爬取到网页的详细三级目录导航:重点只在于获取DOM节点
初学python 代码有点难看:先贴代码再分析网页
#!/usr/bin/env python
# -*- coding:utf-8 -*-
__author__ = 'Lilu'
import os
import re
from bs4 import BeautifulSoup
from html.parser import HTMLParser
from urllib import request
import sys
import itertools
import mysql.connector
from datetime import datetime
# 这是引入自己写的JournalismText模板:用于解析正文并下载图片,然后过滤正文中的class以及style,id等敏感词汇,
sys.path.append(r'E:\Python\cocn\venv\Demo')
import JournalismText
url = 'http://news.sina.com.cn/world/'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,'
' like Gecko) Chrome/50.0.2661.94 Safari/537.36'}
target_req = request.Request(url=url, headers=header)
target_response = request.urlopen(target_req, timeout=5)
#将网页的源码html读取出来
target_html = target_response.read().decode('utf-8', 'ignore')
#通过BeautifulSoup来解析读取出来的target_html
soups = BeautifulSoup(target_html, 'lxml')
#解析过后就可以通过选择器进行抓取了
data = soups.select('div[class="wrap"]', limit=1)
soup = BeautifulSoup(str(data), 'lxml')
begin_flag = False
num = 0
#这里就处理爬取出来的内容了
for child in soup.div.children:
# 滤除回车
if child != '\n':
begin_flag = True
# 爬取链接并下载内容
if begin_flag == True and child != None:
if num == 0:
num += 1
continue
# 获取到一级标题名
ch_name = child.string
# 获取到一级标题路径
ch_url = child.get('href')
print(ch_url, '````````````````````````````````````')
dt = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
value = [str(ch_name), ch_url, str(dt)]
# 根据获取到的二级目录的URL再进入二级目录
download_req2 = request.Request(url=ch_url, headers=header)
download_response2 = request.urlopen(download_req2)
# 读取二级目录内容
download_html2 = download_response2.read().decode('utf-8', 'ignore')
# 解析
soups1 = BeautifulSoup(download_html2, 'lxml')
# 利用select选择器抓取节点
data1 = soups1.select('div[class="links"]', limit=1)
print(data1)
soup1 = BeautifulSoup(str(data1), 'lxml')
begin_flag1 = False
for child1 in soup1.div.children:
# 滤除回车
if child1 != '\n':
begin_flag1 = True
# 爬取链接并下载内容
if begin_flag1 == True and child1 != None:
# 获取到一级标题名
ch_name1 = child1.string
# 获取到一级标题路径
ch_url1 = child1.get('href')
dt = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
value = [str(ch_name1), ch_url1, str(ch_name), str(dt)]
for i in value:
print(type(i))
#获取新闻详情列表
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,'
' like Gecko) Chrome/50.0.2661.94 Safari/537.36'}
# 根据爬取出来的详情列表URL 再去请求
download_req3 = request.Request(url=ch_url1, headers=header)
download_response3 = request.urlopen(download_req3)
# 读取出详情页URL
download_html3 = download_response3.read().decode('gbk', 'ignore')
# 解析成可选择对象
soups = BeautifulSoup(download_html3, 'lxml')
# 抓住URL
da = soups.find_all('div', class_='listBlk')
soup = BeautifulSoup(str(da), 'lxml')
begin_flag2 = False
# 处理好URL格式
for child2 in soup.ul.children:
# 滤除回车
if child2 != '\n':
begin_flag2 = True
# 爬取链接并下载内容
if begin_flag2 == True and child2.a != None:
child_name = child2.a.string
child_url = child2.a.get('href')
chid_time = child2.span.string
print(child_name, child_url, chid_time)
dt = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
value = [str(child_name), child_url, str(chid_time),
# 获取详情
# 将URL传入JournalismText模板 解析正文
lis = JournalismText.getJournalismText(child_url, child_name)
JournalismText 模板:
#! usr/bin/env python3
# -*- coding:utf-8 -*-
__author__ = 'Lilu'
import os
import re
from bs4 import BeautifulSoup
from html.parser import HTMLParser
from urllib import request
import pandas
import mysql.connector
from datetime import datetime
import urllib.request
def getJournalismText(url, child_name):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,'
' like Gecko) Chrome/50.0.2661.94 Safari/537.36'}
target_req = request.Request(url=url, headers=header)
target_response = request.urlopen(target_req, timeout=5)
target_html = target_response.read().decode('utf-8', 'ignore')
# 解析获取到的target_html
datas = BeautifulSoup(target_html, 'html.parser')
# 获取包裹正文的div
data = datas.select('div[class="article"]', limit=1)
# 获取包含图片的标签
dataimg = datas.select('div[class="img_wrapper"]')
# 利用正则将图片的URL取出来进行格式化并下载到本地
reg = r'(http:[^\s]*?(jpg|png|gif))'
imgre = re.compile(reg)
imglist = imgre.findall(str(dataimg))
num = 1
l = []
for img, t in imglist:
s = str(img).split('/')
name = s.pop(),
f = open('D:/Workspaces/MyEclipseProfessional2014/imageStatic/img/%s' %name, 'wb')
l.append('D:/Workspaces/MyEclipseProfessional2014/imageStatic/img/%s' %name)
req = urllib.request.urlopen(img)
buf = req.read()
f.write(buf)
num += 1
# 修改掉文中的图片路径
for i in range(len(dataimg)):
img = dataimg[i].select('img')[0]
for a in range(len(l)):
if i == a:
img.attrs['src'] = l[a]
# 过滤掉文中的class字样
text = str(data)
re_class = re.compile('class=(\"[^><]*\")')
text = re_class.sub("", text)
# 获取标题
title = datas.select('h1')[1].text.strip()
# 获取时间
nt = datas.select('.date')[0].contents[0].strip()
newsAr = getnewsArticle(datas.select('p')[:-4])
newsArticle = newsAr[-1]
dt = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
value = [title, "".join(text), nt, newsArticle, str(child_name), str(dt)]
for i in value:
print(i)
return value
def getnewsArticle(news):
newsArticle = []
for p in news:
newsArticle.append(p.text.strip())
return newsArticle满满的干货完全可以copy:
图解:
1,第一步:获取的第一级中的div并迭代出其中的a标签的值和URL
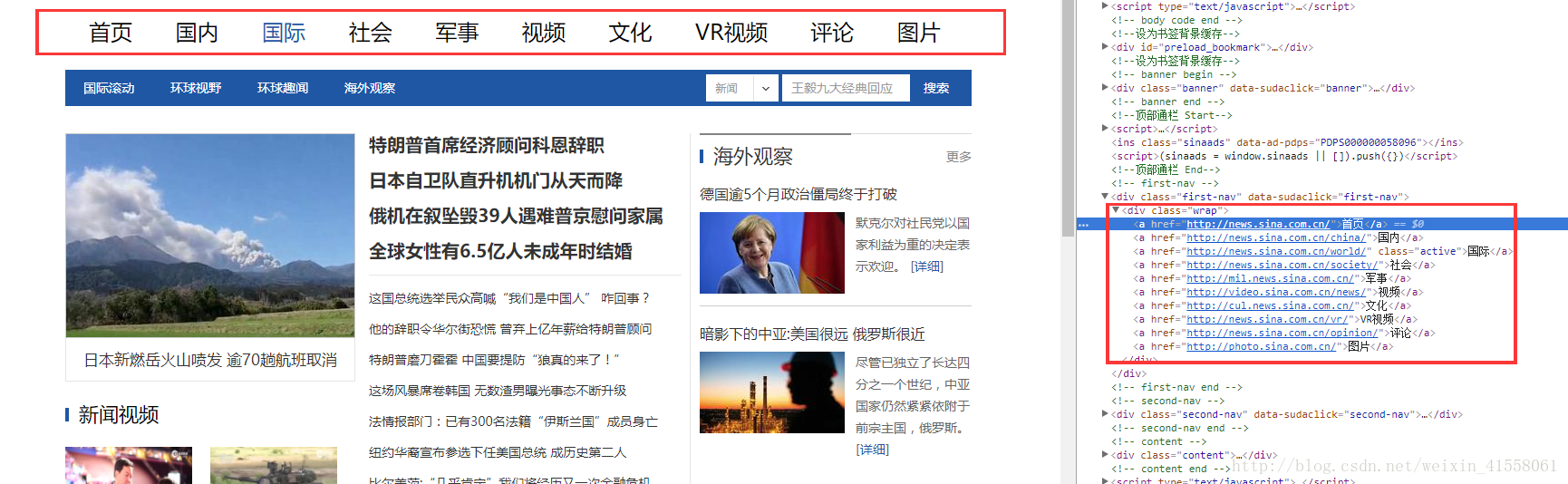
2,第二步:根据第一步获取的URL来获取每一个的二级菜单:获取其中的(同上)
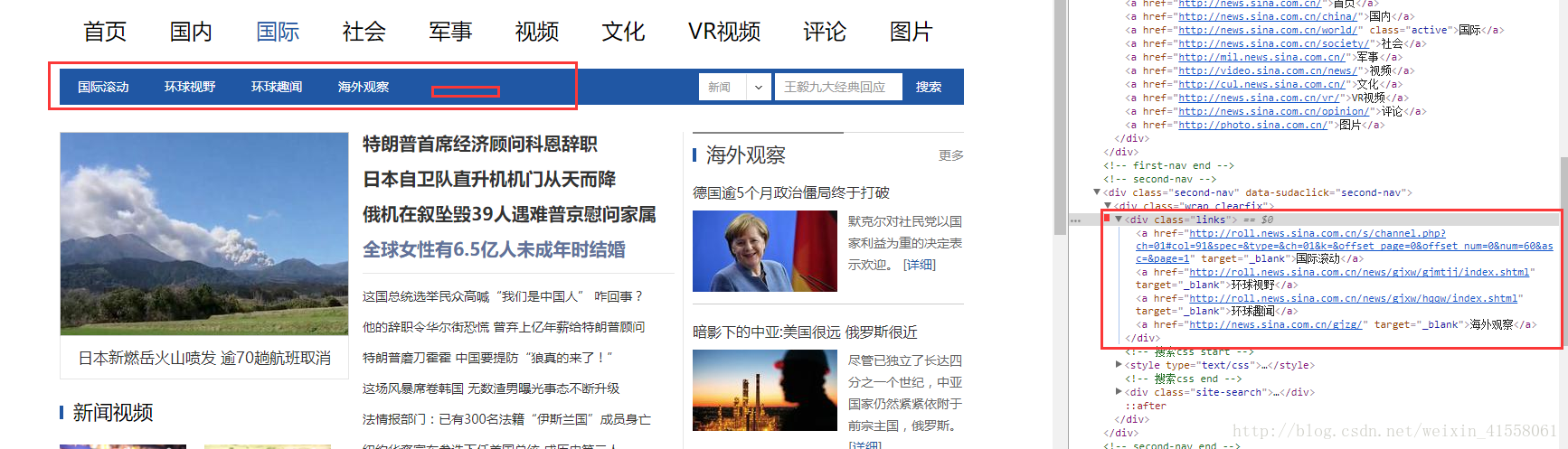
3,第三步:根据第二步获取的URL来获取每一个的列表菜单:获取其中的(同上)
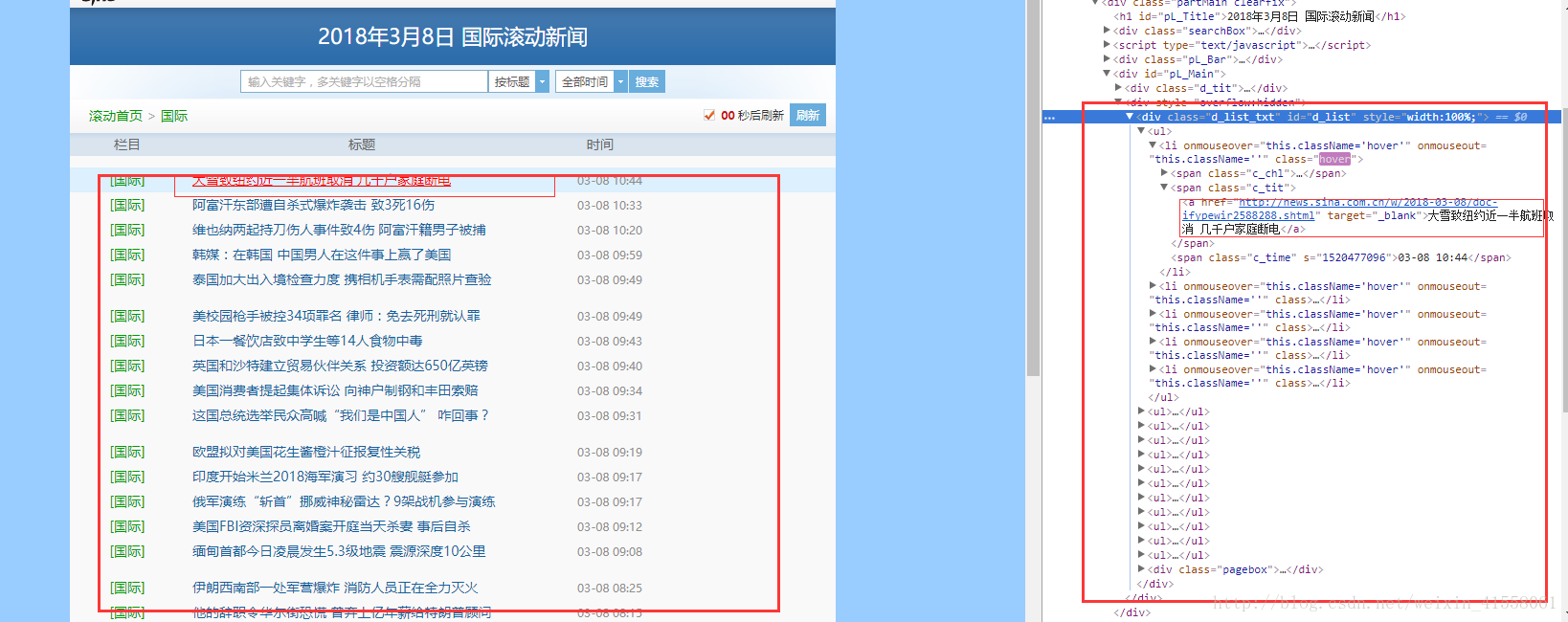
4,第四步:根据第三步获取的URL来获取每一个的列表菜单的正文:这下就到底了
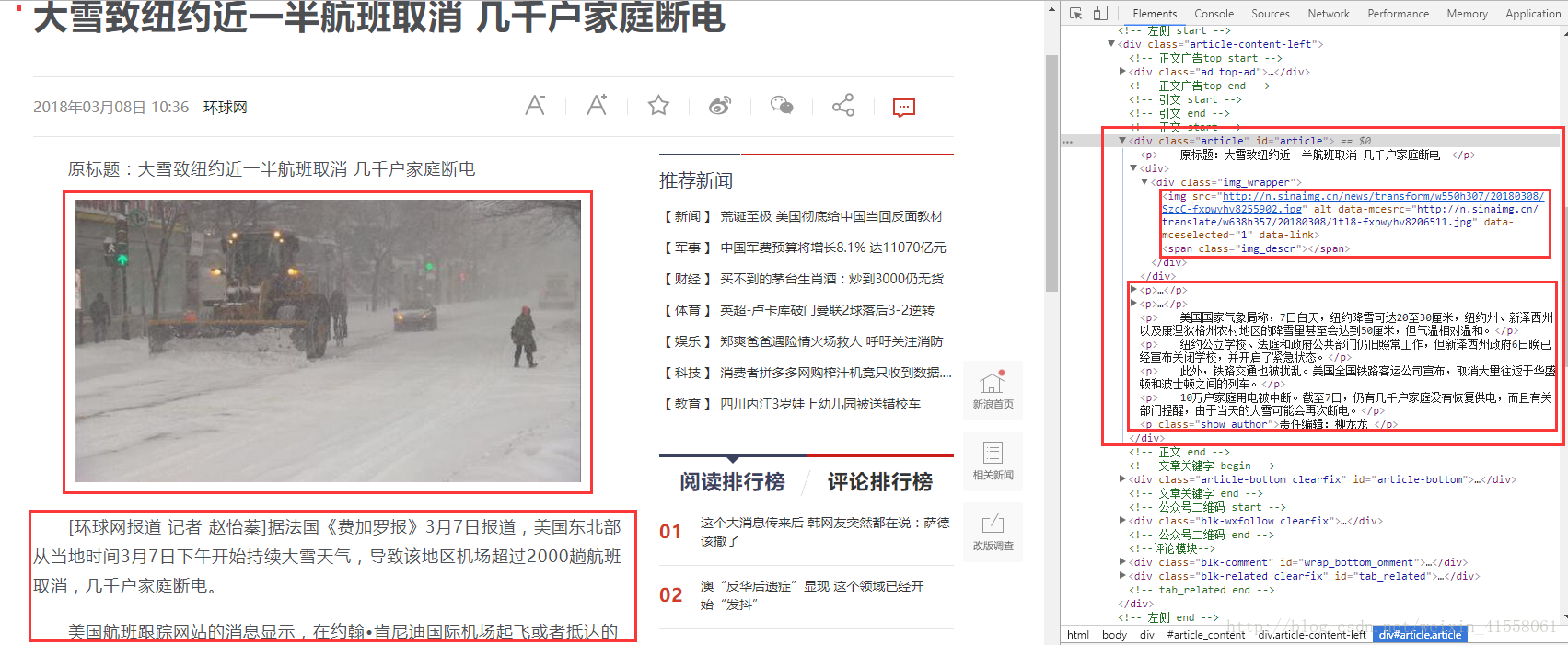
心得:就是要获取到相关的节点然后通过python的库来解析,其中的数据类型一定要熟悉