首先我带大家先分析一下新浪网站的整体布局,爬取的内容从新浪网的导航页开始逐层爬取内容,这是新浪网导航页的网址http://news.sina.com.cn/guide/,先带大家看一下新浪网的导航页的页面布局。

我们看到新浪网的导航分类,是新闻的标题下面还设置小标题,如新闻下面包括国内、国际、社会等等,点击国内就会进入页面详情,每一条新闻都会呈现在大家面前,点击新闻详情的链接就如进入到每条新闻的详情页,所有的内容和标题都会展现出来。其次新浪网没有设置反爬虫,大家基本上不用设置user_agent或cookies等信息。此次案例采用的是scrapy爬虫框架,下面的案例的代码部分。
首先在items注册字段
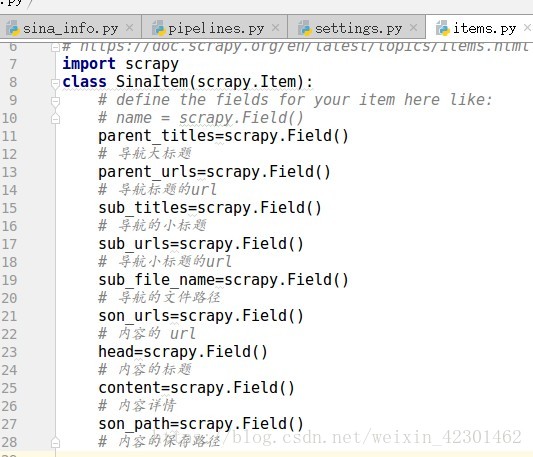
其次在爬虫的文件如写入爬取内容的类
import scrapy
import os
from Sina.items import SinaItem
class SinaInfoSpider(scrapy.Spider):
name = 'sina_info'
allowed_domains = ['sina.com.cn']
start_urls = ['http://news.sina.com.cn/guide/']
def parse_detail(self,response):
"""解析帖子的数据"""
item = response.meta["item"]
#帖子链接
item["son_url"] = response.url
heads = response.xpath('//h1[@class="main-title"]/text()|//div[@class="blkContainerSblk"]/h1[@id="artibodyTitle"]/text()').extract()
head = "".join(heads)
#把节点转换成unicode编码
contents = response.xpath('//div[@class="article"]/p/text()|//div[@id="artibody"]/p/text()').extract()
content = "".join(contents)
item["content"] = content
item["head"] = head
yield item
#解析第二层的方法
def parse_second(self,response):
#得到帖子的链接
# print("parse_second--response.url====", response.url)
son_urls = response.xpath('//a/@href').extract()
item = response.meta["item"]
parent_url = item["parent_url"]
# print("item====",item)
for url in son_urls:
#判断当前的页面的链接是否属于对应的类别
if url.startswith(parent_url) and url.endswith(".shtml"):
#请求
yield scrapy.Request(url, callback=self.parse_detail, meta={"item": item})
def parse(self, response):
# print("response.url====",response.url)
#所以的大标题
parent_titles = response.xpath('//h3[@class="tit02"]/a/text()').extract()
# 大标题对应的所以的链接
parent_urls = response.xpath('//h3[@class="tit02"]/a/@href').extract()
#所有小标题
sub_titles = response.xpath('//ul[@class="list01"]/li/a/text()').extract()
#所以小标题对应的链接
sub_urls = response.xpath('//ul[@class="list01"]/li/a/@href').extract()
items = []
for i in range(len(parent_titles)):
#http://news.sina.com.cn/ 新闻
parent_url = parent_urls[i]
parent_title = parent_titles[i]
for j in range(len(sub_urls)):
#http://news.sina.com.cn/world/ 国际
sub_url = sub_urls[j]
sub_title = sub_titles[j]
#判断url前缀是否相同,相同就是属于,否则不属于
if sub_url.startswith(parent_url):
#装数据
item = SinaItem()
# print("parent_url===",parent_url)
# print("sub_url===", sub_url)
#创建目录
sub_file_name = "./Data/"+parent_title+"/"+sub_title
if not os.path.exists(sub_file_name):
#不存在就创建
os.makedirs(sub_file_name)
item["parent_url"] = parent_url
item["parent_title"] = parent_title
item["sub_url"] = sub_url
item["sub_title"] = sub_title
item["sub_file_name"] = sub_file_name
items.append(item)
#把列表的数据取出
for item in items:
sub_url = item["sub_url"]
#meta={"item":item} 传递item引用SinaItem对象
yield scrapy.Request(sub_url,callback=self.parse_second,meta={"item":item})
再写保存文件的类,写到Pipeline
import json
class SinaPipeline(object):
def open_spider(self,spider):
# 'son_urls': 'http://sports.sina.com.cn/china/j/2018-07-11/doc-ihfefkqq5317948.shtml'
# file=item['son_urls'][7:-6].replace('/','_')
self.file=open(spider.name+'.json','w',encoding='utf-8')
print('========================',self.file)
def process_item(self, item, spider):
sub_file_name=item['sub_file_name']
content=item['content']
if len(content)>0:
son_urls=item['son_urls']
file_name=son_urls[7:son_urls.rfind('.')].replace('/','.')
file_path=sub_file_name+'/'+file_name+'.txt'
with open(file_path,'w',encoding='utf-8') as f:
f.write(content)
item['son_path'] =file_path
dict_item=dict(item)
content=json.dumps(dict_item,ensure_ascii=False)+'\n'
self.file.write(content)
return item
def close_spider(self,spider):
self.file.close()
最后创建一个start.py 文件将命令行写到文件中
from scrapy import cmdline
cmdline.execute('scrapy crawl sina_info'.split())
这样我们就可以运行start.py文件,项目就能跑起来了,开始爬取新浪网站的数据了


最后我们就能看到所有新浪网站的新闻都会被逐条保存到文件中了