2018年中国大学排名爬虫
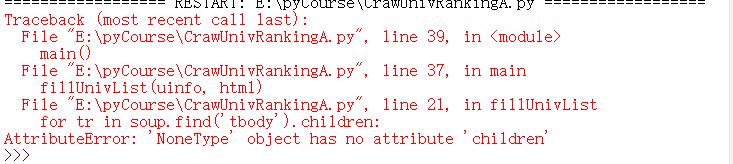
贴出报错图,如下:
爬虫代码如下:
#CrawUnivRankingB.py
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
def main():
uinfo = []
url = 'https://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()
报错的意思就是说:tobody没有孩子标签,我刚开始以为是前三个函数那里错了呢,后来并没有发现,然后百度一下,看了其他大佬们的相似情况,就又重头到尾看代码,发现是网址那里错了
https://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
改成:
http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
就可以运行了,如图:
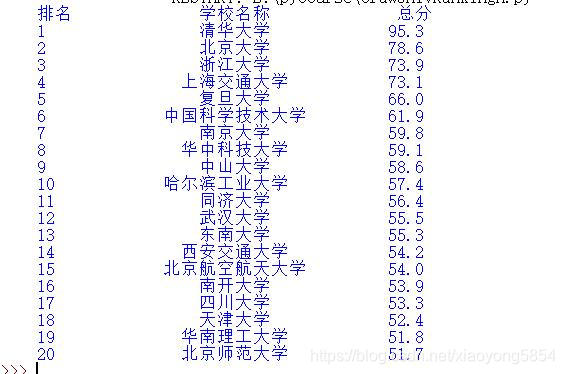
总结:
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
这行代码中t{1:{3}^10}的{3}是指format中的(chr12288),可以解决中文的空格填充,是字符串对齐。