将自己之前学习爬取新浪记录的内容分享一下吧!
透过pip安装套件
pip install openpyxl
pip install pandas -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip install requests
pip install BeautifulSoup4
pip install jupyter
jupyter notebook
查看能否爬取网页内容
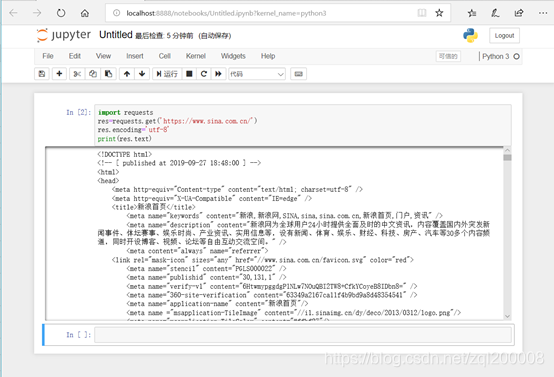
import requests
res = requests.get('https://www.sina.com.cn/')
res.encoding='utf-8'
print(res.text)
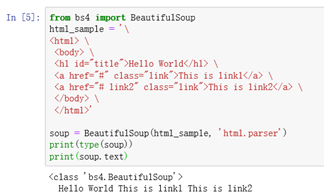
简单叙述关于BeautifulSoup使用
from bs4 import BeautifulSoup
html_sample = '\
<html> \
<body> \
<h1 id="title">Hello World</h1> \
<a href="#" class="link">This is link1</a> \
<a href="# link2" class="link">This is link2</a> \
</body> \
</html>'
soup = BeautifulSoup(html_sample, 'html.parser')
print(type(soup))
print(soup.text)
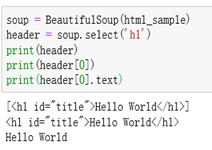
1、使用select找出含有h1标签的元素
soup = BeautifulSoup(html_sample)
header = soup.select(‘h1’)
print(header)
print(header[0]) #去掉两边[]
print(header[0].text)#取出文本
2、使用select找出含有a标签的元素
soup = BeautifulSoup(html_sample)
alink = soup.select(‘a’)
print(alink)
for link in alink:
print(link) #分开取出
print(link.text) #分开取出文字

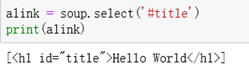
3、使用select找出所有id为title的元素(id前面需加#)
alink = soup.select(‘#title’)
print(alink)
4、使用select找出所有class为link的元素(class前面需加 . )
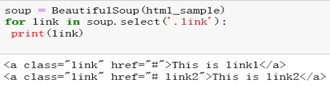
soup = BeautifulSoup(html_sample)
for link in soup.select(‘.link’):
print(link)
5、使用select找出所有a tag的href连接
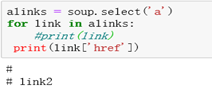
alinks = soup.select(‘a’)
for link in alinks:
print(link[‘href’])
下面就开始进入正题爬取新浪网页内容
import requests
from bs4 import BeautifulSoup
res = requests.get('https://news.sina.com.cn/world/')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
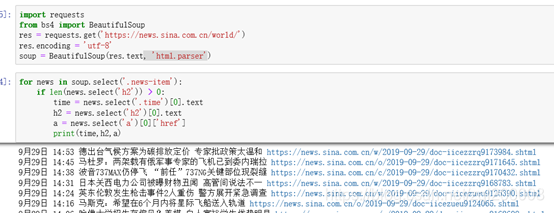
for news in soup.select('.news-item'):
if len(news.select('h2')) > 0:
time = news.select('.time')[0].text #编撰时间
h2 = news.select('h2')[0].text #文章标题
a = news.select('a')[0]['href'] #网址
print(time,h2,a)
抓取单个内文页面
import requests
from bs4 import BeautifulSoup
# 网址为上文抓取到的URL中截取的一个
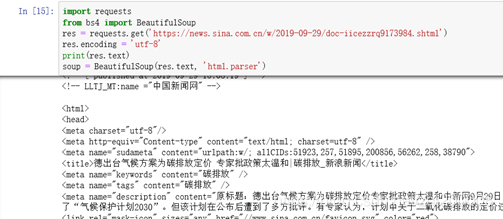
res = requests.get('https://news.sina.com.cn/w/2019-09-29/doc-iicezzrq9173984.shtml')
res.encoding = 'utf-8'
print(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
抓取内文标题
soup.select('.main-title')[0].text
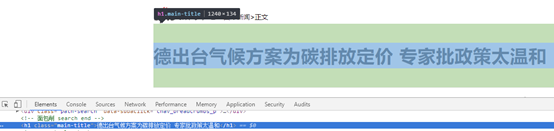

抓取内文时间
soup.select('.date-source')[0].contents[1].text

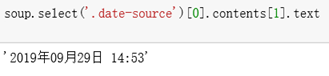


转换时间格式
from datetime import datetime
datetime.strptime(datesource,'%Y年%m月%d日 %H:%M')
dt.strftime('%Y-%m-%d')
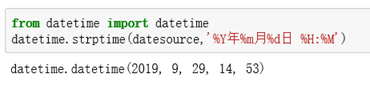
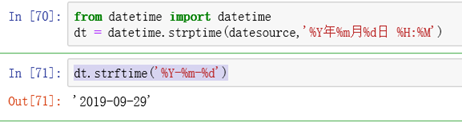
抓取信息来源
soup.select('.date-source a')[0].text

整理新闻内文
article = []
for p in soup.select('#article p')[:-1]:
article.append(p.text.strip()) #strip()清除左右空白
print(article)
'@'.join(article)
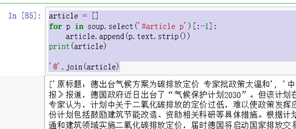
[p.text.strip() for p in soup.select('#article p')[:-1]]

编撰人信息
soup.select('.show_author')[0].text.strip('责任编辑:')

总和抓取
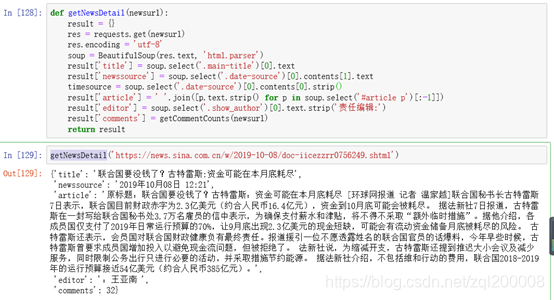
def getNewsDetail(newsurl):
result = {}
res = requests.get(newsurl)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
result['title'] = soup.select('.main-title')[0].text
result['newssource'] = soup.select('.date-source')[0].contents[1].text
timesource = soup.select('.date-source')[0].contents[0].strip()
result['article'] = ' '.join([p.text.strip() for p in soup.select('#article p')[:-1]])
result['editor'] = soup.select('.show_author')[0].text.strip('责任编辑:')
result['comments'] = getCommentCounts(newsurl)
return result
getNewsDetail('https://news.sina.com.cn/w/2019-10-08/doc-iicezzrr0756249.shtml')
抓取评论数
import requests
comment = requests.get('https://comment.sina.com.cn/page/info?version=1&\
format=json&channel=gj&newsid=comos-icezzrr0689279&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1&\
page_size=3&t_size=3&h_size=3&thread=1')
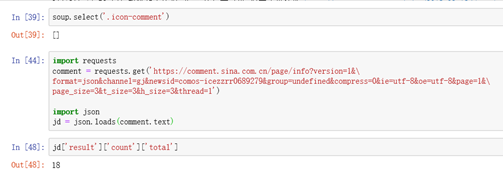
import json
jd = json.loads(comment.text)
jd['result']['count']['total']
取得新闻编号

[{“metadata”:{“trusted”:true},“cell_type”:“code”,“source”:“newsurl = ‘https://news.sina.com.cn/w/2019-10-08/doc-iicezzrr0689279.shtml’\nnewsid = newsurl.split(’/’)[-1].rstrip(’.shtml’).lstrip(’.doc-i’)\nnewsid”,“execution_count”:57,“outputs”:[{“output_type”:“execute_result”,“execution_count”:57,“data”:{“text/plain”:"‘ezzrr0689279’"},“metadata”:{}}]}]
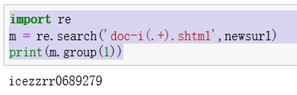
import re
m = re.search('doc-i(.+).shtml',newsurl)
print(m.group(1))
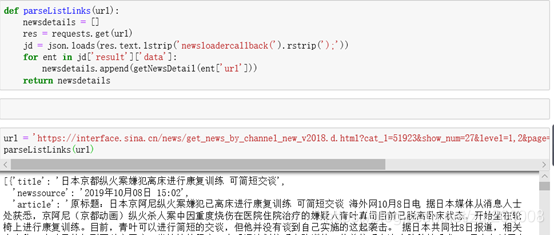
建立剖析清单链接函式
def parseListLinks(url):
newsdetails = []
res = requests.get(url)
jd = json.loads(res.text.lstrip('newsloadercallback(').rstrip(');'))
for ent in jd['result']['data']:
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails
url = 'https://interface.sina.cn/news/get_news_by_channel_new_v2018.d.html?cat_1=51923&show_num=27&level=1,2&page=2&callback=newsloadercallback&_=1570511398904'
parseListLinks(url)
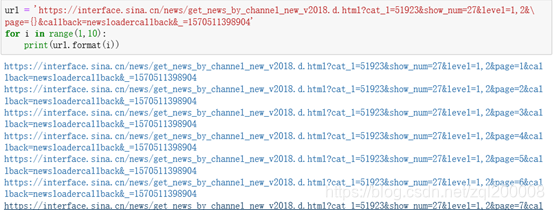
每页
url = ‘https://interface.sina.cn/news/get_news_by_channel_new_v2018.d.html?cat_1=51923&show_num=27&level=1,2&
page={}&callback=newsloadercallback&_=1570511398904’
for i in range(1,10):
print(url.format(i))
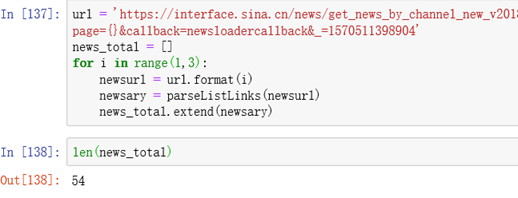
批次抓取每页
url = 'https://interface.sina.cn/news/get_news_by_channel_new_v2018.d.html?cat_1=51923&show_num=27&level=1,2&\
page={}&callback=newsloadercallback&_=1570511398904'
news_total = []
for i in range(1,3):
newsurl = url.format(i)
newsary = parseListLinks(newsurl)
news_total.extend(newsary)
len(news_total)
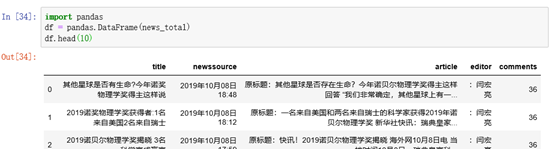
美观
import pandas
df = pandas.DataFrame(news_total)
df.head(10)
最后附上完整代码:
import requests
from bs4 import BeautifulSoup
import re
import pandas
import json
url = 'https://interface.sina.cn/news/get_news_by_channel_new_v2018.d.html?cat_1=51923&show_num=27' \
'&level=1,2&page=2&callback=newsloadercallback&_=1573644439863'
commentURL = 'https://comment.sina.com.cn/page/info?version=1&'\
'format=json&channel=gj&newsid=comos-{}&group=0&compress=0&ie=utf-8&oe=utf-8&page=1&'\
'page_size=3&t_size=3'
newurl = 'https://news.sina.com.cn/w/2019-11-13/doc-iihnzahi0501417.shtml'
def getCommentCounts(newurl):
m = re.search('doc-i(.+).shtml',newurl)
newsid = m.group(1)
comments = requests.get(commentURL.format(newsid))
jd = json.loads(comments.text.strip('var data='))
return jd['result']['count']['total']
def getNewsDetail(newurl):
result={}
res = requests.get(newurl)
res.encoding='utf-8'
soup = BeautifulSoup(res.text,'html.parser')
result['title'] = soup.select('.main-title')[0].text
result['time'] = soup.select('.date-source')[0].contents[1].text
result['article'] = ' '.join([p.text.strip()for p in soup.select('#article p')[:-2]])
result['editor'] = soup.select('.show_author')[0].text.strip('责任编辑:')
result['comments'] = getCommentCounts(newurl)
return result
def parseListLinks(url):
newsdetails = []
res = requests.get(url)
jd = json.loads(res.text.lstrip('newsloadercallback(').rstrip(');'))
for ent in jd['result']['data']:
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails
news_total = []
for i in range(1,10):
newurl = url.format(i)
newsary = parseListLinks(newurl)
news_total.extend(newsary)
df = pandas.DataFrame(news_total)
df.head(10)
将文章保存到MySQL
关于数据库创建:https://blog.csdn.net/zql200008/article/details/103730755
import pymysql
import pandas as pd
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
passwd='200801',
db='taobao',
charset="utf8"
)
cur = conn.cursor()
df = pd.read_csv("D:/PycharmProjects/untitled/new.csv", encoding='gbk')
data = []
try:
print("数据正在进行保存")
for value in df.values:
data.append(tuple(value))
sql = 'insert into new values("%s","%s","%s","%s","%s","%s")'
cur.executemany(sql,data)
conn.commit()
except:
print("数据插入异常")
finally:
print("数据保存完成")
cur.close()
conn.close()
文章学自:https://study.163.com/course/courseMain.htm?courseId=1003285002
