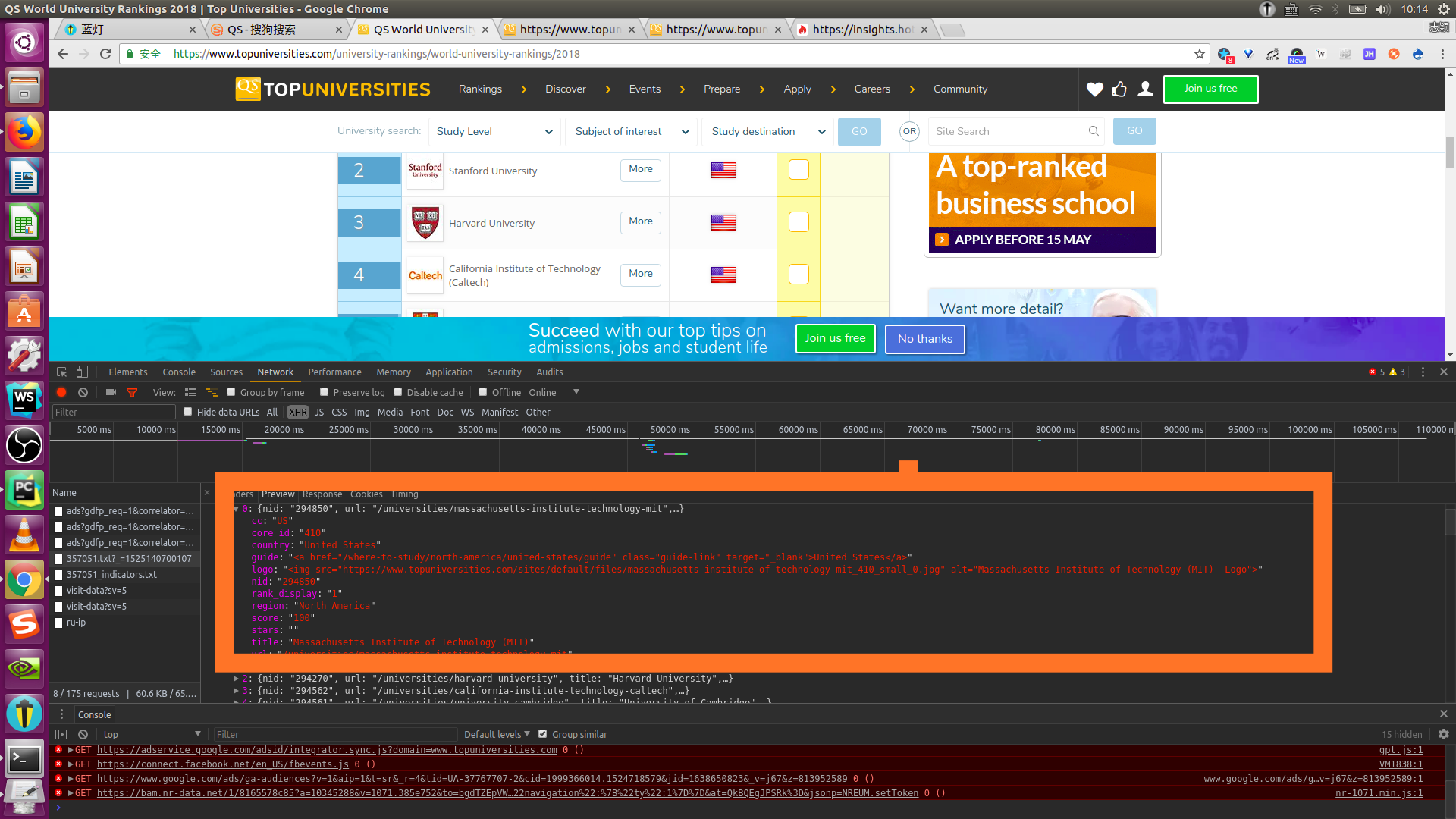
方框中的内容正是我们要爬取的内容,因此我们只需要爬取这些数据即可。
接下来,点击headers,我们找到它的url:
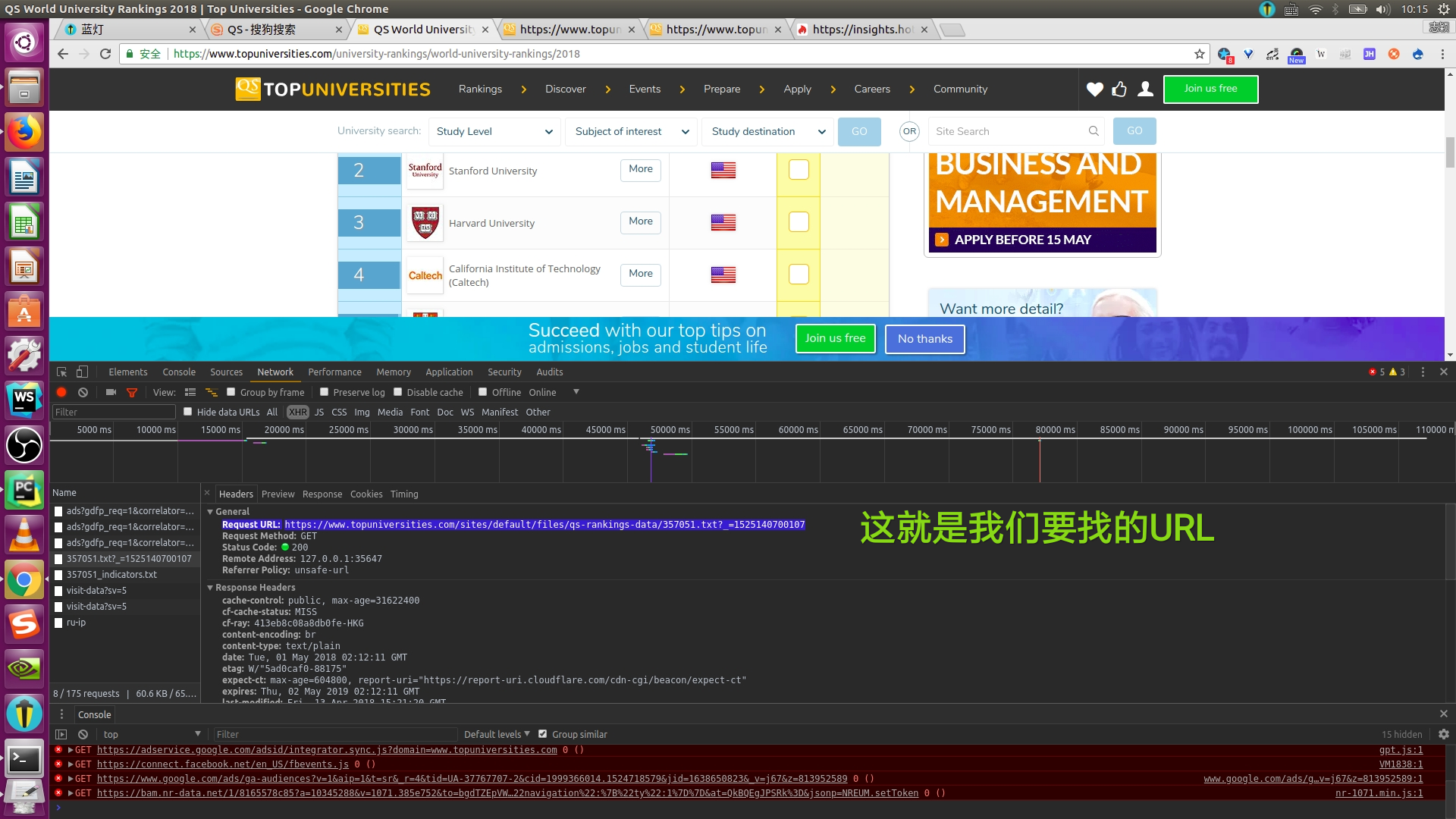
URL: https://www.topuniversities.com/sites/default/files/qs-rankings-data/357051.txt?_=1525140700107
找到url后,第二步就是获取这些数据。这里定义一个函数来获取数据:
# 获取数据
def get_page(url):
try:
r = requests.get(url, headers=headers)
if r.status_code == 200:
return r.json()
except requests.ConnectionError as e:
print(e)第三步,解析数据
# 解析数据
def parser_page(json):
if json:
items = json.get('data')
for i in range(len(items)):
item = items[i]
qsrank = {}
if "=" in item['rank_display']:
rk_str = str(item['rank_display']).split('=')[-1]
qsrank['rank_display'] = rk_str
else:
qsrank['rank_display'] = item['rank_display']
qsrank['title'] = item['title']
qsrank['region'] = item['region']
qsrank['score'] = item['score']
# url可根据需求提取
qsrank['url'] = item['url']
yield qsrank第四步,定义主函数
# 主函数
def main():
json = get_page(url)
results = parser_page(json)
for result in results:
with open(path, 'a') as f: # path 是文件要存储的地方
f.write('{:10}{:50}{:^88}{:>}\n'.format(result['rank_display'], result['title'], result['region'],
result['score']))
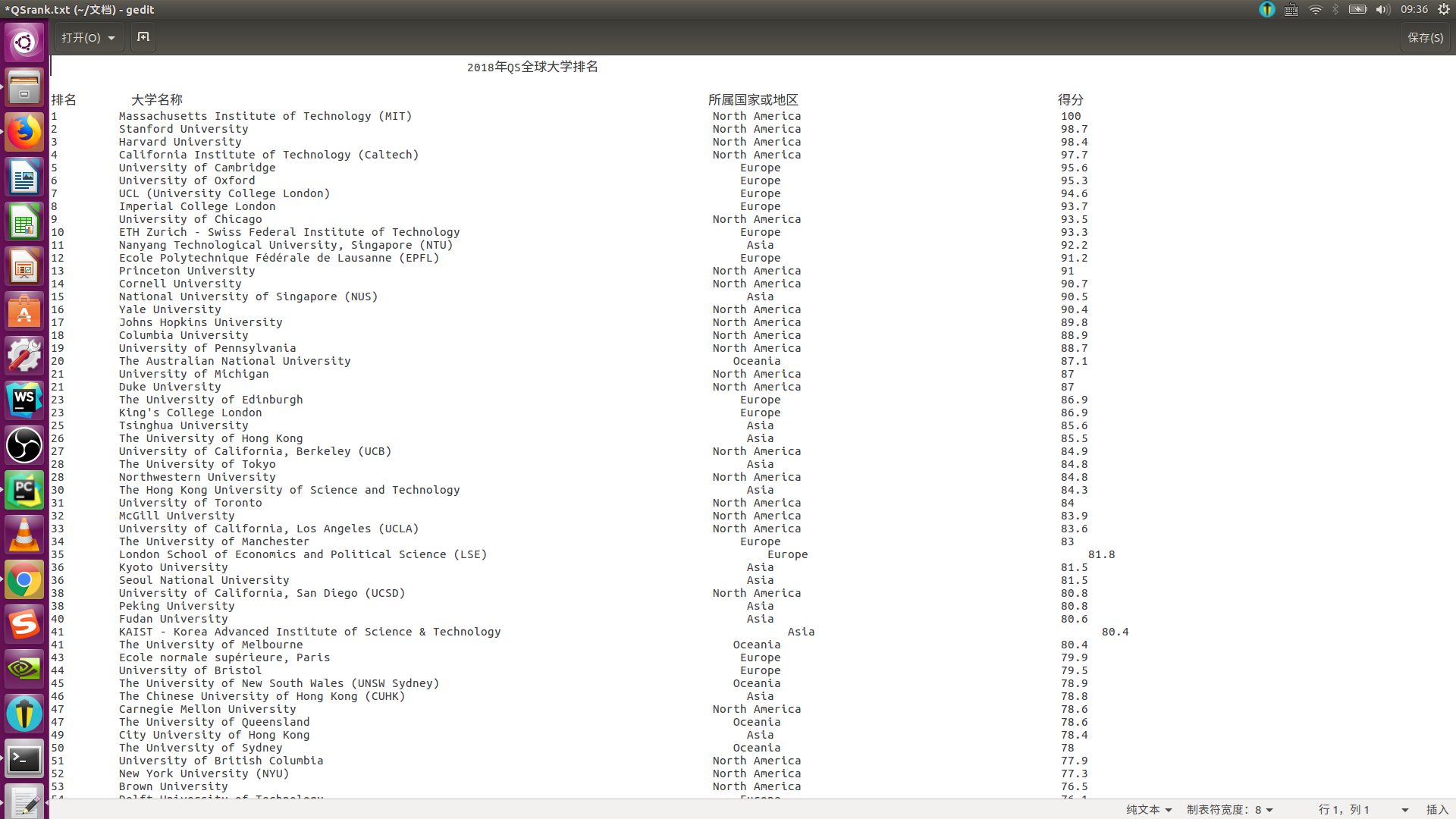
f.close()最后调用主函数即可,可以看到爬到的数据如下图:
至此,通过分析Ajax接口,用Python爬取QS全球大学排名的Python爬虫就完成了。