pandas.DataFrame的groupby()方法是一个特别常用和有用的方法。让我们快速掌握groupby()方法的基础使用,从此数据分析又多一法宝。
首先导入package:
import pandas as pd import numpy as np
groupby的最基本操作
df = pd.DataFrame({'A':[1,2,3,1],'B':[2,3,3,6],'C':[3,1,5,7]})
df

按照A列来进行分组(其实说白了就是将A列中重复的值和成同一个值,然后把A当成索引来进行重新的数据分组)
df.groupby('A').mean() #mean是取平均值
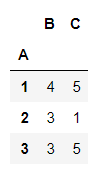
df.groupby('A').sum() #sum是求和

df.groupby(['A']).first() #取第一个出现的数据

df.groupby(['A']).last() #取最后一个出现的数据
扫描二维码关注公众号,回复:
7420641 查看本文章

也可以按照多组进行分组
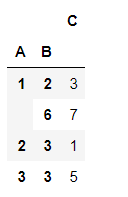
df.groupby(['A','B']).sum()
统计数据的数量
size跟count的区别: size计数时包含NaN值,而count不包含NaN值
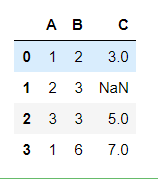
df = pd.DataFrame({'A':[1,2,3,1],'B':[2,3,3,6],'C':[3,np.nan,5,7]})
df
df.groupby(['A']).count()
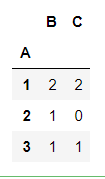
df.groupby(['A']).size()
